Horse racing data has been hoarded by a few companies, enabling them to effectively extort the public for access to any worthwhile historical amount. Compared to other sports where historical data is easily and freely available to use and query as you please, racing data in most countries is far harder to come by and is often only available with subscriptions to expensive software.
The aim of this tool is to provide a way of gathering large amounts of historical data at no cost.
You must have Python 3.7 or greater, and GIT installed. You can download the latest Python release here. You can download GIT here.
In addition, the Requests, tomli, orjson, AIOHTTP and LXML python modules are needed, they can be installed using PIP(included with Python) with the following command.
pip3 install requests tomli orjson aiohttp lxml
git clone https://github.com/joenano/rpscrape.git
Run the program from the scripts folder:
cd rpscrape/scripts
python3 rpscrape.py
To scrape you must provide 3 options in the following format:
[rpscrape]> [region|course] [year|range] [code]
The first option can be either a region or a specific course.
Each region has a 2 or 3 letter code like "ire" for Ireland or "gb" for Great Britain. You can list region codes with the regions command:
[rpscrape]> regions
CODE: mal | Malaysia
CODE: mac | Macau
CODE: gue | Guernsey
CODE: ity | Italy
CODE: swi | Switzerland
CODE: tur | Turkey
The other possibility for the first option is that of a specific course. Course codes are numeric and up to 4 digits long. You can list course codes with the courses command:
[rpscrape]> courses
CODE: 32 | Aintree
CODE: 2 | Ascot
CODE: 3 | Ayr
CODE: 4 | Bangor
CODE: 5 | Bath
CODE: 6 | Beverley
Add a search term to search for a specific region or course:
[rpscrape]> regions france
CODE: fr | France
[rpscrape]> courses york
CODE: 107 | York
CODE: 1347 | York Aus
Add a region code to list the courses from that region:
[rpscrape]> courses ire
CODE: 175 | Ballinrobe
CODE: 176 | Bellewstown
CODE: 177 | Clonmel
CODE: 596 | Cork
CODE: 178 | Curragh
CODE: 180 | Down Royal
The second option can be a year e.g "1999", or a range of years e.g "2005-2015".
The final option is the racing code and can either be "flat" or "jumps".
The following example shows a request for flat races from Ireland in 2017.
[rpscrape]> ire 2017 flat
The next example shows a request for the last 2 years flat form in Great Britain.
[rpscrape]> gb 2017-2018 flat
The next example shows a request for the last 20 years jump form at Ascot(code: 2).
[rpscrape]> 2 1999-2018 jumps
Note: When scraping jumps data the year you enter is when the season started, i.e to get 2019 Cheltenham Festival data, you would use the year 2018.
[rpscrape]> 11 2018 jumps
In the above example, Cheltenham races from the season 2018-2019 are scraped, the 2018 Greatwood and the 2019 festival will be included but not the 2018 festival.
To scrape by date or date range, use the -d flag followed by the date/date range and the region. Scraping individual courses in this manner is not included:
[rpscrape]> -d [date|range] [region]
The date format is YYYY/MM/DD, to specify a range of dates, separate them with a dash '-', start date followed by end date.
[rpscrape]> -d 2019/12/18 gb
[rpscrape]> -d 2019/12/15-2019/12/18 ire
Its now possible to run from the command line with a few flags.
To scrape by date, use the -d flag for dates and -r flag for optional region, if no region code is provided, all races from the given dates will be scraped by default.
All races will be scraped on date.
./rpscrape.py -d 2020/10/01
Only races from GB will be scraped.
./rpscrape.py -d 2020/10/01 -r gb
To scrape a particular course or region, use the -c or -r flags with the course or region code. Use the -y flag for the year and -t flag for the type of racing, flat or jumps.
./rpscrape.py -c 2 -y 2015-2020 -t jumps
./rpscrape.py -r ire -y 2019 -t flat
You can scrape racecards using racecards.py which saves a file containing a json object of racecard information.
There are only two parameter options, either today or tomorrow.
./racecards.py today
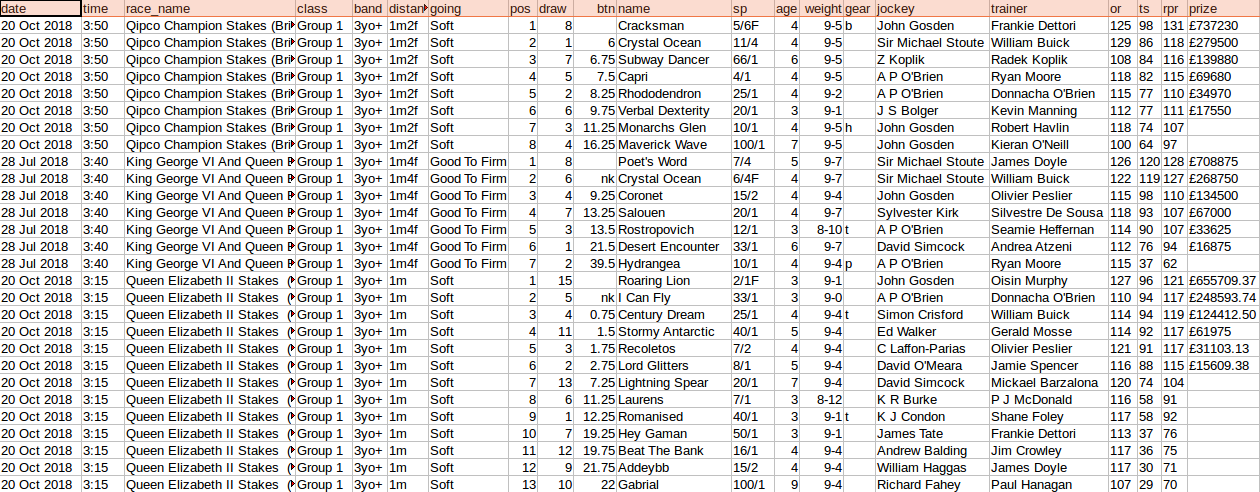
You can see the structure of the json and some of the race information below.
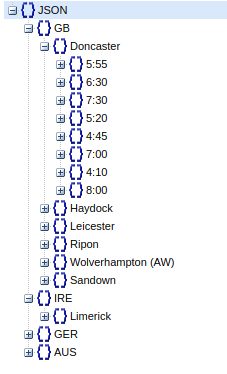

The user_settings.toml file contains the data fields that can be scraped. You can turn fields on and off by setting them true or false. The order of fields in that file will be maintained in the output csv. The default_settings.toml file should not be edited, its there as a backup and to introduce any new fields without changing user settings.
regions List all available region codes
regions [search] Search for specific region code
courses List all courses
courses [search] Search for specific course
courses [region] List courses in region - e.g courses ire
-d, date Scrape race by date - e.g -d 2019/12/17 gb
help Show help
options Show options
cls, clear Clear screen
q, quit, exit Quit
Tab complete for option keywords is available on Linux.