组件基于Presto Connector接口规范实现,用来给Presto增加查询HBase的功能。
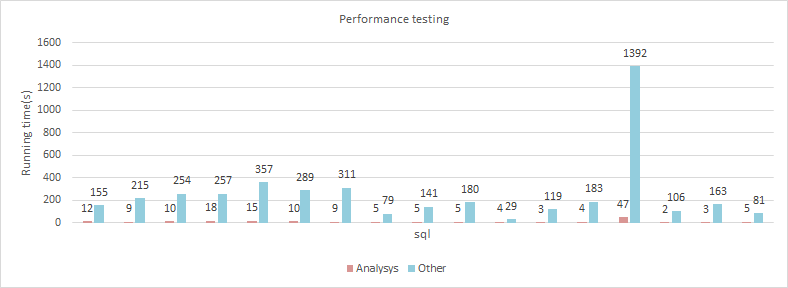
相比其他开源版本的HBase Connector,我们的性能要快10到100倍以上。
| 环境 | 明细 |
|---|---|
| 数据量 | 事件表500万条数据,90个字段 |
| 节点数 | 3 |
| 硬件 | 16逻辑核 64G内存 4T*2硬盘 |
| 功能点 | 易观 | 其他 |
|---|---|---|
| 加盐查询 | 支持 | 不支持 |
| 拼接StartKey/EndKey | 支持 | 不支持 |
| 批量Get查询 | 支持 | 不支持 |
| 谓词下推(Filter) | 支持 | 不支持 |
| ClientSideScan | 商业版已实现 | 不支持 |
| Insert | 后续支持 | 支持 |
| Delete | 后续支持 | 支持 |
| 建表语句 | 后续支持 | 支持 |
- Mac OS X 或者 Linux
- Java 8 Update 92 或更高 (8u92+), 64-bit.
- Maven 3.3.9+ (编译)
- Presto 0.201+
mvn clean package
在{Presto_Config_Dir}/catalog目录下创建hbase.properties文件。配置完成后同步到所有worker节点。
以下是一个比较简单的配置样例,供大家参考:
connector.name=hbase
zookeeper-quorum=localhost:2181
zookeeper-client-port=2181
hbase-cluster-distributed=true
presto-server-port=8285
random-schedule-redundant-split=false
meta-dir=/etc/presto/chbase
参数说明如下:
-
connector.name
该配置固定设置为hbase
-
zookeeper-quorum
相当于HBase API的hbase.zookeeper.quorum参数
-
zookeeper-client-port
相当于HBase API的hbase.zookeeper.property.clientPort参数
-
hbase-cluster-distributed
相当于HBase API的hbase.cluster.distributed参数
-
presto-workers-name
presto worker的hostname,以英文逗号间隔。
如果split-remotely-accessible配置为false,则该参数可以不设置。
-
presto-server-port
与{Presto_Config_Dir}/config.properties配置文件的http-server.http.port参数
-
random-schedule-redundant-split
Presto默认采用按可用Worker的顺序,依次分配Split的方式调度Split。
这样容易导致多表查询时,第余数个Split集中调度到可用Worker列表开头的几台机器上。
将这个参数设置为true可以改为将第余数个Split随机调度到一个Worker上执行。
-
meta-dir
存放HBase表元数据信息的目录。
完成hbase.properties的配置之后,需要在{meta-dir}目录创建HBase的namespace目录结构
- {meta-dir}目录用来存放表的元数据信息。
- 该目录下,首先按照hbase的namespace名创建目录。
- 每一张表会有一个单独的json文件来保存它的表结构信息,json文件以{表名}.json来命名。
- 不同namespace的表分别存放在各自的namespace目录下。
- default namespace的表直接存放在{meta-dir}目录下。
目录结构的样例如下:
--meta-dir:
--namespace_a:
table_a1.json
table_a2.json
--namespace_b:
table_b1.json
table_b2.json
table_c.json
这个例子中分别定义了namespace_a:table_a1、namespace_a:table_a2、namespace_b:table_b1、namespace_b:table_b2以及default命名空间下的 table_c这5张表。
namespace目录创建完成之后,我们需要配置表结构json文件,下面讲解一下json文件中的属性:
表json:
| 属性名 | 描述 |
|---|---|
| tableName | 表名 |
| schemaName | Namespace |
| rowKeyFormat | RowKey是由哪些字段组成,用英文逗号分隔。字段组成有序。 |
| rowKeySeparator | RowKey字段之间的分隔符,默认是\001 |
| rowKeySaltUpperAndLower | RowKey的盐值范围。上界和下界不能小于0,值之间用英文逗号分隔。例如:0,29 |
| describe | 表格描述 |
| columns | 字段列表 |
columns json:
| 属性名 | 描述 |
|---|---|
| family | 列族名 |
| columnName | 字段名 |
| isRowKey | 是否RowKey |
| type | 字段类型(大小写不敏感): string、int、bigint、double、boolean(用int存储,0代表false,1代表false)、array< string > |
| comment | 字段备注 |
以下是一个简单的json文件示例:
{
"tableName": "t_event_test",
"schemaName": "db_test",
"rowKeyFormat": "xwhat,xwho",
"rowKeySaltUpperAndLower": "0,29",
"describe": "Table for test!",
"columns": [{
"family": "f",
"columnName": "rowkey",
"comment": "Column for test!",
"type": "varchar",
"isRowKey": true
}, {
"family": "f",
"columnName": "xwho",
"comment": "Column for test!",
"type": "varchar",
"isRowKey": false
}, {
"family": "f",
"columnName": "ds",
"comment": "Column for test!",
"type": "varchar",
"isRowKey": false
}],
"rowKeySeparator": "-"
}
根据表的namespace找到它在{meta-dir}中对应的目录,按照上述说明创建以表名命名的json文件。
完成上述步骤之后,接下来需要编译组件jar包
// 下载组件源码
// 使用maven构建组件的jar包
mvn clean package
在{plugin.dir}目录下创建插件目录hbase(目录名称可任意设置)。
将构建好的presto0.20-hbase-{version.num}.jar拷贝到该目录下,并同步到所有的worker节点上。
盐值就是指给每个RowKey增加一组可逆向还原的随机数字作为前缀。这样可以将数据分散到多个region存储,查询时也可以通过多线程并发查找。在presto中就可以利用这个机制将数据切分成多个split并发查找。经过验证,使用盐值可以使性能提升几十倍以上。
在组件中使用盐值需要在json文件中设置以下两个属性:
-
rowKeySaltUpperAndLower
该属性用来定义盐值的数值范围,如果设置为"0,29",则会从00到29依次生成30对startKey和endKey,每一对startKey和endKey会交给一个split去做数据扫描。如下:
(00, 00|) (01, 01|) (02, 02|) ...... (29, 29|) -
rowKeySeparator
RowKey的不同组成部分之间的分隔符,默认是\001
这是指根据RowKey是由哪些字段组成的,以及当前查询的谓词来拼接查询StartKey和EndKey。
例如,当RowKey的构成如下:
xwhat-xwho
而SQL是:
select xwhat, xwho, date, xwhen from t_event_test where xwhat='login' and xwho in ('drew', 'george');
这样就会生成如下两对StartKey和EndKey:
(login-drew, login-drew|)
(login-george, login-george|)
要实现这样的查询优化机制,我们需要配置以下两个参数:
-
rowKeyFormat
定义RowKey是由哪些字段有序组成。以刚才的例子来说,该参数应该配置为"xwhat,xwho"
-
rowKeySeparator
RowKey的不同组成部分之间的分隔符,默认是\001
如果想查看sql具体切分出了哪些split,可以将日志级别设置为info,在server.log中查看。
批量get就是指将所要查询的多个RowKey封装成一个List< Get >,然后请求这个列表以获取数据的查询方式。
这种查询方式使用起来非常便利,可以直接将要查询的RowKey作为等值匹配的查询条件放到SQL中即可。
select * from t_event_test where rk in ('rk1', 'rk2', 'rk3');
当系统解析谓词时,会根据字段名是否与RowKey字段一致判断是否执行这一查询模式。
使用这个查询模式,要求必须在表的json文件中通过isRowKey指定RowKey字段。
注意:因为我们定义的RowKey字段是虚拟字段,所以对它做除等值查询之外的其他类型的查询都是没有逻辑意义的。