Developer Website Tutorial
This tutorial will give a basic introduction on how to add a new website scraper for HakuNeko. It will use the website www.epikmanga.com as reference. This website may change in the future, so be aware that the outcome of this tutorial may not work anymore, however the concepts will still be the same.
To pass this tutorial, the following requirements should be met:
-
HakuNeko is ready for local development
-
Intermediate knowledge of web-development (HTTP protocol, HTML, JavaScript, JSON, CSS selectors, …)
-
Experience with browser integrated developer tools (Inspector, Console, Network Monitor, …)
-
Good understanding of object oriented programming (OOP)
-
Patience, go slowly through this tutorial step by step, don’t rush
The first thing when adding a new website is to select an ID. The ID is a string that will be used in various places to reference this scraper (e.g. in bookmarks). Since the ID cannot be changed at a later time (it would break functionality) select the ID carefully. Furthermore the ID shall obey the following rules:
-
The ID must be unique (no other website scraper must use the same ID)
-
The ID must only contain lowercase letters, numbers and the characters
_and- -
The ID must always start with a lowercase letter (this restriction has been lifted with HakuNeko 5.0.8)
In this tutorial we are going to use the ID epikmanga
To add a new website scraper we need to create one new JavaScript module file.
The first thing to do is to create a new file which is basically a JavaScript module and exporting a single class containing the scraping logic.
The file must be placed into the directory /src/web/mjs/connectors so will be added automatically by the plugin mechanism.
The filename doesn’t matter, but since the file is going to contain a single class name, i suggest to use the same name for the file, we will use EpikManga.
Furthermore the file must not start with a . and always use the extension .mjs, otherwise it will not be found.
Now lets create the file /src/web/mjs/connectors/EpikManga.mjs with a bare minimum of boilerplate code which will be discussed in more detail within the next chapters:
import Connector from '../engine/Connector.mjs';
export default class EpikManga extends Connector {
constructor() {
super();
super.id = 'epikmanga';
super.label = 'Epik Manga';
this.tags = [ 'webtoon', 'turkish' ];
this.url = 'https://www.epikmanga.com';
}
async _getMangas() {
throw new Error('Not implemented!');
}
async _getChapters(manga) {
throw new Error('Not implemented!');
}
async _getPages(chapter) {
throw new Error('Not implemented!');
}
}Most websites have an icon / logo for better recognition. You may add this icon / logo, so it will also be shown in HakuNeko. First head over to the website in the browser and search for the icon. There are various approaches to find and extract the icon / logo:
-
Save it directly from the website using the browser
-
Searching the source code of the website for certain images such as favicon, touch icon, …
-
Observing the network traffic for images
-
Try to append the default favicon name to the website domain https://www.spottoon.com/favicon.ico
Now download the icon / logo to your machine.
The icon / logo should be small (1~16 KB @ 64×64 pixel) to prevent performance issues when rendering the list of supported websites in HakuNeko.
If necessary use an image editing software (e.g. GIMP) to modify or resize the icon / logo.
Now store the icon / logo in the /src/web/img/connectors directory and use the ID as the filename without any file extension.
For our tutorial the file /src/web/img/connectors/epikmanga will added.
Congratulations, at this point the website scraper is now part of HakuNeko.
You may run the npm start command to fire up HakuNeko and ensure the availibility of the new website scraper.
If something went wrong, an error shall be shown in HakuNeko’s developer console exposing more details.
Still, it is not yet functional, when trying to interact with the website scraper it would just show an error.
This chapter will provide more details on how the website scraper is supposed to be implemented.
|
💡
|
After starting HakuNeko leave the application running so you can reload it by pressing the F5 key (while the developer console is focused). This will make it easier to update the application after making some changes to one of the source code files. |
First lets take a closer look into the created file /src/web/mjs/connectors/EpikManga.mjs.
All website scrapers are based on the Connector class, which contains many predefined fields and methods that can be re-used or overwritten.
So in short a webscraper is nothing more than a specialization of the connector class.
To derive the EpikManga class from the connector, the connector must first be included in the webscraper file.
After that a new class is created that extends the Connector class.
Furthermore the class is exported using the ES6 module architecture so it can be used and instanciated by the plugin mechanism during runtime.
import Connector from '../engine/Connector.mjs';
export default class EpikManga extends Connector {
/* non-relevant code */
}Now lets take a closer look into the constructor.
This is the place where initial fields will be overwritten.
First we call super() this will in turn call the constructor() of the base class.
Now we can start overwriting the fields.
The following fields are mandatory:
-
The
idfield is the unique identifier which has already been discussed -
The
labelfield is the name of the website that will be shown in the UI -
The
tagsfield is a list of words describing the website (used for filering), it should at least contain the type (e.g. manga, webtoon, hentai, …) and the language (e.g. english, japanese, korean, …) -
The
urlfield is the base URL of the website which is used as source. This is also the link that will be used when opening the website from within HakuNeko (e.g. for manual website interaction) and the matching criteria when pasting website links directly into HakuNeko.
|
💡
|
Try to re-use tags from other website scrapers to avoid increasing the number of tags. If you introduce a new tag that is not yet used anywhere else, it will be automatically added to the selection filter in the UI. |
constructor() {
super();
super.id = 'epikmanga';
super.label = 'Epik Manga';
this.tags = [ 'webtoon', 'turkish' ];
this.url = 'https://www.epikmanga.com';
}Lets discuss the first method we are overwriting from the base class _getMangas().
This method is invoked whenever HakuNeko requests the manga list, e.g. when the user clicks on the synchronize button.
It has no parameters and will relay our scraping results back to HakuNeko when our operation is complete.
The method is async and must return the list of mangas that were scraped from the website.
The list is a collection of simple manga objects, where each object has an id and a title property, both of type string.
The id must be set to something that we can use later in the getChapters() method, to determine the chapters belonging to the manga, usually this would be the path of the URL for the manga page on the website (e.g. _/seri/god-of-martial-arts).
The title is the name of the manga that will be shown in the UI and also the name of the manga folder when downloading chapters.
|
ℹ️
|
Keep in mind that the implementation shown in this tutorial is just an example. It is completely up to the individual developer how to implement the body of the _getMangas() method. In the end all that matters is, that the method returns a mangaList or in case of failure throws an error.
|
Lets start with a simple fake list to see how this works. First we create a dummy manga list and then we relay it to HakuNeko. Change the corresponding method of our website scraper file to the following code:
async _getMangas() {
return [
{
id: 'dragonball',
title: 'Tutorial: Dragonball'
},
{
id: 'onepiece',
title: 'Tutorial: One Piece'
}
];
}After changing the source code, start HakuNeko (or reload the application if already running), select our added website scraper and click the synchronize button. The result should look like this:
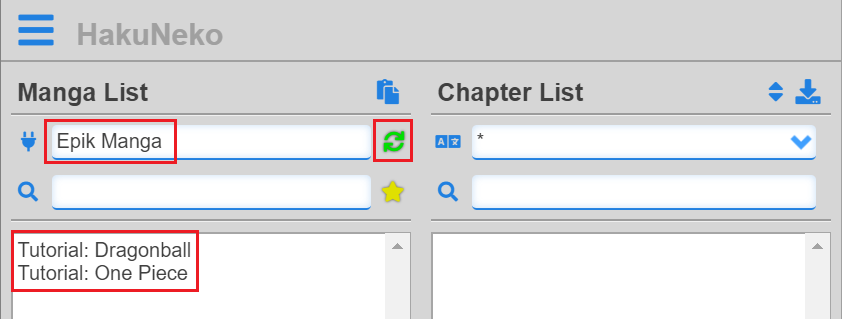
So far so good, but now it’s time for the real deal.
Head over to your favorite browser and open the website.
On the website lets search for a page that looks like it is listing mangas.
For our tutorial the discovered page https://www.epikmanga.com/seri-listesi?type=text looks very promising.
Now inspect the page and find a way to extract the manga titles and IDs out of the page that we need for our manga list.
This is where your web-development skills and browser-tools experience are required.
In this case a CSS selector such as div#pop-href div[id^=char-] a seems to be very appropriate to get the link elements that we are after.
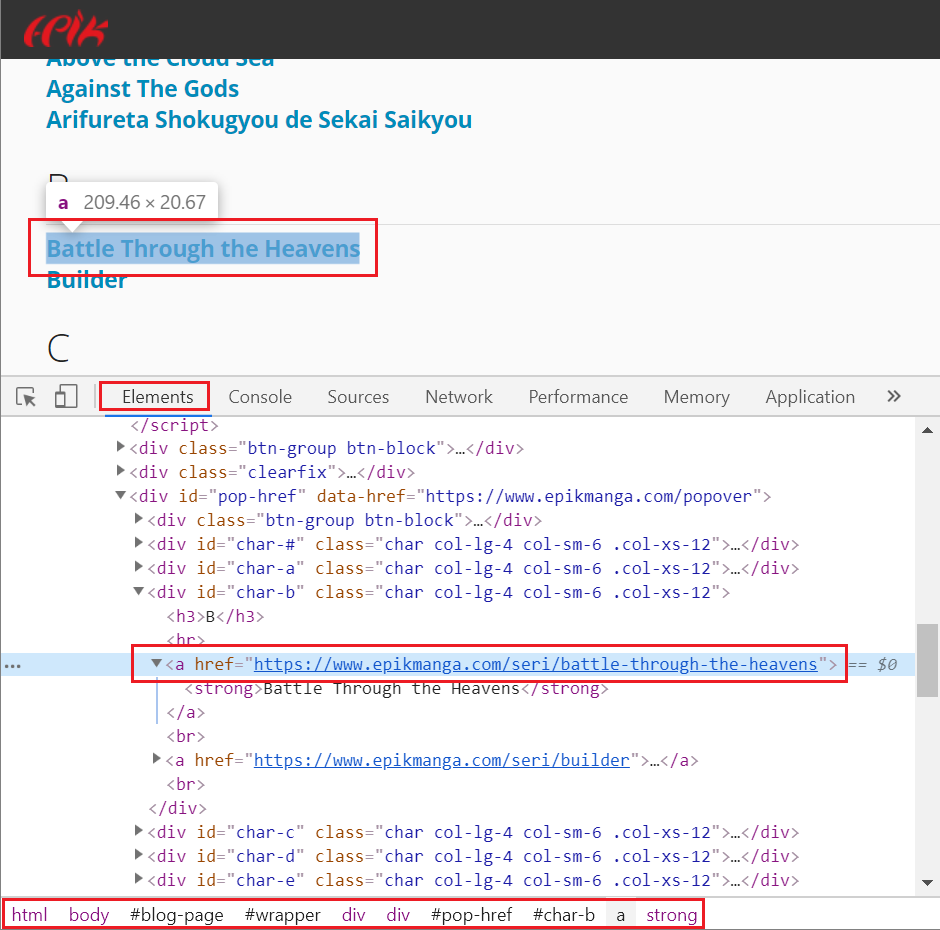
It will provide the URL for each manga which can be used as id and also the name which can can used as title.
Fortunately the base class provides the fetchDOM(request, query, retries) convenience method to fetch a web page, build the DOM, run a CSS query and returns a Promise with the list of all matching nodes when resolved, or an error when rejected.
This method requires an object of type Request as first parameter.
To create a request we need two things, an URL and some options to configure the request.
The manga list URL is known, it can be assembled by this.url + '/seri-listesi?type=text' (remember the url field was assigned in constructor).
The base class also provides some default requestOptions which can be used.
The only thing that is left is to convert the node list into a list of manga objects which can be done by simple mapping of the received JavaScript array.
Since we don’t know what type of link we get in the anchor element (USVString, absolute, relative, protocol independent, …), we could use another convenience method from the base class.
The method getRootRelativeOrAbsoluteLink(reference, base) will return a relative path if the link points hostname of the given base URL, otherwise the full qualified name will be returned.
Putting all this together and turn it into code will look like this:
async _getMangas() {
let request = new Request(this.url + '/seri-listesi?type=text', this.requestOptions);
let data = await this.fetchDOM(request, 'div#pop-href div[id^=char-] a');
return data.map(element => {
return {
id: this.getRootRelativeOrAbsoluteLink(element, this.url),
title: element.text.trim()
};
});
}Now start or reload HakuNeko again and synchronize the manga list. Instead of the fake entries, the mangas from the website are now shown correctly.
At this point HakuNeko can get the manga list from the website, but when selecting a manga, the chapter loading fails (as expected).
So the next step would be to overwrite our second method from the base class _getChapters(manga).
This method is invoked whenever HakuNeko requests the chapter list, e.g. when the user selects a manga from the manga list.
It will receive the manga object parameter.
The manga object is one from the list that we created in our first method, so we know it has an id and a title property.
Based on the id of the manga object we now need to find the corresponding chapters (and thats why it is so important to provide a useful id in the first method, because we are now the consumer of this property).
The method is async and must return the list of chapters that were scraped from the website.
The list is a collection of simple chapter objects, where each object has an id, a title and a language property, all of type string.
The id must be set to something that we can use later to determine the images belonging to the chapter, usually this would be the path of the URL for the chapter page on the website (e.g. /seri/god-of-martial-arts/bolum/22).
The title is the number or/and the name of the chapter that will be shown in the UI and also the name of the folder/archive when downloading the corresponding images.
|
ℹ️
|
Keep in mind that the implementation shown in this tutorial is just an example. It is completely up to the individual developer how to implement the body of the _getChapters(manga) method. In the end all that matters is, that the method returns a chapterList or in case of failure throws an error.
|
Lets start again with a simple fake implementation to see how it works. First we create a dummy chapter list and then we relay it to HakuNeko. This time we add some spice by including manga specific information such as the title. Change the corresponding method of our website scraper file to the following code:
async _getChapters(manga) {
return [
{
id: manga.id + '/ch1',
title: manga.title + ' - Chapter 001'
},
{
id: manga.id + '/ch2',
title: manga.title + ' - Chapter 002'
}
];
}After changing the source code, start HakuNeko (or reload the application if already running), select our added website scraper and select any of the manga from the list. The result should look like this:
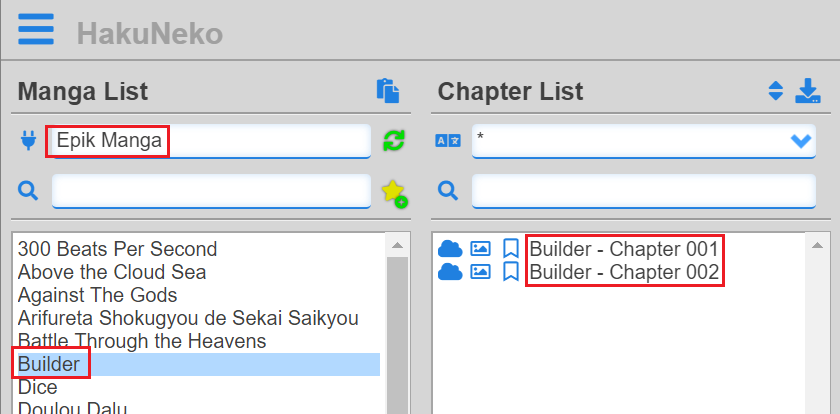
I’m pretty sure you already guess what is coming next.
Time to implement this method for real, so lets open and investigate any chapter page on the website.
After a brief analysis i came up with the table.table tbody tr td:first-of-type a CSS query to find the chapter links on the page.
We already discussed all the related stuff in Get the Manga List from the Website, except the language property which was not present in the manga object.
This property is exclusively used for filtering the chapter list by language in the UI, usually you can just assign an empty string to it.
It would only be helpful for websites that have chapters in different languages for the same manga (e.g. MangaDex).
In this case you also need to extract the language for each chapter from the website.
Ok, it’s time to update our method to get the chapter list.
async _getChapters(manga) {
let request = new Request(this.url + manga.id, this.requestOptions);
let data = await this.fetchDOM(request, 'table.table tbody tr td:first-of-type a');
return data.map(element => {
return {
id: this.getRootRelativeOrAbsoluteLink(element, this.url),
title: element.text.trim(),
language: ''
};
});
}To verify if the chapters are correctly found, start or reload HakuNeko, select our added website scraper and select any of the manga from the list. Instead of the fake entries, the chapters from the manga are now shown correctly.
Almost there, but we still need to add the functionality to download the images for a chapter.
To achieve this, the method _getPages(chapter) needs to be filled with something useful.
This method is invoked whenever HakuNeko requests the page list, e.g. when the user want to preview or download a chapter from the chapter list.
It will receive the manga object, the chapter object and a callback function as parameters, which will relay our scraping result back to HakuNeko when our operation is complete.
The chapter object is one of those from the list that we created in our second method, so we know it has the id and title property.
Additionally the chapter contains the manga property, which is the same as of the first method and provides an id and a title.
Based on the id of the chapter and maybe the manga object, we now need to find the corresponding images (and thats why it is so important to provide a useful id in the first and second method, because we are now the consumer of this property).
The method is async and must return the list of pages that were scraped from the website.
The list is a collection of simple image links of type string (USVString).
|
ℹ️
|
Keep in mind that the implementation shown in this tutorial is just an example. It is completely up to the individual developer how to implement the body of the _getPages(chapter) method. In the end all that matters is, that the method returns a pageList or in case of failure throws an error.
|
|
|
When using CSS query to find all image elements in the DOM, you need to use the tag source instead of img. The method fetchDOM will internally replace the img tags to improve loading performance.
|
As usual we start with a simple fake implementation to see how it works. First we create a dummy image link list and then we relay it to HakuNeko. Change the corresponding method of our website scraper file to the following code:
async _getPages(chapter) {
return [
'https://www.epikmanga.com/upload/manga/god-of-martial-arts/1.1/02.jpg',
'https://www.epikmanga.com/upload/manga/god-of-martial-arts/1.1/04.jpg'
];
}Start HakuNeko and see for yourself that every chapter should now provide the same two dummy images.
After this it is time for the real deal, jump to the browser and open any chapter of the website to investigate how we can get those precious images.
After a brief analysis i came up with the div#reader div.chapter-content source.chapter-img CSS query to find the image links on the page.
This time we are extracting the FQN of the URI as opposed to the manga and chapter ID where we dropped the origin part of the URI.
The base class provides the method getAbsolutePath(reference, base) which helps us to resolve the image link correctly (in case they are relative URIs).
The adjusted code to extract the image links may look like this:
async _getPages(chapter) {
let request = new Request(this.url + chapter.id, this.requestOptions);
let data = await this.fetchDOM(request, 'div#reader div.chapter-content source.chapter-img');
return data.map(element => this.getAbsolutePath(element, request.url));
}And again, start or reload HakuNeko and select our added website scraper and select any of the manga from the list. Now click on the preview button of any chapter in the chapter list and see if the images are loaded correctly. Click the download button of any other chapter to verify that the download is also working correctly. Congratulations, another website scraper has found its way into HakuNeko.
When a user is pasting one or more manga links from the clipboard into HakuNeko, it is expected that the mangas will appear in the manga list and can be selected to show their corresponding chapters.
To provide this feature for a website scraper, the base method _getMangaFromURI(uri) must be implemented correctly.
The uri parameter is of type URL and contains the link pasted from the clipboard that matches the defined url of our website scraper.
The method is async and must return a Manga instance.
To get access to the Manga class we need to import the corresponding module at the top of our website scraper.
import Manga from '../engine/Manga.mjs';And after that we are going for another dummy implementation that will always provide a valid manga for any link of our website scraper that is pasted into HakuNeko.
async _getMangaFromURI(uri) {
let id = '/seri/god-of-martial-arts';
let title = 'God of Martial Arts';
return new Manga(this, id, title);
}Start HakuNeko and simply paste a fake link such as https://www.epikmanga.com/dummy to see our dummy implementation in action.
After that we are focusing on the correct implementation.
The goal is to extract the correct manga ID and title from the uri that was provided from the clipboard.
The manga ID and the title properties should match the ones that are extracted in Get the Manga List from the Website.
Head over to your web-browser and open a manga link that just might had been pasted from the clipboard.
On the page try to extract the ID and the title.
In our example we can simply use the path of the pasted uri parameter as ID, there is no need to scrape the page for information we already had at hand.
For the title the CSS query head title can be used, but it needs some post processing to cleanup and remove some unwanted crap.
The resulting source code may look like this:
async _getMangaFromURI(uri) {
let request = new Request(uri, this.requestOptions);
let data = await this.fetchDOM(request, 'head title');
let id = uri.pathname;
let title = data[0].text.split(' | ')[0].trim();
return new Manga(this, id, title);
}Start HakuNeko and paste some manga links of the website such as:
https://www.epikmanga.com/seri/god-of-martial-arts
https://www.epikmanga.com/seri/the-portal-of-wonderlandFor the sake of completeness here the code of all parts glued together.
import Connector from '../engine/Connector.mjs';
import Manga from '../engine/Manga.mjs';
export default class EpikManga extends Connector {
constructor() {
super();
super.id = 'epikmanga';
super.label = 'Epik Manga';
this.tags = [ 'webtoon', 'turkish' ];
this.url = 'https://www.epikmanga.com';
}
async _getMangaFromURI(uri) {
let request = new Request(uri, this.requestOptions);
let data = await this.fetchDOM(request, 'head title');
let id = uri.pathname;
let title = data[0].text.split(' | ')[0].trim();
return new Manga(this, id, title);
}
async _getMangas() {
let request = new Request(this.url + '/seri-listesi?type=text', this.requestOptions);
let data = await this.fetchDOM(request, 'div#pop-href div[id^=char-] a');
return data.map(element => {
return {
id: this.getRootRelativeOrAbsoluteLink(element, this.url),
title: element.text.trim()
};
});
}
async _getChapters(manga) {
let request = new Request(this.url + manga.id, this.requestOptions);
let data = await this.fetchDOM(request, 'table.table tbody tr td:first-of-type a');
return data.map(element => {
return {
id: this.getRootRelativeOrAbsoluteLink(element, this.url),
title: element.text.trim(),
language: ''
};
});
}
async _getPages(chapter) {
let request = new Request(this.url + chapter.id, this.requestOptions);
let data = await this.fetchDOM(request, 'div#reader div.chapter-content source.chapter-img');
return data.map(element => this.getAbsolutePath(element, request.url));
}
}After implementing a new webscraper it is a good idea to also add a very simple automated test to continuously ensure its correctness.
The file Connectors.e2e.js located in /src/tests is meant to keep a very basic smoke test for each website scraper.
The tests are based on the Jest testing framework which is quite similar to other testing frameworks such as Mocha.
Furthermore Puppeteer is used to run sophisticated end to end tests directly in electron.
Fortunatley you don’t need to start writing a test from scratch as Connectors.e2e.js already provides a generic method to simplify this process and keep the tests consistent.
The method is named assertConnector(browserPage, parameters, expectations) and you simply call this method from within your test with the corresponding parameters of your website scraper and the related expected values.
In our case we want to assert the website with ID epikmanga by requesting the manga from the URL https://www.epikmanga.com/seri/battle-through-the-heavens and get the image links for the chapter that is at the end of the chapter list.
Most of the expected values should be self explaining from the source code below.
The pageMatcher is a regular expression that must match each image link of the tested chapter to pass the test.
it('should support EpikManga', async () => {
await assertConnector(page, {
connectorID: 'epikmanga',
mangaURL: 'https://www.epikmanga.com/seri/battle-through-the-heavens',
chaptersMethod: 'pop' // first => shift, last => pop
}, {
connectorClass: 'EpikManga',
mangaTitle: 'Battle Through the Heavens',
chapterTitle: '#1 Artık Dahi Değil',
pageCount: 20,
pageMatcher: /^https:\/\/www\.epikmanga.com\/upload\/manga\/battle-through-the-heavens\/1\/\d+.jpg$/
});
});Sometimes the desired information is not available on a single page, but scattered over multiple pages. This is often happens when trying to get the list of mangas for a certain website. In this case we have to scrape over multiple pages to accumulate the data and reduce it into a single result.
COMING SOON
This chapter explains the use case when the image links cannot be used directly, because the images are encrypted or require a certain setup of the HTTP protocl (e.g. header fields such as referer).
In this case providing the direct image link will not work, so we need our connector to take care of it.
Fortunately electron provides a simple mechanism to solve this issue: custom protocols.
So instead of https://…; which is used to request the image data we can use something like image://… with a registered custom handler that provides the image data.
In HakuNeko the custom protocol is connector://.
Each request using this protocol is automatically resolved to find the corresponding handler by using the origin from the request as match criteria for the connector ID, e.g. the request connector://kissmanga/… would use the connector with the ID kissmanga to process this request.
The request may contain a payload parameter which consists of a base64 encoded JSON string providing additional information for the request connector://kissmanga?payload=ABC123 (e.g. the resource URL of the encrypted image).
Each connector which shall support custom protocol handling must overwrite the base method async _handleConnectorURI(payload).
This method takes the de-serialized payload object from the request parameter as argument and must return a mime-typed data object as response data for the request.
Since the connector which consumes the request is probably also responsible for creating the request, the base class provides the method createConnectorURI(PayloadData) which return the corresponding custom protocol URL for a given serializable object.
crunchymanga
// Assumption this code is in a connector with the ID 'crunchymanga'
// Furthermore each image from this connector is XOR encrypted (or something like that)
async _getPages(chapter) {
// some pre-processing here ...
let imageLinks = [ /* some direct https lniks to encrypted images */ ];
// now transform all direct image links to protocol links of the pattern:
// 'connector://crunchymanga?payload=...'
// where payload is a base64 encoded object containing the original image URL and an encryption key
return imageLinks.map(link => this.createConnectorURI({ url: link, key: 123 }));
}
async _handleConnectorURI(payload) {
// remember the structure of the payload object which was created with 'createConnectorURI(payload)'
// the properties of this structure can now being directly accessed
let response = await fetch(payload.url)
let encrypted = await response.arrayBuffer();
return {
// be smart and use the original mime-type for the decrypted image ;)
mimeType: response.headers.get('content-type'),
data: this._decrypt(encrypted , payload.key)
};
}
_decrypt(buffer, key) {
// ... do the decryption stuff and return an array buffer
return new Uint8Array();
}At this point you probably have implemented your website scraper and it is working as expected. In the heat of the moment you probably want to push it, so it can be released as soon as possible. But to ensure the quality of HakuNeko it is a good idea to run some simple checks first.
The linter simply performs a static code analysis and checks for simple problems and code formatting. This is not done to detect errors in an early stage before entering the build pipeline and to keep the code format somewhat consistent over the whole code base. Run the following command and check the output carefully for warnings or errors:
npm run lintI’m pretty sure you have done a good job and there are almot none to zero complaints from the linter. Let’s head over to the second stage.
At this point you probably have already performed manual tests to see if your webscraper works as expected. But just in case it is a good idea to also check if it didn’t accidentally break something. This can be done with the two following commands:
npm run testDo not be surprised by HakuNeko popping up during the tests and doing some weird stuff, these are the automated end to end tests. After a while (go eat something or watch an anime episode) the tests will be completed and you may check the results in the terminal. Don’t worry for skipped tests as they may not be exeuted on your current platform and operating system. Take a closer look if some of the tests failed and check if this could be caused by your changes.