This repo provides a python library, hub, for building services that use the processed data from the LBRY blockchain in an ongoing manner. Hub contains a set of three core executable services that are used together:
scribe(hub.scribe.service) - maintains a rocksdb database containing the LBRY blockchain.herald(hub.herald.service) - an electrum server for thin-wallet clients (such as lbry-sdk), provides an api for clients to use thin simple-payment-verification (spv) wallets and to resolve and search claims published to the LBRY blockchain. A drop in replacement port of herald written in go - herald.go is currently being worked on.scribe-elastic-sync(hub.elastic_sync.service) - a utility to maintain an elasticsearch database of metadata for claims in the LBRY blockchain
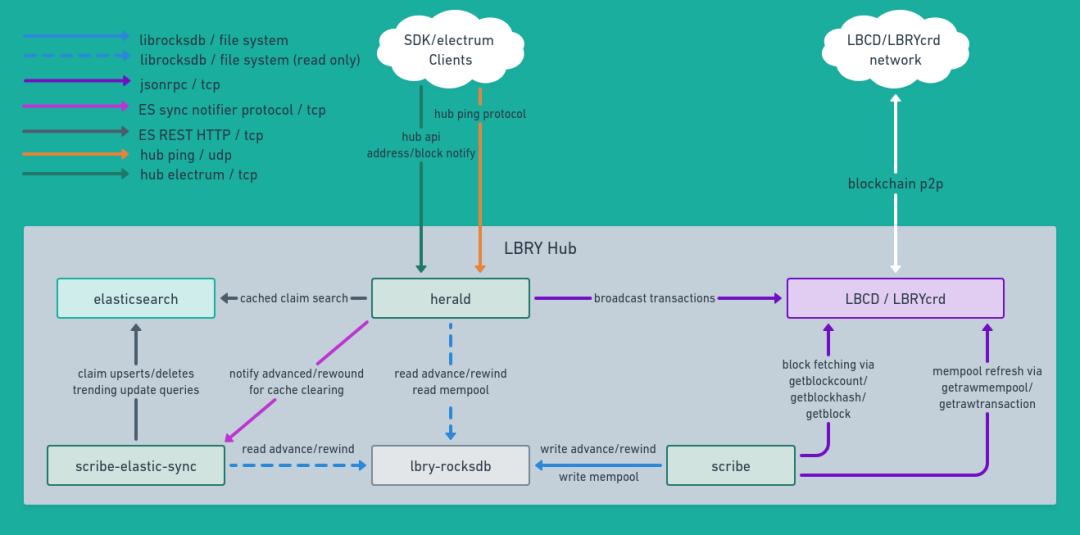
Features and overview of hub as a python library:
- Uses Python 3.7-3.9 (3.10 probably works but hasn't yet been tested)
- An interface developers may implement in order to build their own applications able to receive up-to-date blockchain data in an ongoing manner (hub.service.BlockchainReaderService)
- Protobuf schema for encoding and decoding metadata stored on the blockchain (hub.schema)
- Rocksdb 6.25.3 based database containing the blockchain data (hub.db)
- A community driven performant trending algorithm for searching claims (code)
Scribe may be run from source, a binary, or a docker image. Our releases page contains pre-built binaries of the latest release, pre-releases, and past releases for macOS and Debian-based Linux. Prebuilt docker images are also available.
docker pull lbry/hub:master
git clone https://github.com/lbryio/hub.git
cd hub
docker build -t lbry/hub:development .
Scribe has been tested with python 3.7-3.9. Higher versions probably work but have not yet been tested.
- clone the scribe repo
git clone https://github.com/lbryio/hub.git
cd hub
- make a virtual env
python3.9 -m venv hub-venv
- from the virtual env, install scribe
source hub-venv/bin/activate
pip install -e .
That completes the installation, now you should have the commands scribe, scribe-elastic-sync and herald
These can also optionally be run with python -m hub.scribe, python -m hub.elastic_sync, and python -m hub.herald
Scribe needs elasticsearch and either the lbrycrd or lbcd blockchain daemon to be running.
With options for high performance, if you have 64gb of memory and 12 cores, everything can be run on the same machine. However, the recommended way is with elasticsearch on one instance with 8gb of memory and at least 4 cores dedicated to it and the blockchain daemon on another with 16gb of memory and at least 4 cores. Then the scribe hub services can be run their own instance with between 16 and 32gb of memory (depending on settings) and 8 cores.
As of block 1147423 (4/21/22) the size of the scribe rocksdb database is 120GB and the size of the elasticsearch volume is 63GB.
The recommended way to run a scribe hub is with docker. See this guide for instructions.
If you have the resources to run all of the services on one machine (at least 300gb of fast storage, preferably nvme, 64gb of RAM, 12 fast cores), see this docker-compose example.
For various reasons it may be desirable to block or filtering content from claim search and resolve results, here are instructions for how to configure and use this feature as well as information about the recommended defaults.
--db_dir(required) Path of the directory containing lbry-rocksdb, set from the environment withDB_DIRECTORY--daemon_url(required forscribeandherald) URL for rpc from lbrycrd or lbcd:@.--reorg_limitMax reorg depth, defaults to 200, set from the environment withREORG_LIMIT.--chainWith blockchain to use - eithermainnet,testnet, orregtest- set from the environment withNET--max_query_workersSize of the thread pool, set from the environment withMAX_QUERY_WORKERS--cache_all_tx_hashesIf this flag is set, all tx hashes will be stored in memory. Forscribe, this speeds up the rate it can apply blocks as well as process mempool. Forherald, this will speed up syncing address histories. This setting will use 10+g of memory. It can be set from the environment withCACHE_ALL_TX_HASHES=Yes--cache_all_claim_txosIf this flag is set, all claim txos will be indexed in memory. Set from the environment withCACHE_ALL_CLAIM_TXOS=Yes--prometheus_portIf provided this port will be used to provide prometheus metrics, set from the environment withPROMETHEUS_PORT
--db_max_open_filesThis setting translates into the max_open_files option given to rocksdb. A higher number will use more memory. Defaults to 64.--address_history_cache_sizeThe count of items in the address history cache used for processing blocks and mempool updates. A higher number will use more memory, shouldn't ever need to be higher than 10000. Defaults to 1000.--index_address_statusesMaintain an index of the statuses of address transaction histories, this makes handling notifications for transactions in a block uniformly fast at the expense of more time to process new blocks and somewhat more disk space (~10gb as of block 1161417).
--reindexIf this flag is set drop and rebuild the elasticsearch index.
--hostInterface for server to listen on, use 0.0.0.0 to listen on the external interface. Can be set from the environment withHOST--tcp_portElectrum TCP port to listen on for hub server. Can be set from the environment withTCP_PORT--udp_portUDP port to listen on for hub server. Can be set from the environment withUDP_PORT--elastic_servicesComma separated list of items in the formatelastic_host:elastic_port/notifier_host:notifier_port. Can be set from the environment withELASTIC_SERVICES--query_timeout_msTimeout for claim searches in elasticsearch in milliseconds. Can be set from the environment withQUERY_TIMEOUT_MS--blocking_channel_idsSpace separated list of channel claim ids used for blocking. Claims that are reposted by these channels can't be resolved or returned in search results. Can be set from the environment withBLOCKING_CHANNEL_IDS.--filtering_channel_idsSpace separated list of channel claim ids used for blocking. Claims that are reposted by these channels aren't returned in search results. Can be set from the environment withFILTERING_CHANNEL_IDS--index_address_statusesUse the address history status index, this makes handling notifications for transactions in a block uniformly fast (must be turned on inscribetoo).
Contributions to this project are welcome, encouraged, and compensated. For more details, please check this link.
This project is MIT licensed. For the full license, see LICENSE.
We take security seriously. Please contact [email protected] regarding any security issues. Our PGP key is here if you need it.
The primary contact for this project is @jackrobison.