This is the code release for the paper Object-Centric Learning for Real-World Videos by Predicting Temporal Feature Similarities (NeurIPS 2023), by Andrii Zadaianchuk, Maximilian Seitzer and Georg Martius.
- Webpage: https://martius-lab.github.io/videosaur
- Arxiv: https://arxiv.org/abs/2306.04829
- OpenReview: https://openreview.net/forum?id=t1jLRFvBqm
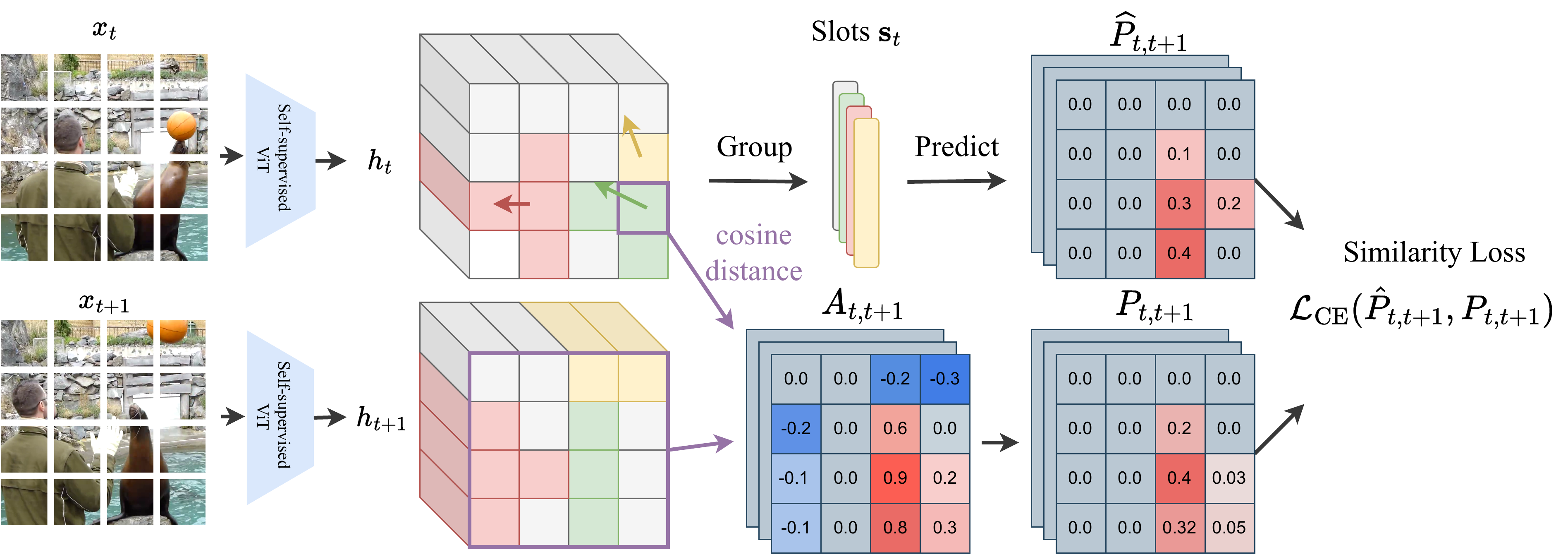
Unsupervised video-based object-centric learning is a promising avenue to learn structured representations from large, unlabeled video collections, but previous approaches have only managed to scale to real-world datasets in restricted domains. Recently, it was shown that the reconstruction of pre-trained self-supervised features leads to object-centric representations on unconstrained real-world image datasets. Building on this approach, we propose a novel way to use such pre-trained features in the form of a temporal feature similarity loss. This loss encodes semantic and temporal correlations between image patches and is a natural way to introduce a motion bias for object discovery. We demonstrate that this loss leads to state-of-the-art performance on the challenging synthetic MOVi datasets. When used in combination with the feature reconstruction loss, our model is the first object-centric video model that scales to unconstrained video datasets such as YouTube-VIS.
First, setup the python environment setup. We use Poetry for this:
poetry install
Then you could run a test configuration to see if everything works:
poetry run python -m videosaur.train tests/configs/test_dummy_image.yml
Second, to download the datasets used in this work, follow the instructions in data/README.md.
By default, datasets are expected to be contained in the folder ./data.
You can change this to the actual folder your data is in by setting the environment variable VIDEOSAUR_DATA_PATH, or by running train.py with the --data-dir option.
Run one of the configurations in configs/videosaur, for example:
poetry run python -m videosaur.train configs/videosaur/movi_c.yml
The results are stored in a folder created under the log root folder (by defaults ./logs, changeable by the argument --log-dir).
If you want to continue training from a previous run, you can use the --continue argument, like in the following command:
poetry run python -m videosaur.train --continue <path_to_log_dir_or_checkpoint_file> configs/videosaur/movi_c.yml
If you want to run one of the released checkpoints (see below) on your own video you can use inference script with corresponding config file:
poetry run python -m videosaur.inference --config configs/inference/movi_c.yml
in the released config, please change checkpoint: path/to/videosaur-movi-c.ckpt to the real path to your checkpoint.
For different video formats you would need to modify corresponding transformations in build_inference_transform function.
We list the results you should roughly be able to obtain with the configs included in this repository:
| Dataset | Model Variant | Video ARI | Video mBO | Config | Checkpoint Link |
|---|---|---|---|---|---|
| MOVi-C | ViT-B/8, DINO | 64.8 | 38.9 | videosaur/movi_c.yml | Checkpoint |
| MOVi-E | ViT-B/8, DINO | 73.9 | 35.6 | videosaur/movi_e.yml | Checkpoint |
| YT-VIS 2021 | ViT-B/16, DINO | 39.5 | 29.1 | videosaur/ytvis.yml | Checkpoint |
| YT-VIS 2021 | ViT-B/14, DINOv2 | 39.7 | 35.6 | videosaur/ytvis_dinov2.yml | Checkpoint |
We also include a configuration for the DINOSAUR model from our previous paper Bridging the gap to real-world object-centric learning. This configuration yields improved results compared to the DINOSAUR model in the original paper (mainly due to using DINOv2 pre-trained features). Note that there might be minor differences in the metrics, as the numbers here are computed for 224x224 masks, compared to 320x320 masks in the DINOSAUR paper.
| Dataset | Model Variant | Image ARI | Image mBO | Config | Checkpoint |
|---|---|---|---|---|---|
| COCO | ViT-B/14, DINOv2 | 45.6 | 29.6 | dinosaur/coco_base14_dinov2.yml | Checkpoint |
If you make use of this repository, please use the following bibtex entry to cite us:
@inproceedings{zadaianchuk2023objectcentric,
title={Object-Centric Learning for Real-World Videos by Predicting Temporal Feature Similarities},
author={Zadaianchuk, Andrii and Seitzer, Maximilian and Martius, Georg},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023)},
year={2023},
}
This codebase is released under the MIT license. Some parts of the codebase were adapted from other codebases. A comment was added to the code where this is the case. Those parts are governed by their respective licenses.