Tensor Core算力:一共有16个SM单元,计算核心频率最高为1.3GHz,每个SM单元包含4个TensorCore和128个CUDA Core,安培架构一拍可以计算(16x8+8x16=256次乘累加)
Tensor Core峰值性能:16x4x256x1.3GHz=20.8TFLOPs
CUDA Core峰值性能:16x128x1x1.3GHz=2.6TFLOPs
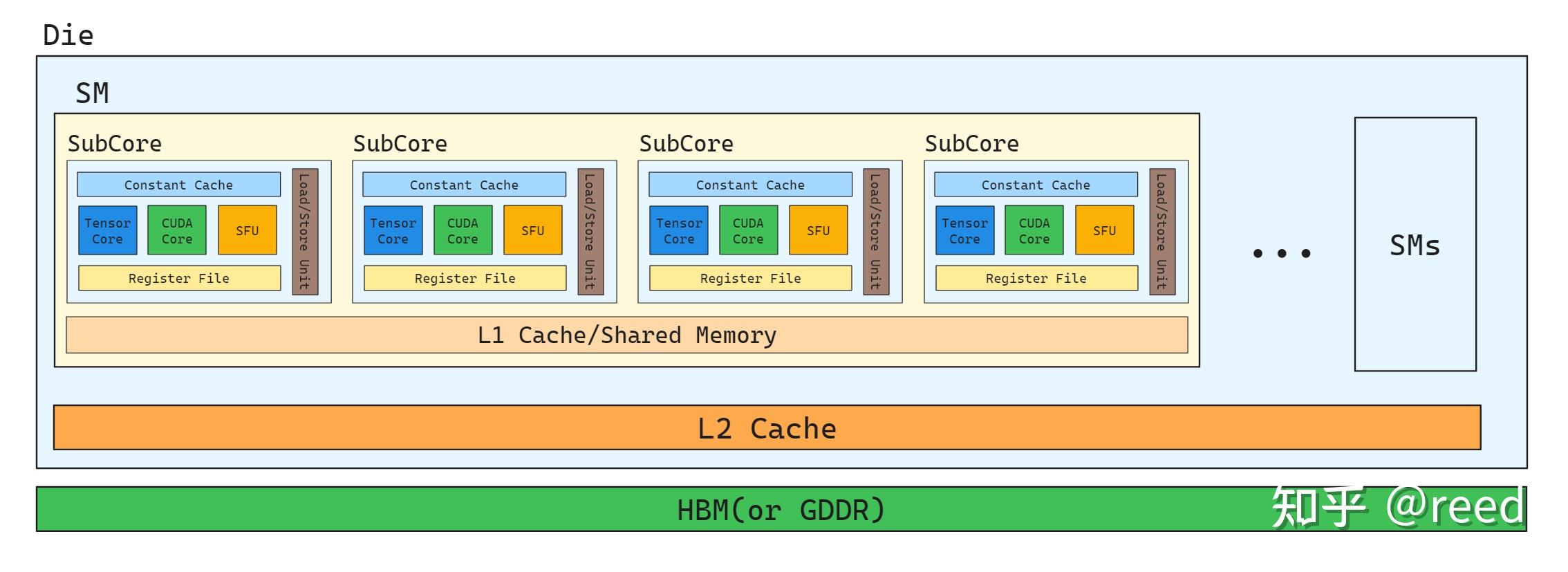
GPU是一个高度并行的设备,其上装配了大量的计算单元,为了更好的组织这些计算单元,更充分的利用数据局部性和支持数据规约和同步的能力,GPU采用层次化的组织形式。整体而言,计算单元组织方面可以分为三个层次:
- 最小计算机构为SubCore,其负责warp的执行
- 4个SubCore组织成一个SM
- 多个SM组织成GPU
SubCore中包含TensorCore,主要用于矩阵计算,CUDACore主要用于向量化的浮点数与整数乘加计算,SFU(Special Function Unit,特殊函数单元)用于完成sin、exp2、sqrt、rcp等函数运算,同事SubCore内有程序状态核心存储机构寄存器文件,还有具有广播语义的常量内存,SubCore内还有用于外部数据加载和存储用的Load Store Unit。除此之外,SubCore里面还有warp schduler、branch unit、FP64等单元。
存储单元组织方面分布如下:
- SubCore内有寄存器和Constant Cache
- SM内有四个SubCore公用的L1 Cache和Shared Memory
- 所有SM共享L2 Cache(通过交叉开关,CrossBar)
软件和硬件之间的映射关系:
- SubCore映射到CUDA中的warp
- SM映射到CUDA中的block
- 多个SM映射到CUDA中grid
在软件向硬件映射时多了调度的逻辑:即一个SubCore可以运行多个warp,一个SM可以运行多个block,有限的SM可以运行远超其硬件数目的grid。
CUDA Strean是GPU上任务的执行队列,所有的CUDA操作(包括kernel和内存拷贝等)都在stream上执行。Stream有两种:
-
隐式流:也叫默认流,如果没有显示指定流,所有的CUDA操作都会在默认流中运行,此时此流是和CPU端计算是同步的,意思是CPU的计算需要等待上面的GPU运算计算完毕才会开始,会被阻塞在那里;
-
显式流:显式申请的流,显示申请的流和Host端是异步执行的,不同的显式流之间也是异步执行的。
可以用来把包含若干个核函数的任务打包起来,包括核函数之间的依赖关系,形成一个计算图。引入graph有下面的好处:
cuda_graph的引入是为了解决kernel间launch的间隙时间问题的,尤其是有一堆小kernel,每个kernel启动也会带来一些开销,如果这些kernel足够多,那么就可能会影响系统的整体性能,cuda_graph的引入就是为了解决这个问题的,它会将stream内的kernel视为一整个graph,从而减少kernel的launch间隙时间。
- 减少了CPU和GPU之间的交互:一旦图被捕获,它可以在没有CPU介入的情况下重放,这减少了每次推理时的CPU开销。
- 更高的GPU利用率:因为图中的操作可以被优化和重排,以最大化GPU的利用率。
- 更低的推理延迟:减少了CPU到GPU的往返时间,从而降低了整体的推理延迟。
下面是创建一个CUDA图要用到的函数:
// Start capture on CUDA stream s. Mode is typically cudaStreamCaptureModeGlobal.
cudaStreamBeginCapture(cudaStream_t s, cudaStreamCaptureMode mode );
// End capture on CUDA stream s. A pointer to the resulting graph is placed in graph.
cudaStreamEndCapture(cudaStream_t s, cudaGraph_t * graph);
// The argument gexec is set to an executable version of the graph in graph.
// The last three arguments provide detailed error information and can be set to
// nullptr, nullptr and 0 if this information is not needed
cudaGraphInstantiate(cudaGraphExec_t* gexec, cudaGraph_t graph, cudaGraphNode_t* errornode, char* errorlog, size_t errorlogsize );
// Launch the executable graph gexec in stream s.
// The launch stream does not have to be the same as the capture stream.
cudaGraphLaunch(cudaGraphExec_t gexec, cudaStream_t s );在tensorrt中可以将engine包装成一个graph,要启动engine时启动这个graph即可,这样可以缩减掉很多小的kernel的启动时间。
| 指令 | 类型 | 目标操作位置 | 源操作位置 |
|---|---|---|---|
| LDG | Load | 寄存器 | 全局内存 |
| STG | Store | 全局内存 | 寄存器 |
| LDS | Load | 寄存器 | 共享内存 |
| STS | Store | 共享内存 | 寄存器 |
| LDL | Load | 寄存器 | 局部内存 |
| STL | Store | 局部内存 | 寄存器 |
| LDSM | Load | 寄存器 | 共享内存 |
| 非Load/Store指令 | 算数指令 | 寄存器 | 寄存器 |
寄存器分配模式:
-
对于每个thread,在ampere架构中,一个thread可以访问最多512个寄存器,在这个thread中,这512个寄存器都是可以访问的;
-
对于warp level:在编译阶段已经确定每个thread需要多少寄存器(假设m个),那么在每个warp上这m个寄存器是可以访问的,另外的512-m个寄存器是给其他warp访问的;
通过上面这种分配方式,实现了CUDA中最重要的延迟隐藏机制。
- 通用寄存器
通用寄存器位宽都是32bits,一个线程私有的通用寄存器最多是255个,在SSAS中,以R为前缀,表示为R0-R255.
由于一个寄存器位宽是32bits,所以在算法中使用如float2,float4数据结构时,一般时采用多个连续的寄存器组来完成,但是在SSAS编码中只体现首寄存器的编码,其余的寄存器编码不体现。
- 特殊寄存器(Spacial Register)
特殊寄存器一般时只读的,用于标识该执行单元的定位信息,如线程号、线程块号等,需要通过特定的指令来读取这些寄存器,常见特殊寄存器如下:
- SR_TID:thread block内的线程id,threadIdx;
- SR_CTAID: blockIdx;
其余的特殊寄存器在PTX文档的Sepcial Register章节可以找到。
- Predicate寄存器
Predication是GPU架构中用于实现分支预测的技术,一般用于控制warp中线程的执行流程。在GPU中的分支预测寄存器主要体现以下几个方面:
-
提高分支效率:GPU中的分支预测寄存器允许在整个warp层面根据单一的预测结果来决定是继续执行还是跳过某些指令。这种方式可以减少每个线程单独进行分支决策的开销,从而提高分支处理的效率。
-
减少分支开销:由于predication寄存器的存在,GPU可以在一个统一的控制下管理线程束的执行路径,这减少了每个线程单独处理分支的需要,从而降低了分支操作的总体开销。
-
简化编程模型:对于程序员来说,predication寄存器提供了一种更为简单的方法来控制线程束的行为,而不需要在代码中显式地处理复杂的同步和分支逻辑。
Predicate寄存器主要有两个作用:
-
在指令执行前作为指令的执行条件放在指令开始,只有当该Predicate寄存器为True时,这条指令才执行:
@P6 FADD R5 R5 R28 @!P6 FADD R5 R5 R27 -
寄存器值可以作为操作数参与运算。
Predicate寄存器是每个线程私有,每个线程最多使用8个,在SSAS中以P为前缀,表示为P0-P7,最后一个P7为常真寄存器,表示为PT。
- Uniform寄存器
uniform寄存器主要是在warp level使用,通过使用uniform 寄存器,可以减少私有寄存器的使用量,从而可以减少warp内线程对通用寄存器的使用,从而在这个SM上可以运行更多的warp来提升并发度。
Uniform寄存器为每个warp私有,每个warp最多可以使用64个,以UR为前缀,Uniform Predicate寄存器以UP为前缀,单个warp最多可以使用7个。一般最后一个寄存器都是常量寄存器。
-
数据load指令
数据加载相关指令如下:
LD: 通用指令,编译器在编译时无法推导出地址空间类型时的数据加载 LDG:从global memory加载数据 LDS:从shared memory加载数据 LDSM:从shared memory加载矩阵 LDL:从本地内存加载数据-
LDG:支持8bits-128bits的数据加载,其中向量化的数据加载如LDG.128时GPU支持的最大的加载指令,一条指令可以夹杂i128bits的数据,对于同等规模的数据,使用更宽的加载指令可以减少warp对指令的调度次数,减少调度开销,减少MIO queue的是无数,避免由于queue满而造成阻塞。
LDG.类型.向量.Cache控制.L2预取 -
LDGSTS(LoaD Global memory STore Shared memory):可以实现不经过寄存器的全局内存到共享内存的数据搬运,减少寄存器的使用和依赖,在矩阵计算中,由于Multi Stage的矩阵计算有重要作用。
LDGSTS, LDGDEPBAR, DEPBAR.LE SB0, 0x1 -
LDS:和LDG类似;
-
LDSM:主要在tensor core使用,是warp级指令,完成共享内存到寄存器的数据加载,然后将这些寄存器喂给Tensor Core指令完成矩阵计算;
-
LDL:下面这三种情况会引入本地内存:
- 当线程计算需要局部数组,并且数组的下标不能被编译时计算得到;
- 单线程的寄存器使用数目超过255;
- 访问kernel数组常量时使用了不能被编译时确定的索引。
-
-
Constant Cache
上面提到在SubCore中有constant cache机构,它和常量内存没有关系,它提供了一种广播语义,即当warp中所有线程都访问同一个数据时,它的访问速度和寄存器一样快。
另外kernel的参数需要广播给所有的执行线程,所以这个参数也是使用constant cache实现的。
在CUDA编程时可以使用
__constant__ __device__ float a的方式调用constant cache。
-
声明两个输入矩阵和一个输出矩阵的fragment,这个fragment用的是整个warp的寄存器,具体声明方法如下:
// 输入的矩阵a于矩阵b声明 wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> frag_a; wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> frag_b; // 输出的矩阵声明 wmma::fragment<wmma::accumulator, 16, 16, 16, half> frag_c;
-
初始化矩阵,这种方式可以直接初始化整个矩阵
wmma::fill_fragment(frag_c, 0.0f);
-
加载矩阵数据
wmma::load_matrix_sync(frag_a, (shared memory / global memory), stride_a); wmma::load_matrix_sync(frag_b, (shared memory / global memory), stride_b);
-
矩阵计算
wmma::mma_sync(frag_c, frag_a, frag_b, frag_c); -
结果写回
wmma::store_matrix_sync((shared memory / global memory), frag_c, stride_c, wmma::mem_row_major);
- shared memory结构
从官方文档可以知道,放在shared memory中的数据是以4bytes(即32bits)作为一个word,依次放在 32 个 banks 中。所以,第 i 个 word,就存放在第 ( i mod 32 ) 个 bank 上。
每个bank在每个时钟周期的带宽是32bits,即每个bank一个时钟周期只能访问4个bytes数据。
所以 shared memory 在每个 cycle 的 bandwidth 为 32 * 32 bits = 32 * 4 bytes = 128 bytes。
shared memory访存方式有两种,broadcast和bank conflict。
-
一个warp中每个thread只访问4bytes(32bits)数据:
-
broadcast:一般出现在多个thread访问同一个bank同一地址的情况。当多个 thread 访问同一个 bank 内的同一个 word,就会触发 broadcast 机制。这个 word 会同时发给对应的 thread;
-
bank conflict:一般出现在多个thread访问同一个bank的不同地址的情况。当多个 thread 访问同一个 bank 内的不同 word 时,就会产生 bank conflict。于是请求会被拆分成多次 memory transaction,串行地被发射(issue)出去执行。(比如 2-way bank conflict,就拆分成 2 次 transaction)
-
-
一个warp中每个thread访问64 bits数据(如通过float2、uint2数据类型,LDS.64指令),这时一个warp访问超过128bytes,CUDA会默认将一个warp拆分乘两个half warp,每个half warp产生一次memory transaction,故一共会有两次transaction:
-
broadcast:合并规则是活跃线程和下1/2个id线程不活跃或者其访存地址一致,这时会发生broadcast。
-
bank conflict:只有在一个half warp中出现多个thread访问一个bank的时候才会产生bank conflict,因为一个half warp表示一个memory transaction。
-
-
一个warp中每个thread访问128bits数据(如通过float4、int4数据类型,LDS.128指令),这时half warp进一步拆分乘quarter warp,每个quarter warp产生一次memory transaction:
-
broadcast:合并规则是活跃线程和下1/2个id线程不活跃或者其访存地址一致,这时会发生broadcast。
-
bank conflict:只有在一个quarter warp中出现多个thread访问一个bank的时候才会产生bank conflict,因为一个quarter warp表示一个memory transaction。
-
- 矩阵乘法
矩阵乘法中一般会选择使用Z-order来重新排布读取顺序,通过这种方式,矩阵乘法才能有效使用前面的broadcast和避免bankconflict,下面是chatGPT的解释:
Z-order,也被称为Morton-order或Morton code,是一种将多维数据映射到一维数据的方法。在矩阵乘法的上下文中,Z-order可以用来优化数据在内存中的存储布局,从而提高缓存的使用效率。
在传统的矩阵存储中,二维数组通常按行或按列顺序存储。例如,在C语言中,二维数组是按行的顺序存储的(行优先),而在Fortran中,是按列的顺序存储的(列优先)。这种存储方式在进行某些操作时可能不是最优的,特别是在矩阵乘法这样的操作中,访问不连续的内存地址会导致缓存未命中,从而降低性能。
Z-order曲线尝试解决这个问题,它通过一种特殊的方式来遍历矩阵的元素,以便保持数据访问的局部性。具体来说,Z-order曲线是一种空间填充曲线,它尝试在遍历二维(或更高维)数据时保持相邻数据点在物理存储(一维)中也是相邻的。
在矩阵乘法中,可以使用Z-order来重新排列矩阵的数据,使得在计算时访问的数据在物理内存中尽可能地连续,这样可以提高缓存的命中率,因为缓存是以块的形式工作的,连续的数据访问模式可以减少缓存加载和替换的次数。
Z-order在矩阵乘法中的应用通常是高性能计算或优化库中的一个高级特性,因为它需要重新安排数据并可能需要额外的索引计算来确定元素的位置。然而,对于大规模的矩阵乘法操作,这种优化可以显著提高性能。
一共有三类warp-level原语,参考自知乎上的一篇文章。
第一类函数是在warp中的线程之间进行数据交换的函数:
- Warp Vote Functions:
- __all_sync:
- 函数声明:
int __all_sync(unsigned mask, int predicate);
- 作用:用于在一个warp内部进行条件同步,它能确保只有当前mask中所有线程都满足给定条件时,才会执行后续的代码;
- 函数声明:
- __any_sync:
- 函数声明:
int __any_sync(unsigned mask, int predicate);
- 作用:用于检查一个warp中是否至少有一个线程的指定条件是真,和__all_sync的区别是
__any_sync只需有一个线程满足要求,则可继续执行,而__all_sync需要保证所有线程均满足要求才能继续执行;
- 函数声明:
- __uni_sync:
- 函数声明:
int __uni_sync(unsigned mask, int predicate);
- 作用:
- 函数声明:
- __ballot_sync:
- 函数声明:
unsigned __ballot_sync(unsigned mask, int predicate);
- 作用:
- 函数声明:
- __all_sync:
- Warp Reduce Functions:
- __shfl_sync:
- 函数声明:
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
- 作用:
- 函数声明:
- __shfl_up_sync:
- 函数声明:
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
- 作用:
- 函数声明:
- __shfl_down_sync:
- 函数声明:
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
- 作用:
- 函数声明:
- __shfl_xor_sync:
- 函数声明:
T __shfl_xor_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
- 作用:
- 函数声明:
- __shfl_sync:
- Warp Match Functions:
- __match_any_sync:
- 函数声明:
unsigned int __match_any_sync(unsigned mask, T value);
- 作用:
- 函数声明:
- __match_all_sync:
- 函数声明:
unsigned int __match_all_sync(unsigned mask, T value, int *pred);
- 作用:
- 函数声明:
- __match_any_sync:
第二类是Active mask query,作用是返回一个32位的掩码,这个掩码表示哪些线程处于活动状态:
- __activemask:
- 函数声明:
```c++
```
- 作用:
第三类是线程同步函数,作用是同步warp中的线程,并提供内存隔离
- __syncwarp:
- 函数声明:
```c++
```
- 作用:
-
block设置:1024的限值;
-
grid设置:尽量设置为当前硬件拥有SM的倍数;
###3.3 Cooperative Groups
TODO:待完善
使用下列指令编译matmul的算子
cd matmul
mkdir build & cd build
cmake -DCMAKE_BUILD_TYPE=Debug ..
# cmake -DCMAKE_BUILD_TYPE=Release ..基础实现参照Host端的基础矩阵乘法代码,线程组织形式为一个thread计算输出的一个值,block组织成二维方式,核心代码如下:
__global__ void gemm_baseline(float* d_a, float* d_b, float* d_c, int N, int K, int M) {
/* baseline:
d_a: M * K
d_b: K * N
d_c: M * N
*/
/* 计算d_c索引 (i, j) */
unsigned int c_i = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int c_j = blockDim.y * blockIdx.y + threadIdx.y;
/* 执行计算 */
float output = 0.0;
for (int k=0; k < K; ++k) {
output += d_a[c_i * K + k] * d_b[k * N + c_j];
}
/* 结果写回 */
d_c[c_i * N + c_j] = output;
}分析:在baseline的最小循环内,一共有两次从global mem的访存,一次FFMA操作,该核函数的计算密度0.5。 核函数计算效率很低,核函数一直在等访存结果,这样整体的SM占用率极低,通过ncu分析可以发现,核函数带宽接近94%,而计算利用率约7%,所以下一步的优化策略是提升一个线程的FFMA次数。 下一步策略:根据从global mem的带宽(204.8GB/s)与CUDA Core计算频率(1.3 GHz)对比,使用tile策略,每个thread计算约64-128个FFMA。 在此之前,需要先将数据存入共享内存防止频繁从global mem中做访存。
reduce是一类算子,一般常用的求和、求最值等操作实际执行时均采用reduce操作,也叫归约操作。
在GPU中,reduce有两种写法,第一种是顺序分块归约,第二种是递归归约。递归归约的时间复杂度较顺序分块归约的时间复杂度低。
reduce的计算公式可以写成下面的方式:
我们在这里实现的是reduceSum操作,首先根据reduce的计算方式实现一个baseline,首先将数据存入共享内存中:
__global__ void reduce_kernel_baseline(float* d_in, float* d_out) {
/*base版本的reduce算子
d_in: reduce算子的输入,表示为一维数组;
d_out: reduce算子的输出,表示为一维数组;
使用共享内存进行访存, block和grid均为一维
*/
__shared__ float sdata[THREADS_PER_BLOCK];
/* 获取输入的index和当前进程的index */
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int tidx = threadIdx.x;
/* 读取输入到共享内存 */
sdata[tidx] = d_in[idx];
__syncthreads();
/* 进行reduce操作:
这个过程需要进行多轮迭代,
在第一轮迭代中,如果tid%2 ==0, 则第tid号线程将shared memory中第tid号位置的值和第tid+1号的值进行相加,而后放在第tid号位置。
在第二轮迭代中,如果tid%4==0,则第tid号线程将shared memory中第tid号位置的值和第tid+2号的值进行相加,而后放在第tid号位置。
不断迭代,则所有元素都将被累加到第0号位置。
*/
for (int s=1; s < blockDim.x; s*=2) {
if (tidx % (2*s) == 0)
sdata[tidx] += sdata[s + tidx];
__syncthreads();
}
/* 写回到主存中 */
if (tidx == 0) d_out[blockIdx.x] = sdata[0];
}
softmax是一个基本的激活函数,它可以将一个数值向量归一化为一个概率分布向量。
safe softmax的计算公式如下:
使用safe softmax的原因是exp函数计算结果具有不稳定性,部分值在经过exp后超出数值表示范围,会引起softmax计算不准确。根据exp函数的特性,均减去最大值,这样可以保证softmax的计算结果准确。
为了后续便于与其他算子进行融合,对safe softmax进行拆分,有online softmax函数,具体公式:
online softmax在每次循环中只需访存2次,写入1次,而safe softmax在每次循环中需要访存3次,写入1次。这种写法会有速度提升。
transpose算子很简单,两次访存,没有计算。
卷积的基本实现过程如下图所示:

对于一个CHW的输入张量,有一个filter(CRS)在此HW上滑动,在每次滑动位置计算卷积操作(逐位置点乘再求和),可以计算得到PQ的特征图;一共K个filter,就可以产生KPQ的张量,加上前面的N,得到此算子计算后的NKPQ张量。
卷积的输入输出对应关系公式如下:
卷积的基本实现过程是:卷积核在输入的一个特征图上滑动,计算卷积核于特征图上对应区域的点积,这个卷积核在C个输入特征图上均需进行上述操作,一个卷积核那么可以生成C个特征图,然后将这C个特征图对应位置做加法操作,这就计算出一个卷积核的输出特征图,一共有K个特征图,那么就会计算出KHW的输出特征向量(不包含B)。
卷积的naive版本计算公式如下:
其中$h_i$和$h_o$之间的转换关系为:
这种方式的大致cpu实现如下:
for(b:B) {
for(c_o:C) {
for (h_o:H) {
for (w_o:W) {
out_idx = b * CHW + c_o * HW + h_o * W + w_o;
O[out_idx] = bias[c_o];
for (h_k:H_k) {
for (w_k:W_k) {
input_h = h_o * stride_r + h_k - padding_r;
input_w = h_o * stride_r + h_k - padding_r;
for (c_i:C_I) {
O[out_idx] += weight[c,h_k,w_k] * I[b, c_i,input_h,input_w];
}
}
}
}
}
}
}
根据前面的naive实现,我们将输入的一个特征图进行展开,将每次滑动对应的特征值拉平成一个列向量,一共需要进行HW次拉平,所以会产生一个$H_kW_k * HK$的二维矩阵,而卷积核则拉平成一个行向量;K个卷积核组合成一个$K * H_kW_k$的矩阵;最终将$weight \otimes Input$则可以一次计算得到输入的一个特征图的输出结果。一共有C个特征图,计算C次此矩阵,最终对应位置相加得到最终结果。
由上面的基本过程可以知道,对于一个NCHW的输入张量,和一个KCRS的filter张量,可以得到一个NKPQ的输出张量,如果使用im2col+gemm的方式来进行计算,可以将其转换为一个
上面的im2col+gemm的方式需要存入一个im2col的矩阵,然后在gemm阶段再重新读入进行计算,这种方式的访存会比较差,所以现在一般采用implicit_im2col的方式来替代im2col+gemm的方式,具体baseline的核函数思路如下:
-
block线程组织: 根据输出大小
$N \times K \times P \times Q$ ,和naive的函数一样每个线程处理一个输出值,但是不同的是使用shared memory存储im2col的input值和weight值。我们设置一个二维的block,分别拆分$C$ 和$HW$ 两个维度。 -
grid线程组织:根据维度,设置x轴维度为$\frac {PQ} {TILE}$,设置y轴维度为
$\frac {K} {TILE}$ ,设置z轴维度为$N$ -
共享内存:设置两个共享内存,分别存放临时的input的im2col值和weight的im2col值,由于共享内存空间有限,无法直接存入
$CRS$ 所有的值,故采用分块计算的方式,依次读取input和weight对应的区域$\frac{CRS} {TILE}$ 存入共享内存,然后每次迭代从读取其中部分数据完成计算,思路与矩阵乘法一致。 -
输入与权重的对应关系:目前im2col输出的索引是
$$out_{c} = blockIdx.y * TILE + threadIdx.y$$ $$out_{PQ}=blockIdx.x * TILE + threadIdx.x$$ 我们需要根据上面的索引去反推weight的索引和input的索引,weight需要拿到$c_o,c_{i},kh,kw$ ,input需要拿到$b, c_i, h_i, w_i$ 。这里需要注意需要先拿到weight的索引,然后才能拿到input的索引。
layernorm算子在attention中非常常用,一般用来减少网络层和层之间的Covariate Shift,提高网络的收敛速度。layernorm的计算公式如下:
layernorm和softmax很相似,都是在一行元素内计算做两次归约然后再做点积。
计算均值和方差的方法:
- 直接计算:
- 根据下面公式直接计算均值和方差,仅需在一个循环内计算$x$的均值和$x^2$的均值即可,这个方法的缺点是当数据量过大时,容易出现数值溢出,从而影响计算结果;维基百科的介绍是:缺点是其结果依赖于数据的排序,存在累加的舍入误差,对于大数据集效果较差:
- 在线算法Welford:具体计算公式如下所示,
标准的attention的计算公式如下,其中$q \in R^{N_q \times d_q}$,
多头注意力的计算公式如下,在实际的MHA计算中,往往还是使用标准attention,但是先将经过线性层的$Q,K,V$均根据头的数目进行拆分,组织成$(B*8, N, d // 8)$,在计算完成后在reshape回来:
在计算过程中,分别分析访存和计算,attention的计算过程如下:
1. 分block从主存加载矩阵Q,K,计算S = QK^T, 然后将矩阵S写回.
2. 从主存加载S,计算P=softmax(S),然后写回P.
3. 分block从主存加载矩阵P和V,计算O=PV,将O写回主存.
按步骤分析访存与计算:
-
步骤1:加载两个矩阵有
$2Nd$ 访存,计算是$N^2d$ 次计算, 结果写回是$N^2$访存,所以步骤1中有$(2Nd + N^2)$ 次访存,有$N^2$次计算; -
步骤2:加载矩阵S有$N^2$次访存,计算softmax有$2N^2$次计算,写回矩阵P有$N^2$次访存;
-
步骤3: 加载矩阵S与P有$N^2 + Nd$次访存,计算有$N^3d$次计算,结果写回有$Nd$次访存。