一个简单的文章爬虫工具,采用python3开发。
可以爬取文章的标题、头图、正文、作者名称、作者头像、摘录。
支持将爬取的数据保存到数据库,并将图片上传到对象存储,替换原来的图片链接。
大体上思路是这样的
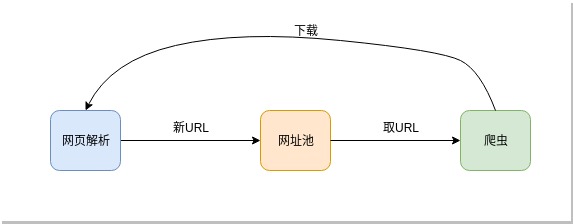
需求环境
- Python 3.6.3或以上
- MySQL
- 阿里云oss对象存储(非必须)
1.克隆项目
git clone https://github.com/miansen/article-spider.git
2.安装依赖的模块
pip install -r requirements.txt
3.新建数据库article_spider
数据库建表脚本在init.sql这个文件里
4.修改配置文件application.cfg
将你的数据库信息和oss信息添加上去,阿里云OSS不是必须的,没有的话可以不用填。
5.添加爬虫配置
把需要爬取的网站的数据添加到crawler_hub表里,各个字段都有注释。
6.验证配置
配置信息添加完之后,输入以下命令验证配置是否正确
python VerifyConfiguration.py [hub_id]
如图所示则说明配置正确

7.启动数据爬虫
python Application.py
欢迎大家提 issues,谢谢!
MIT