OCR UI built on the top of Tesseract engine for Amharic language
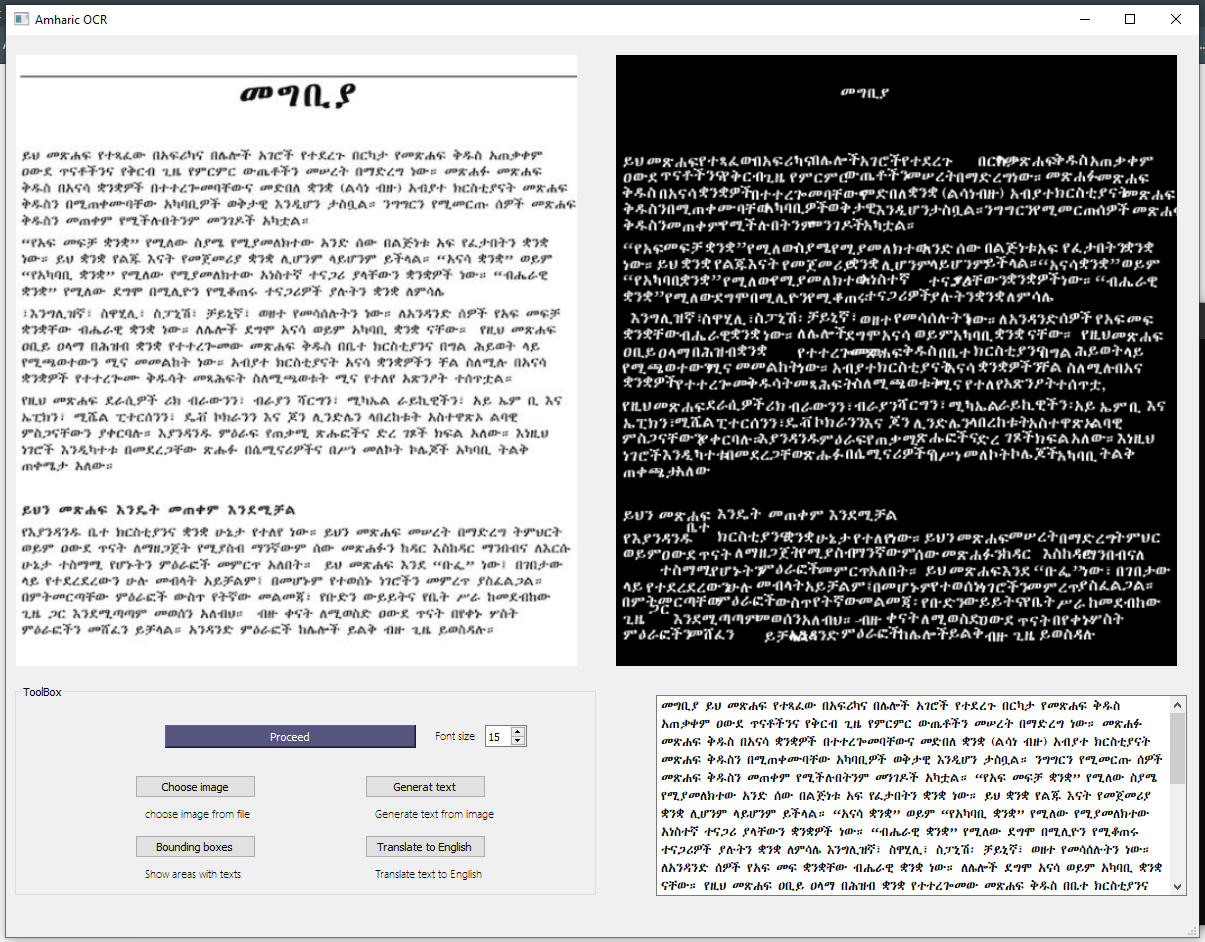
AddisOCR is a very simple UI i made to implement Tesseract on Amharic texts with some pre-processing algorithms. You can choose any Image formats by clicking the “choose image” button and the you can click the “proceed” button with an appropriate font size. I have used AbyssinicaSIL font file because Amharic is not supported by default in Opencv.
The package contains an OCR engine — libtesseract and a command line program - tesseract. Tesseract 4 adds a new neural net (LSTM) based OCR engine which is focused on line recognition, but also still supports the legacy Tesseract OCR engine of Tesseract 3 which works by recognizing character patterns. Compatibility with Tesseract 3 is enabled by using the Legacy OCR Engine mode (--oem 0). It also needs traineddata files which support the legacy engine, for example those from the tessdata repository. Tesseract was originally developed at Hewlett-Packard Laboratories Bristol and at Hewlett-Packard Co, Greeley Colorado between 1985 and 1994, with some more changes made in 1996 to port to Windows, and some C++izing in 1998. In 2005 Tesseract was open sourced by HP. Since 2006 it is developed by Google.
pip install pytesseract opencv-python PyQt5 pillowcd <project-dir>
python main.pyOne thing to note in installation is tesseract uses individual trained models for each languages, the default language is English but in our case we are going to use tesseract for Amharic so download the pre-trained model in tesseract official repo, I also have uploaded it on the project repo so copy that to /tessdata. now we proceed to testing.
import pytesseract
import cv2
pytesseract.pytesseract.tesseract_cmd=r"<path-to-tesseract>\\tesseract.exe"
img = cv2.imread("img1.png")
cv2.imshow("img", img)
text = pytesseract.image_to_string(img, lang="amh")
print(text)
cv2.waitKey(0)
cv2.destroyAllWindows()The above code demonstrates the simplest way to use pytesseract for amharic language. The first 2 lines import the libraries we are going to use ( Pytesseract and Opencv ). The next line assigns the engine path to the library, this will differ platform to platform so you have to replace it with your own installation path. Next we have read our image (we are using opencv here) as a 3 channel BGR image, luckily pytesseract supports 3 channel opencv image you no pre-processing is needed if the image is clear enough. As you can also see I have mentioned the language code for Amharic (“amh”) as an argument for the image_to_string method. If you are using cmd or powerchell on windows you have to enable you command line tool to support Amharic encoding. In my case the output text looks like this…