| gitea | include_toc |
|---|---|
none |
true |
Experimental Spaces-based paragraph-oriented GUI console replacement. Navigate to it...
A GUI tool to browse current interpreter's state.
Binaries: Windows, Linux, Mac 32-bit.

Red inspector accepts command line arguments:
Red Data Inspector 3-Aug-2022 Use `inspect` function in your scripts by hiiamboris
Syntax: red-inspector [options] [script]
Options:
--version Display program version and exit
-h, --help Display this help text and exit
Usage:
-
As a standalone system browser
When run without arguments, it will open itself at
systemobject. -
As an interactive debug tool
When run with a script pathname, it will evaluate the script and exit.
Script has access to
inspectfunction which will bring up Red Inspector window and you will be able to inspect current evaluation state (including local words of currently evaluated functions). Once window is closed, the script will resume evaluation.
>> ? inspect
USAGE:
INSPECT 'target
DESCRIPTION:
Open Red Inspector window on the TARGET.
INSPECT is a function! value.
ARGUMENTS:
'target [path! word! unset!] "Path or word to inspect."
example.red is a demo script that uses inspect function to inspect it's state.
If you'd rather run Inspector from sources, you'll need the cli library along with spaces & common usual setup. Otherwise use provided binaries.
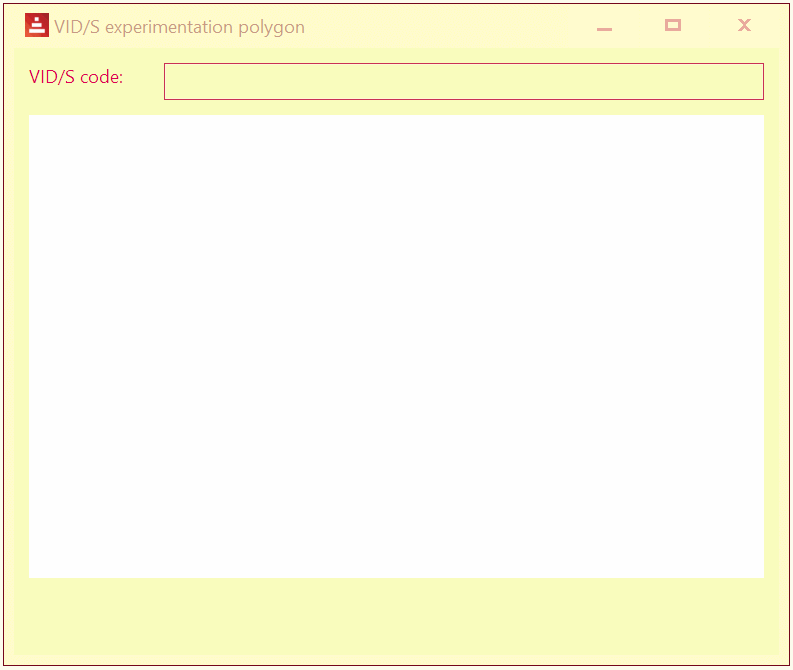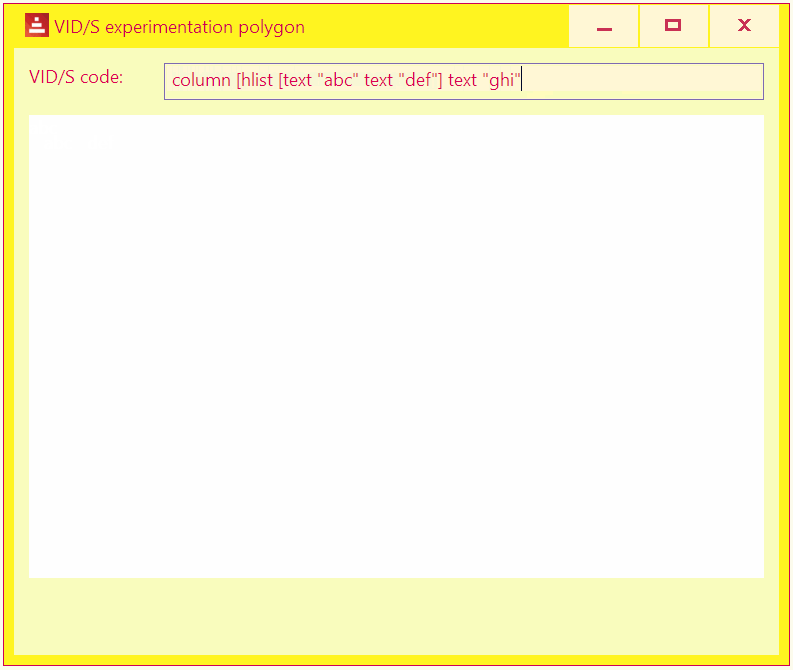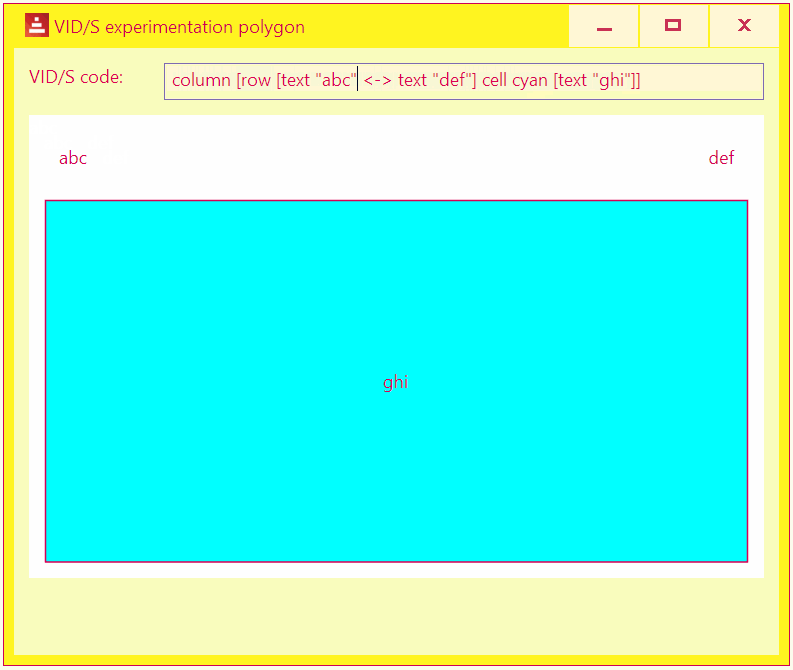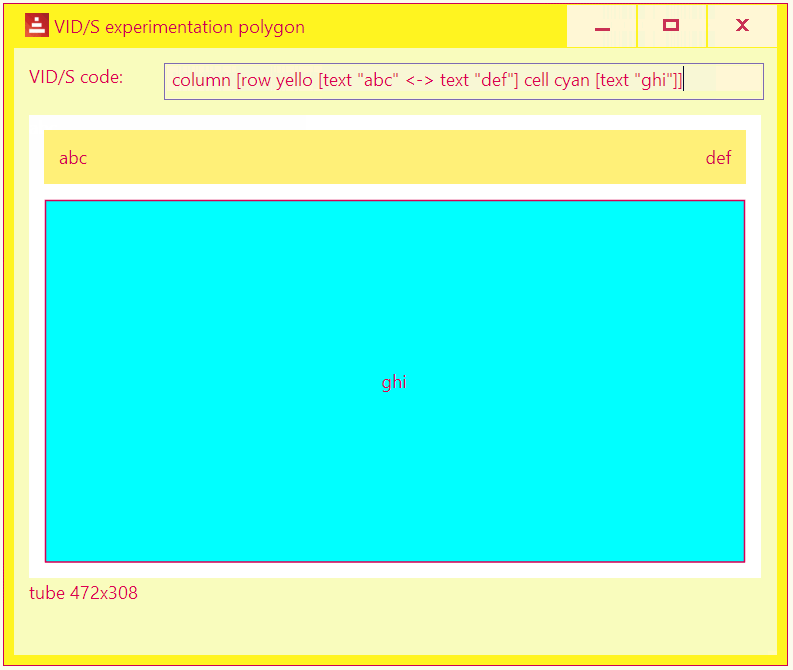
A livecoding tool to experiment with various VID/S layouts.
World's smallest markdown viewer.
Binaries: Windows, Linux, Mac 32-bit.

This tool's main purpose for now is to showcase and test rich content, so:
- it contains only a toy 250-LOC markdown-to-VID/S converter (I may call it a toy, but some webchat implementations do away with worse for years...)
- I didn't bother making a UI for it
- on startup it downloads images from the web painfully slowly (it should be done anynchronously as in browsers, but for now it will at least cache them in
%appdata%\Red\cache) - Red is still crash happy esp. on
reference.md🤷
I have no plan on extending RedMark right now. But my plan for the future:
-
Real markdown parser.
GitHub-flavored markdown has a specification which will be tedious to implement but eventually it's worth it. There's another (likely incompatible) spec, but a better organized one.
I'd like to either have a full GFM-compliant parser, or at least a parser for the most compatible subset of markdown features (so one can write documents more strictly to ensure it works everywhere). Or both parsers, with mode switch.
In addition it should be able to decode HTML tags supported by GFM (spoilers, tables, etc.)
If you'd like to implement this or enhance, PRs are welcome. @rebolek has some parser but it looks unfinished and abandoned. Might be a good starting point for serious parser anyway :)
-
Make it a GUI tool.
I want it to be detect changes in the file and automatically update the view, navigating to the place of last change.
So I could edit markdown file in my text editor and in split-screen see the output rendered. I hate having to push file to the repository only to see if I fixed some typos, and I'd rather use a desktop tool (but all the existing ones are either bloated or have no spoiler or even tables support, and totally no HTML). I don't want to turn RedMark into an editor of it's own.
Line diffing could be added to make it more responsive: it should be able to reconstruct only changed widgets.
-
Markdown template as an optional module for Spaces.
This will be handy for in-program documentation browsing, and RedMark will become even smaller ;)
-
Animated GIFs.
Red has no animated GIF support as of now. Animations can be distracting and hypnotic, and it's likely not a good idea to animate GIFs by default, but I'd like it to be a controllable option.
Mainly a testing GUI for the SVG decoder.
Binaries: Windows

Requires SVG branch of Red. And a lot of compiler workarounds to make a binary ☺
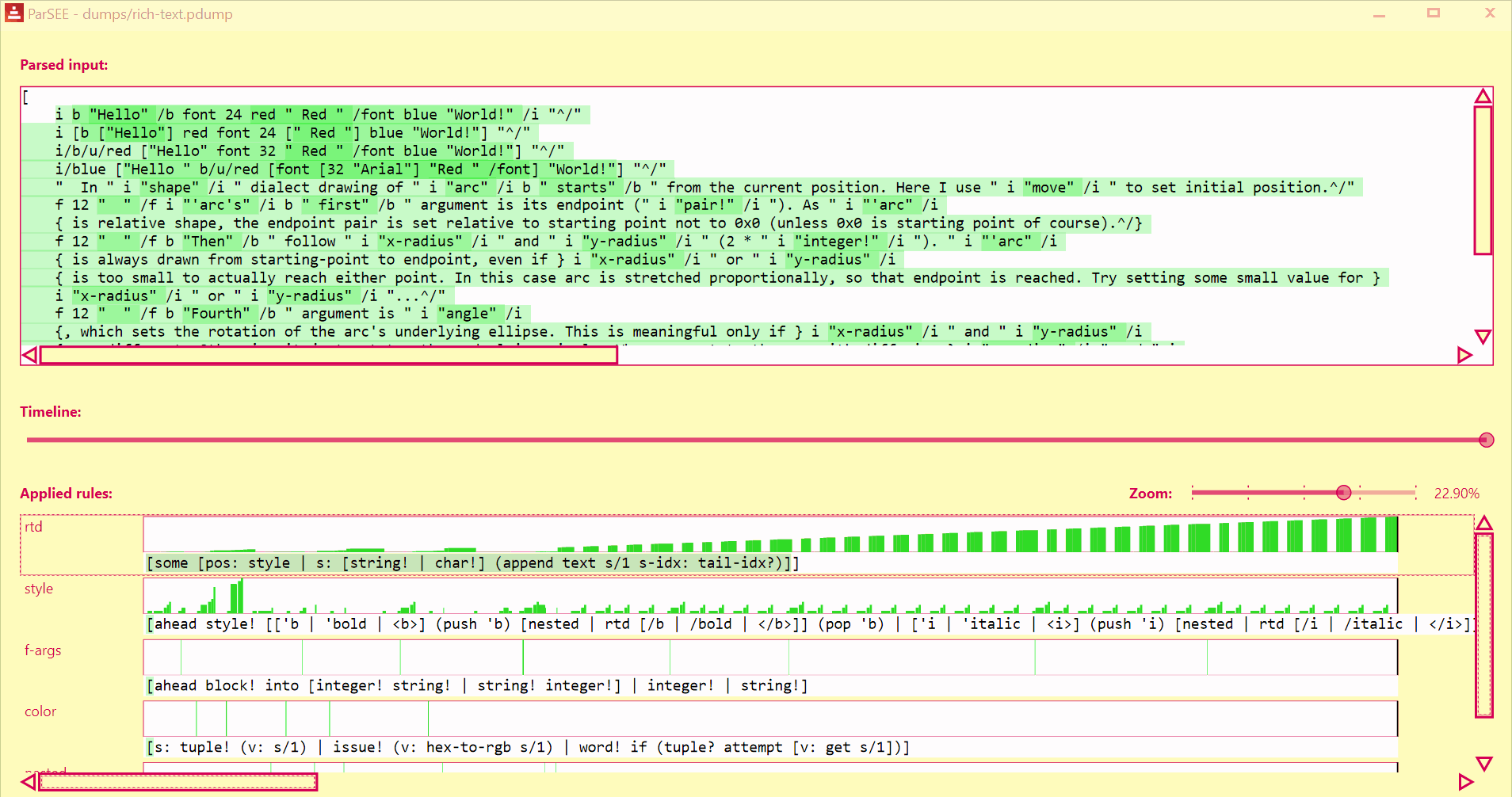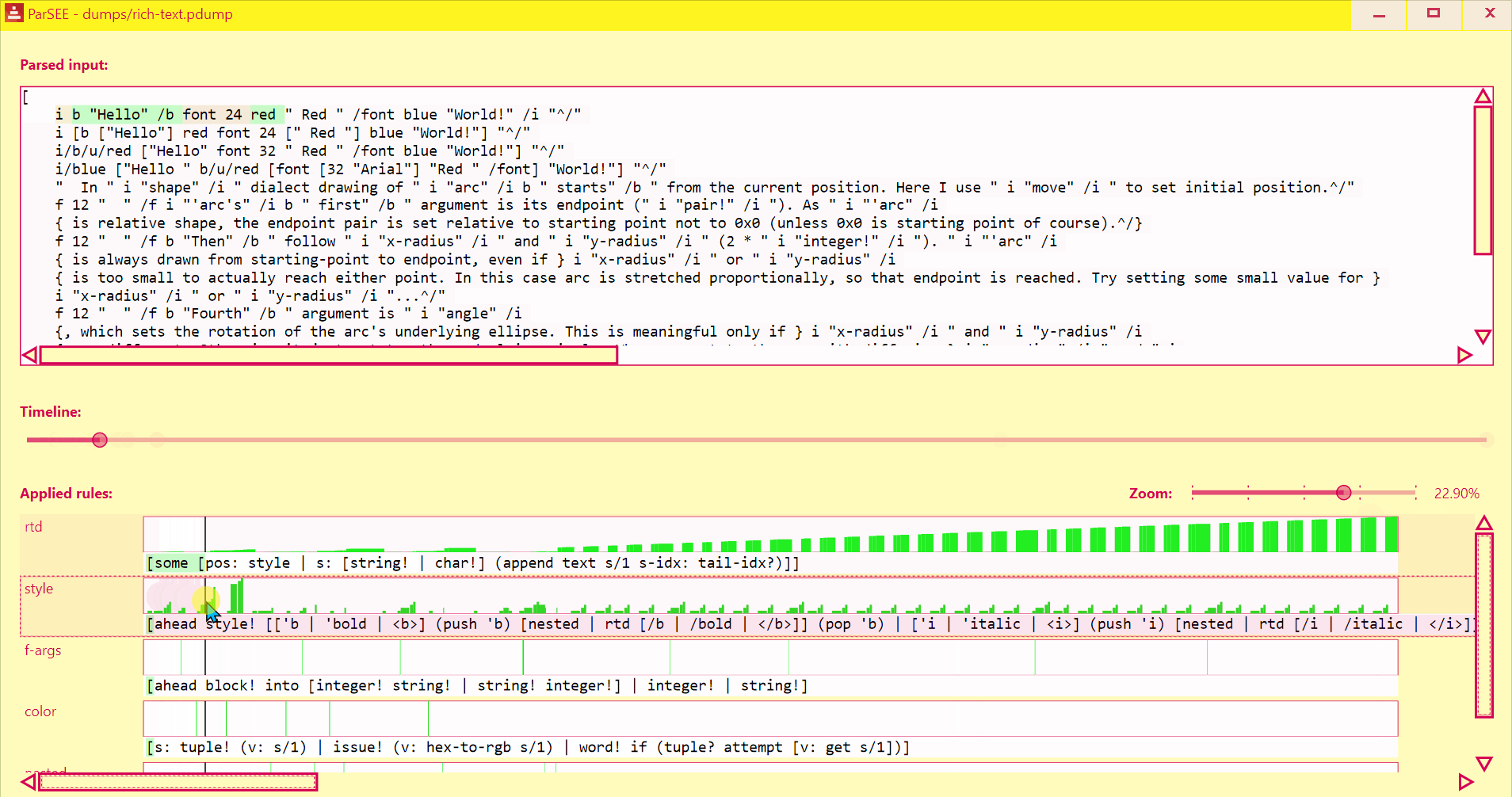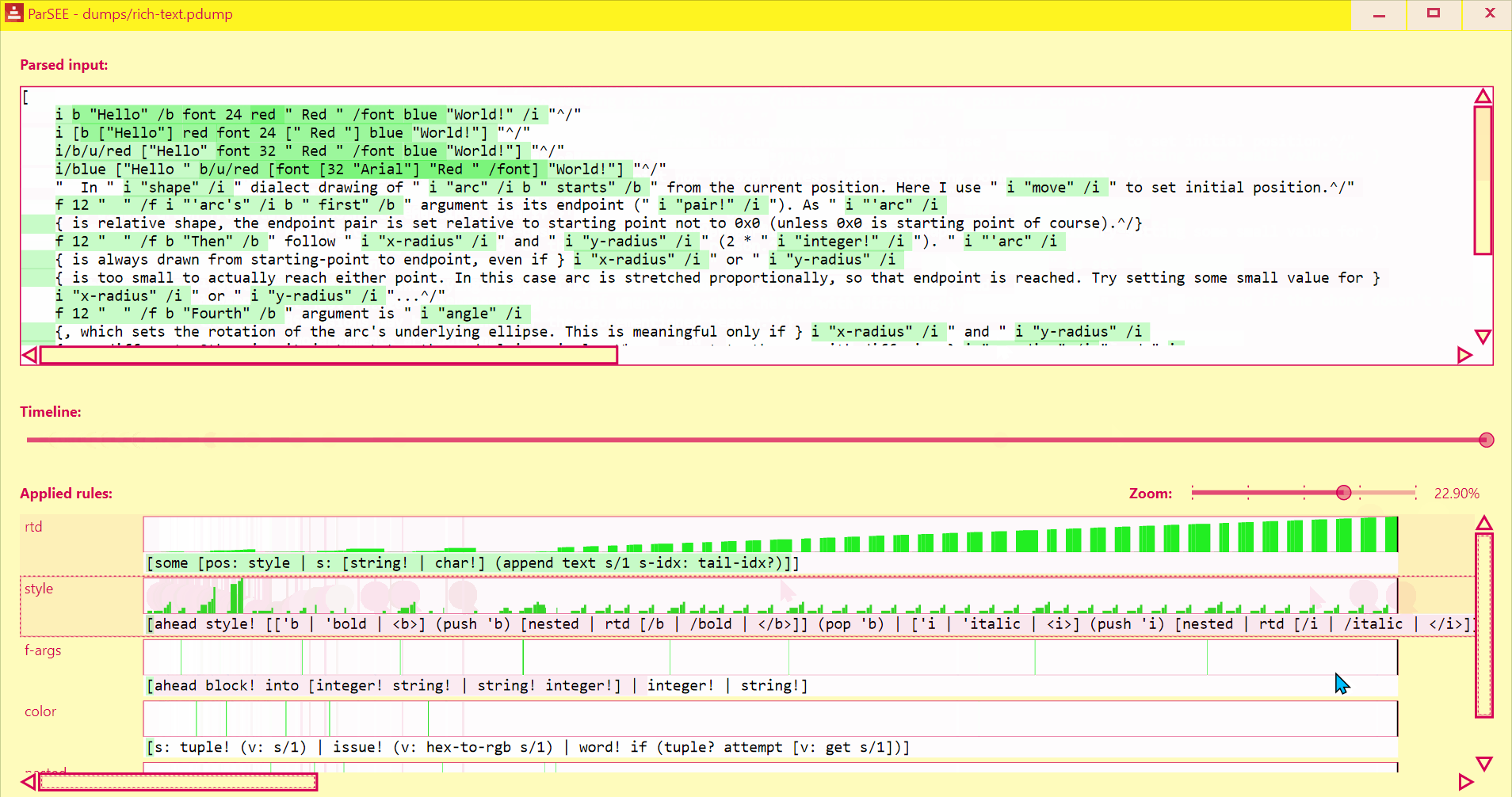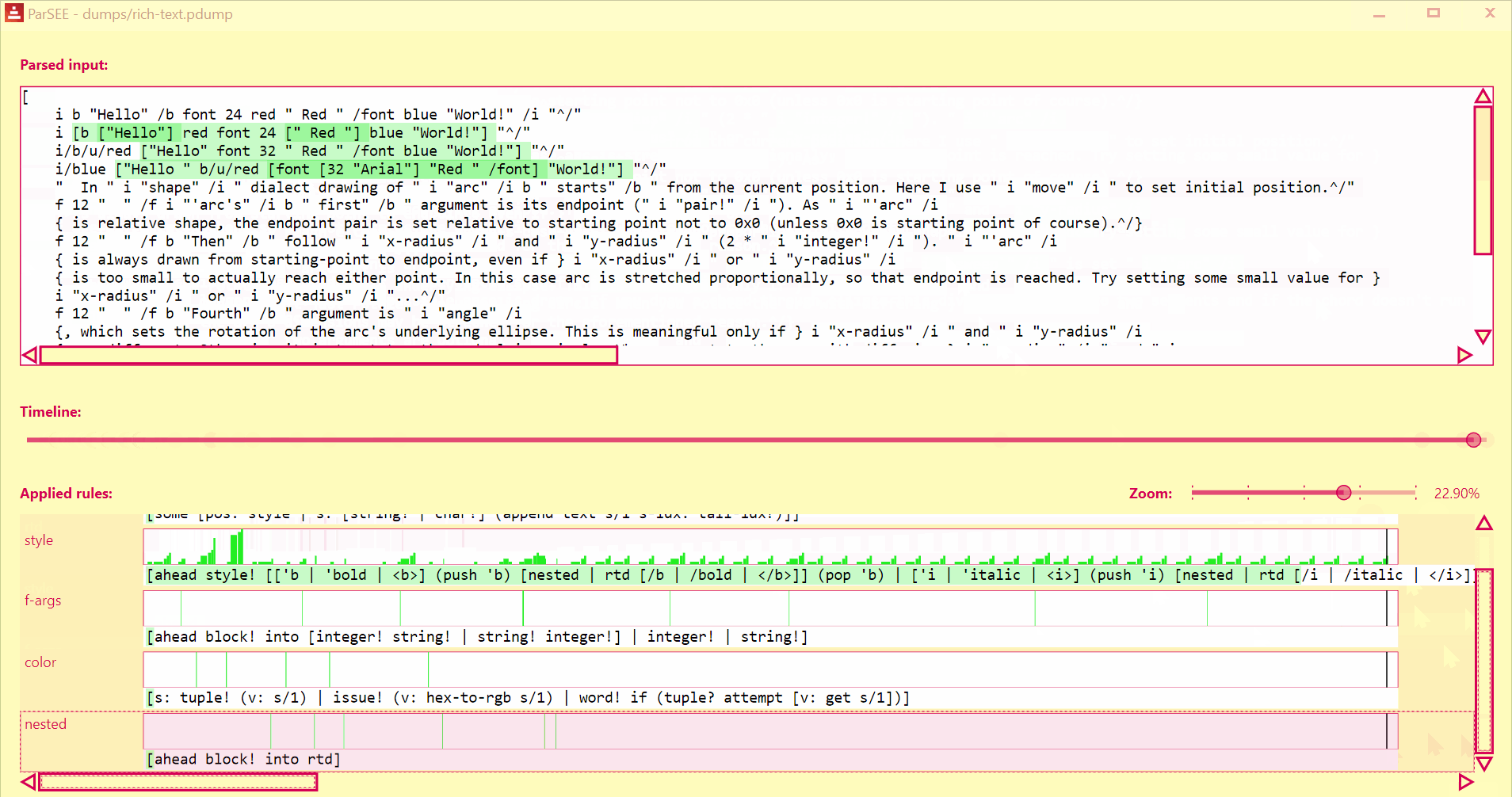
Debug your parse code with ease!
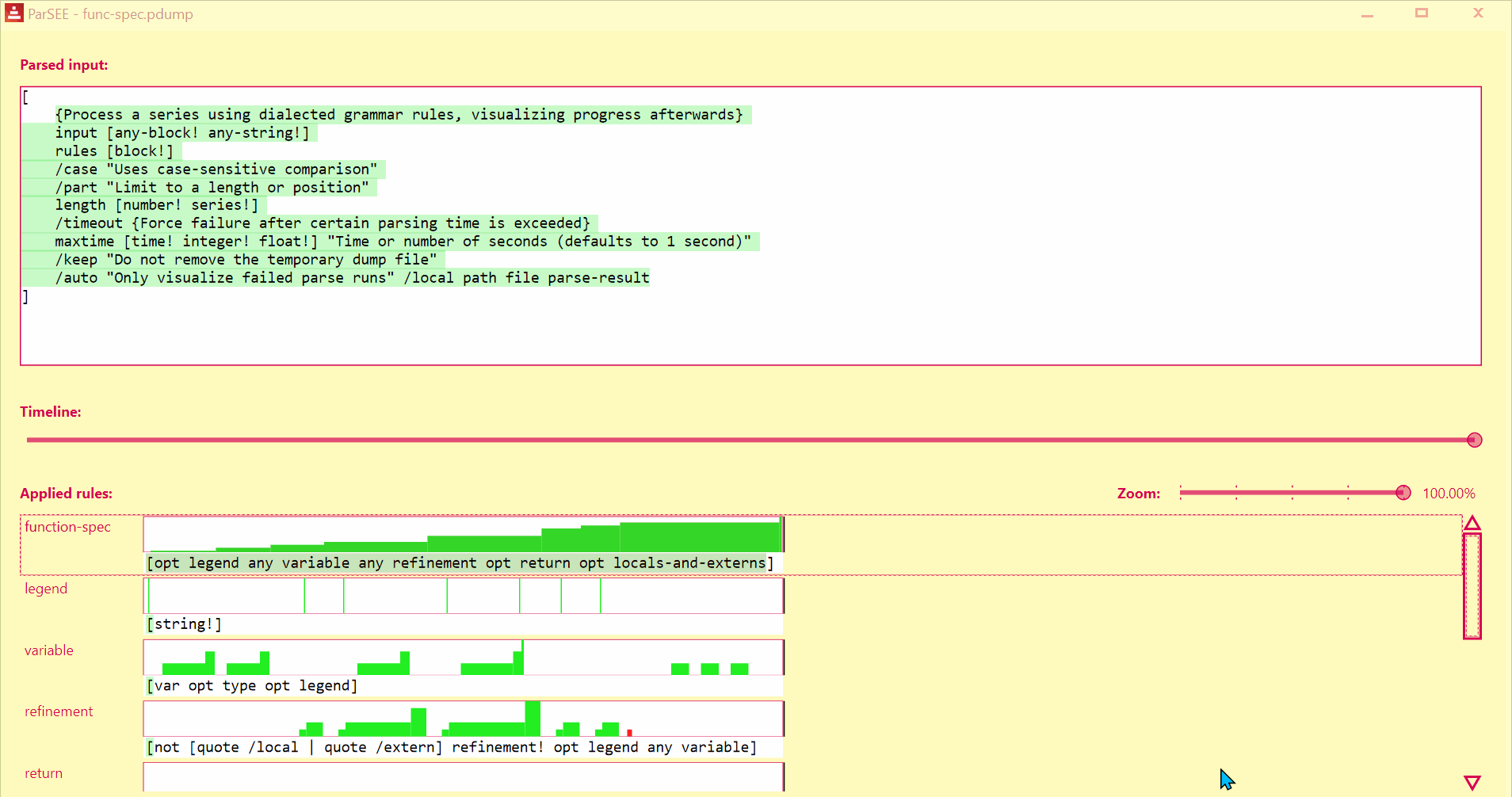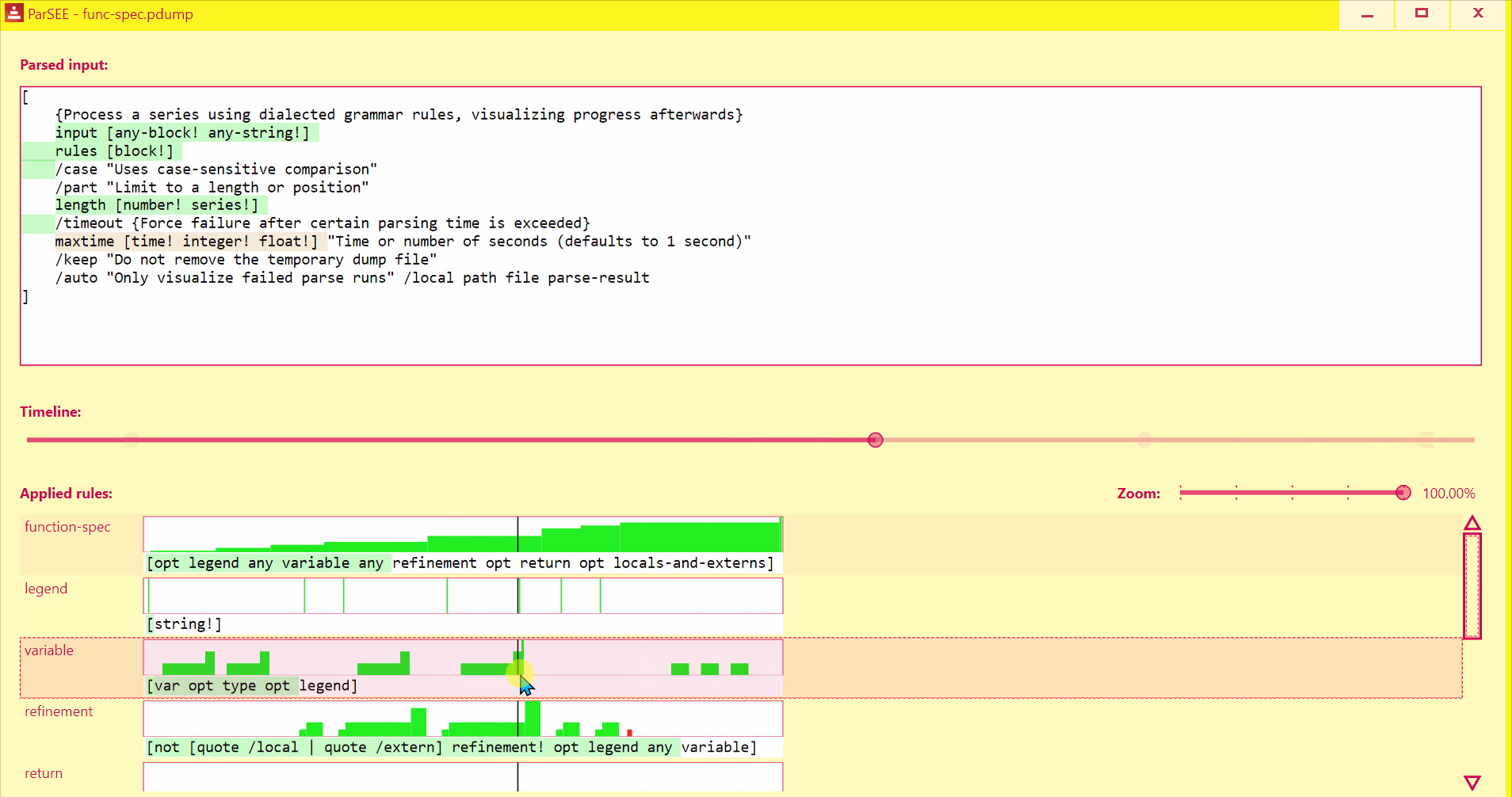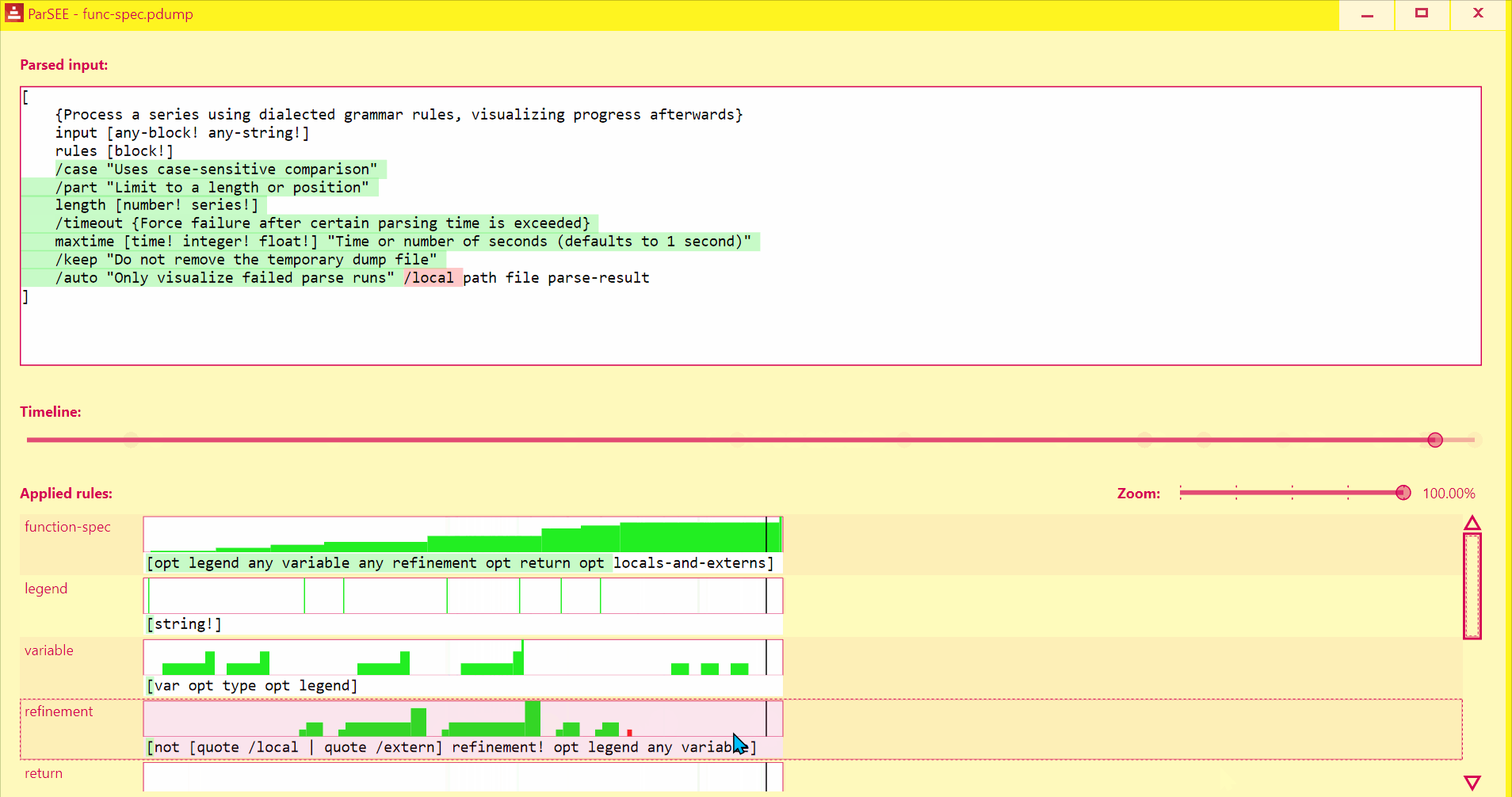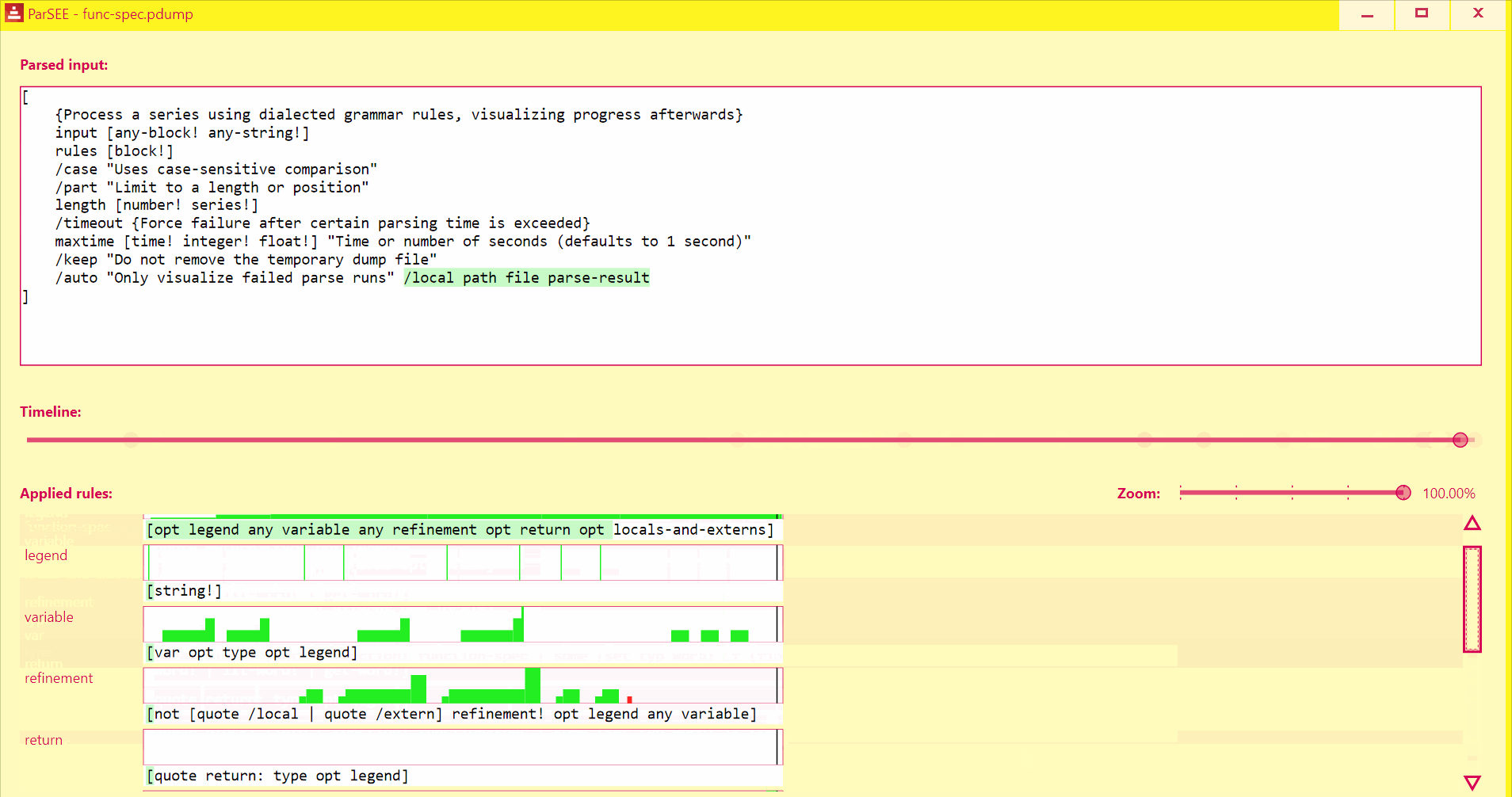
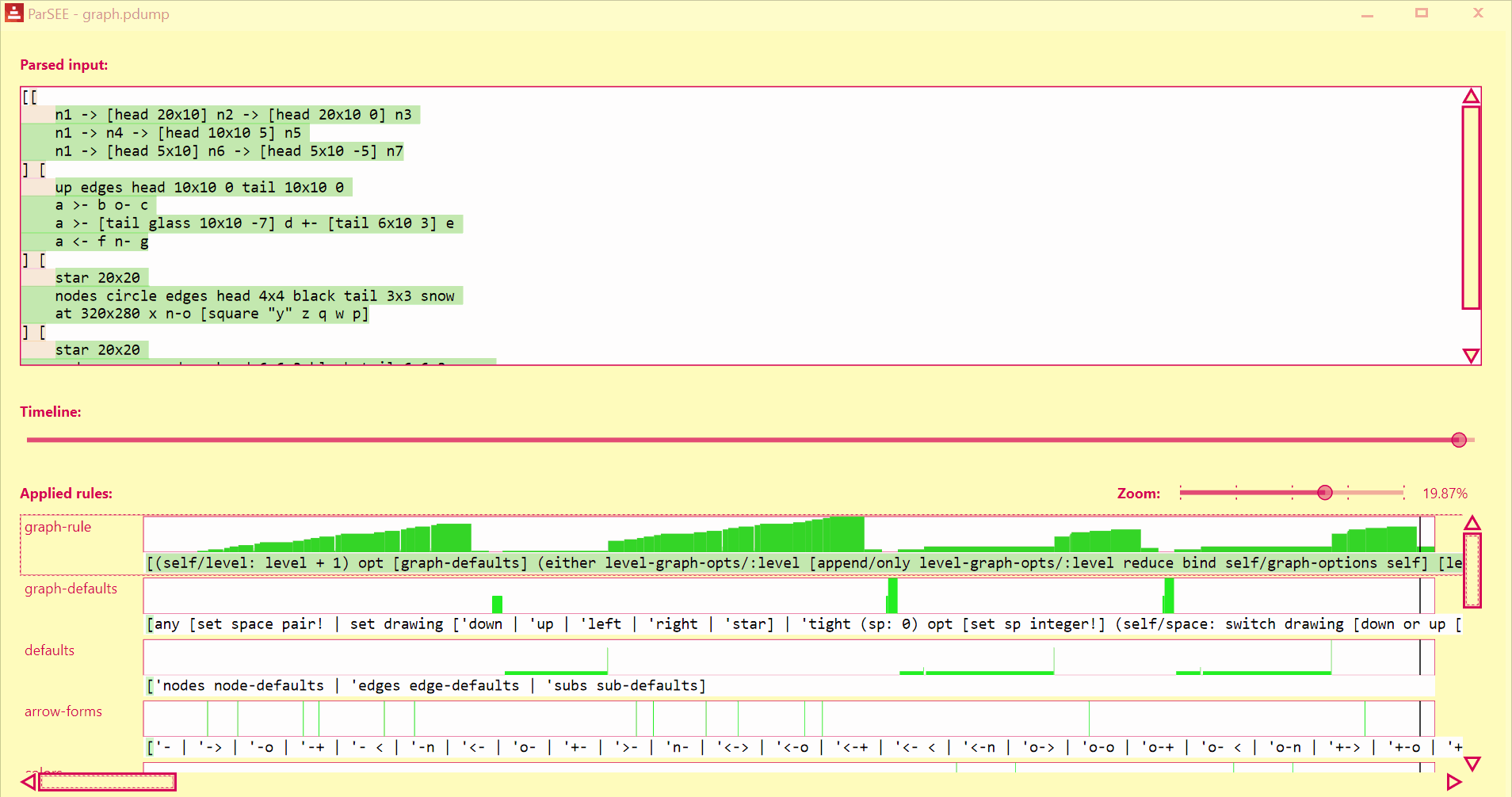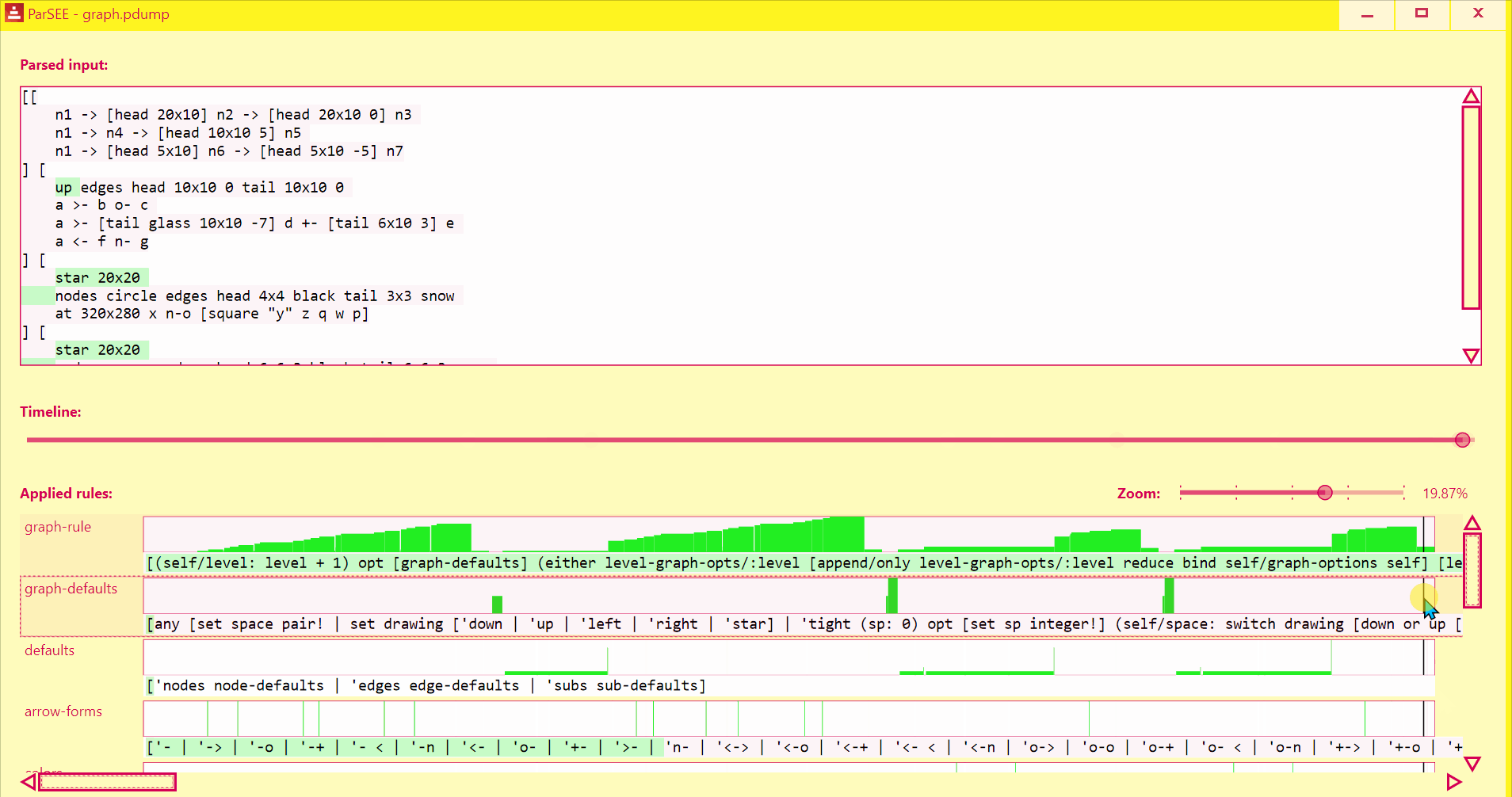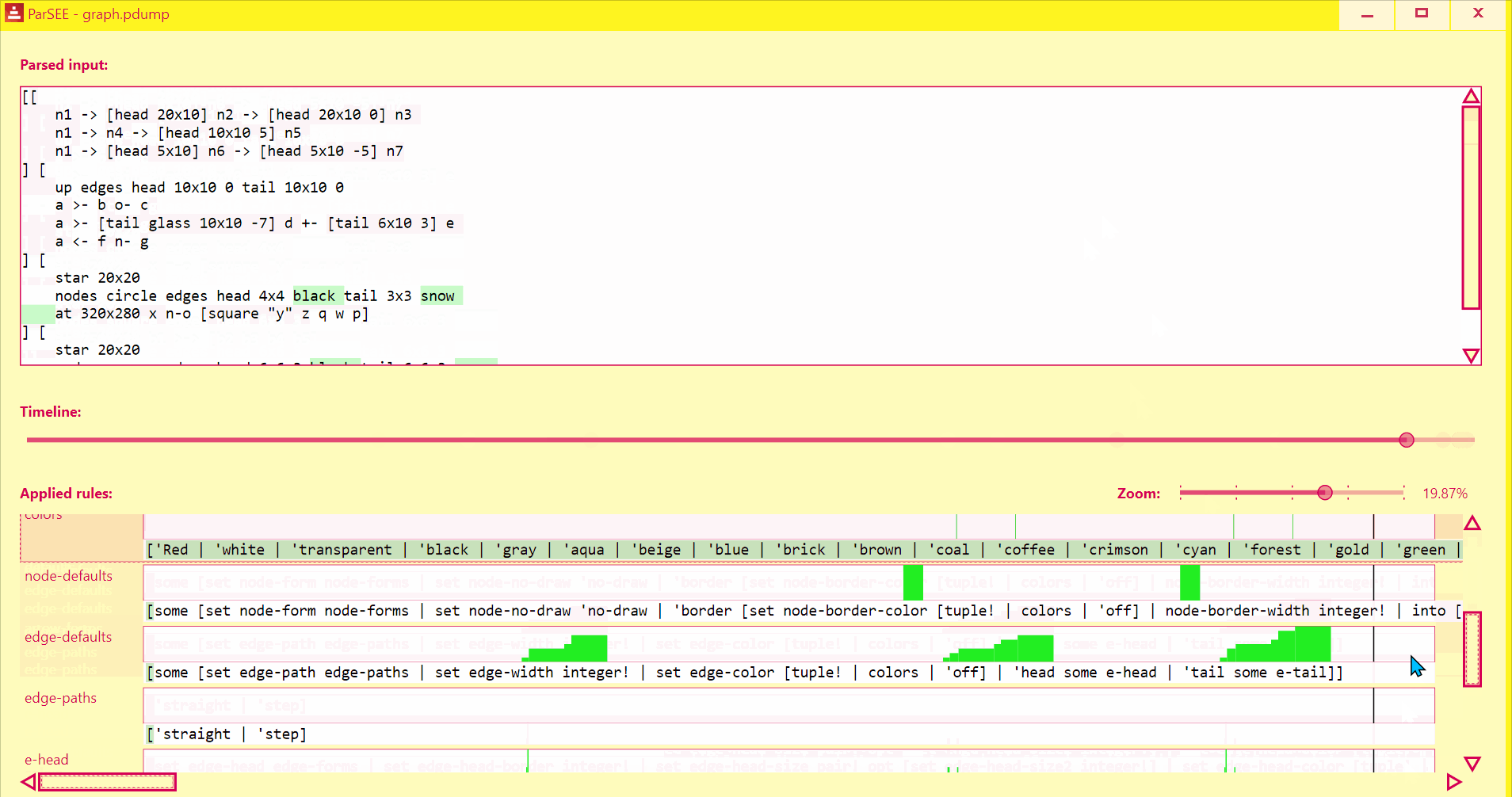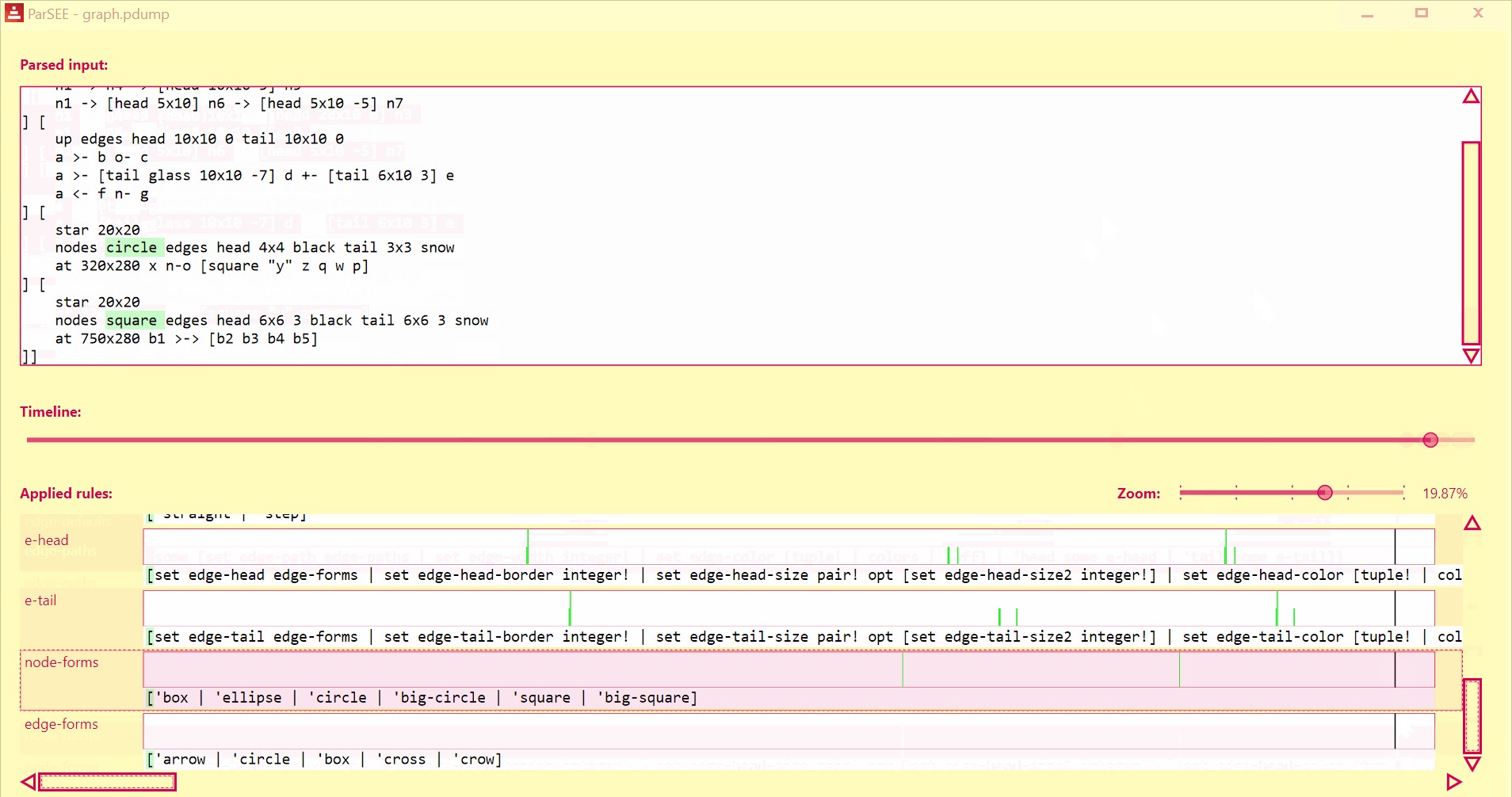
ParSEE allows you to get an almost immediate answer for the questions:
- How far did the parsing reach?
- What rule deadlocks?
- Which rules succeeded, which failed and why?
- Sometimes it also can show double (suboptimal) matching
Real world case studies:
- Failed rule discovery on XML codec's example
- Double matching detection on CSV codec's example
- Overall decoder evaluation on XML codec's example
- TBD: deadlock case (need realistic code for an example; try
parsee "1" [while [opt skip]]for now)
A few examples (clickable):
| Function spec dialect (block) | Rich-text dialect (block) | @toomasv's graph dialect (block) | Red (old) lexer (string) |
|---|---|---|---|
 |
 |
 |
 |
ParSEE UI is Spaces-based, but it would be unwise to require Spaces to be included into every small rule we may wish to debug. For this reason the project is split into two parts:
common/parsee.redbackend that collects info during a Parse run (it replaces nativeparse)spaces/parsee.redSpaces-based frontend that displays and helps analyze it
So to set things up you'll need:
-
As backend either
parsee.redwith all of its dependencies, orparsee-standalone.red(recommended) that has all dependencies included already. Latter option is a result of inlining the former, and is provided because I know how annoying the #include bugs can be.This script, which you'll want to include, contains:
parse-dumpfunction that gathers parsing progress and saves it into a temporary dump fileinspect-dumpfunction thatcalls the frontend to inspect the dumpparseefunction that does both steps at once
-
Compiled frontend binary for your platform: Windows, Linux, MacOS 32-bit
This is the UI that reads the saved dump file. Make this binary available from
PATHasparseeor let the frontend ask you where it is located.
After everything's set up, #include the backend and you should be able play with it in console e.g.:
>> char: charset [#"a" - #"z"]
>> word: [some char]
>> parsee "lorem ipsum dolor sit amet" [some [word opt space]]
You'll see the UI popping up:
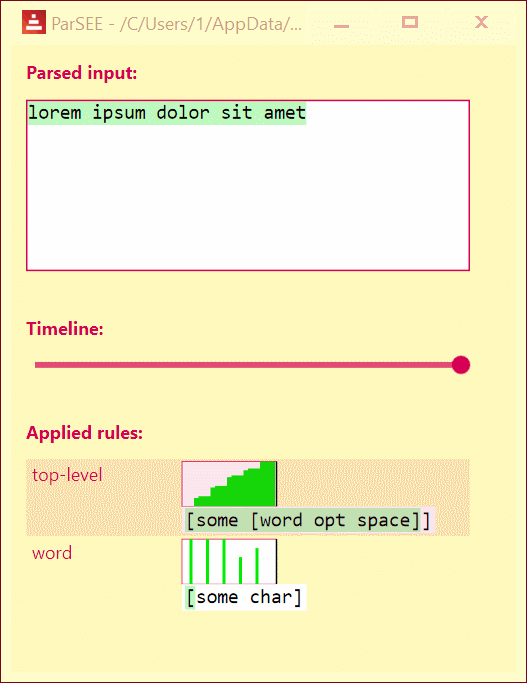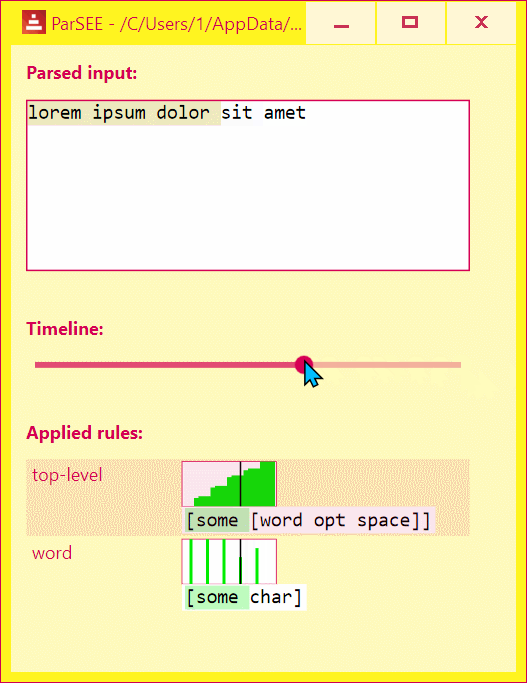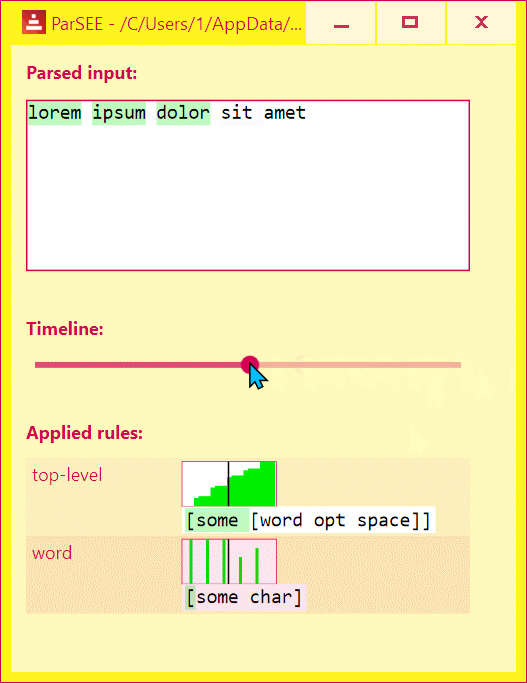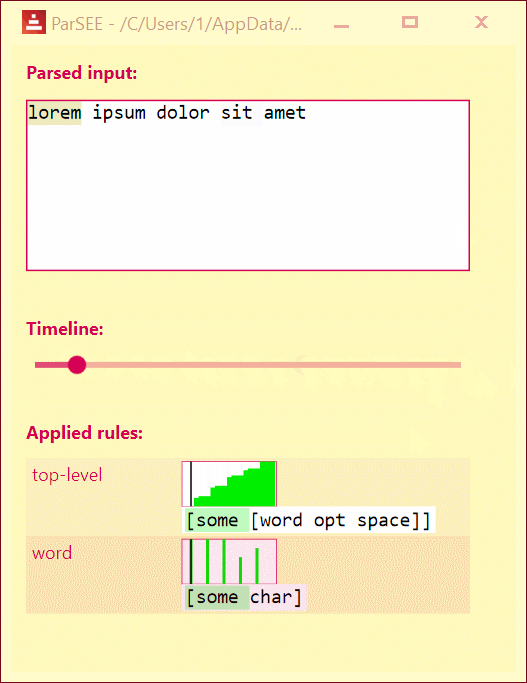
UI lists all detected Parse rules in depth-increasing order, with their profiles (Y = input advancement, X = time in events), and rules text.
Use Left/Right keys to change time by single event.
Overview of the backend...
parsee is a high level replacement for parse:
>> ? parsee
USAGE:
PARSEE input rules
DESCRIPTION:
Process a series using dialected grammar rules, visualizing progress afterwards.
PARSEE is a function! value.
ARGUMENTS:
input [any-block! any-string!]
rules [block!]
REFINEMENTS:
/case => Uses case-sensitive comparison.
/part => Limit to a length or position.
length [number! series!]
/timeout => Force failure after certain parsing time is exceeded.
maxtime [time! integer! float!] "Time or number of seconds (defaults to 1 second)."
/keep => Do not remove the temporary dump file.
/auto => Only visualize failed parse runs.
It parses input, collects data and calls the frontend for analysis. Optionally /auto flag can be used to skip successful parse runs, and only visualize failures.
parse-dump is a lower level parse wrapper:
>> ? parse-dump
USAGE:
PARSE-DUMP input rules
DESCRIPTION:
Process a series using dialected grammar rules, dumping the progress into a file.
PARSE-DUMP is a function! value.
ARGUMENTS:
input [any-block! any-string!]
rules [block!]
REFINEMENTS:
/case => Uses case-sensitive comparison.
/part => Limit to a length or position.
length [number! series!]
/timeout => Specify deadlock detection timeout.
maxtime [time! integer! float!] "Time or number of seconds (defaults to 1 second)."
/into =>
filename [file!] "Override automatic filename generation."
It only does the collection of data. By default it is saved with a unique filename in current working directory. When something goes wrong on either side, it becomes useful to dump the data for manual inspection.
inspect-dump is a frontend launcher:
>> ? inspect-dump
USAGE:
INSPECT-DUMP filename
DESCRIPTION:
Inspect a parse dump file with PARSEE tool.
INSPECT-DUMP is a function! value.
ARGUMENTS:
filename [file!]
It can be used to analyze a set of previously saved dumps right from the console.