{kind=link}
Данный программный продукт является однопроходным компилятором. Применяется для компиляции программы, написанной на разработанном языке в программу на ассемблере. Программа написана на языке программирования высокого уровня – Python версии 2.7.6. Программа написана в рамках курсовой работы для дисциплины "Системное программное обеспечение".
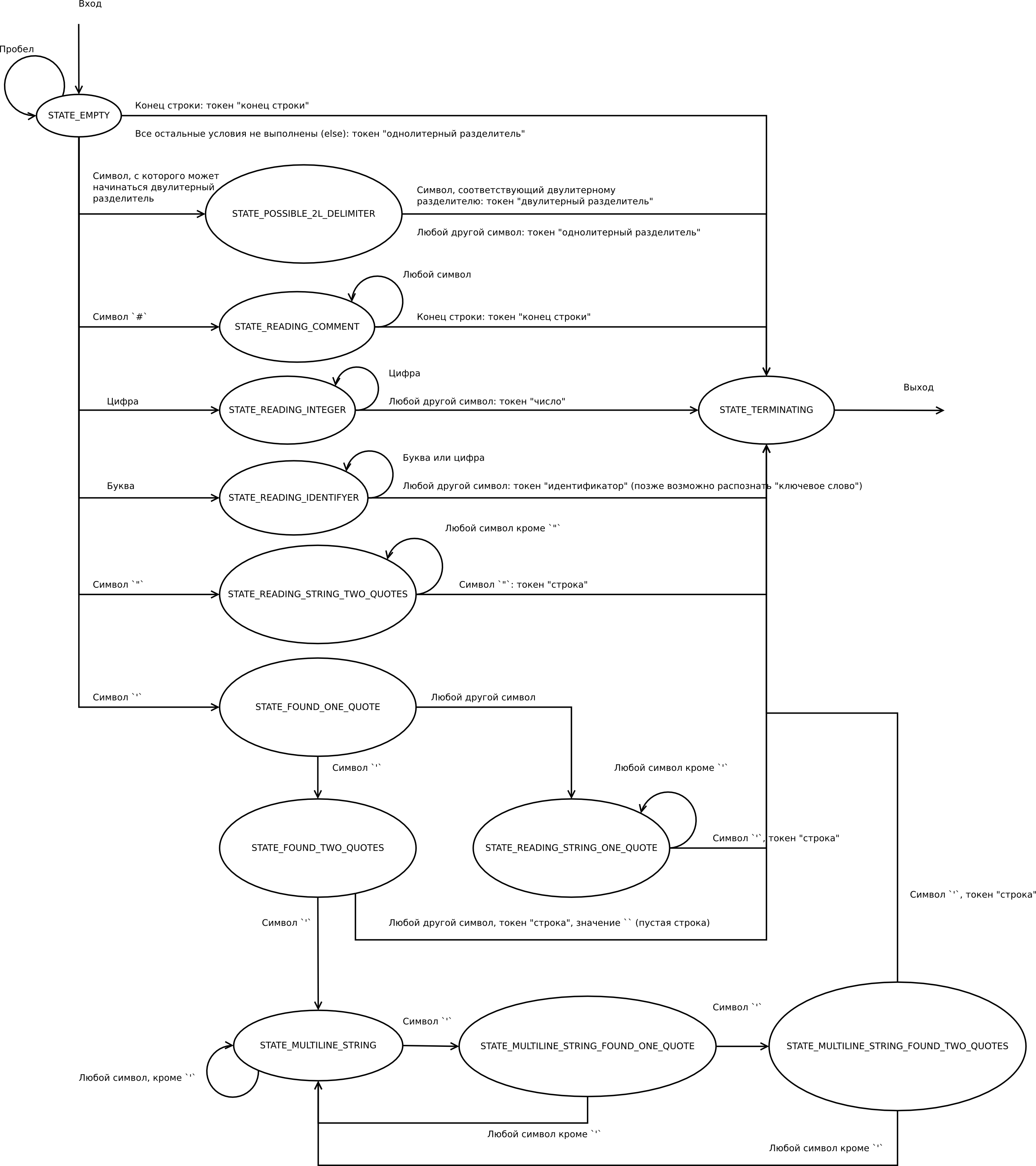
Лексический анализатор — часть транслятора, выполняющая разбиение исходного текста программы на смысловые единицы (лексемы), такие как идентификаторы, целые числа, строки в кавычках и т. д. Конечная цель лексического анализа заключается в том, чтобы упростить конструкцию синтаксического анализатора, который будет работать уже не с символами исходного текста, а с лексемами.
Данный лексический анализатор написан на основе конечного автомата, который был построен на основе автоматной грамматики, упрощенно повторяющей таковую для языка Python. Правила этой автоматной грамматики следующие:
- L → <цифра>N | <буква>I | `"`T | `'`O | `#`C | ` `L | `;`L | `>`F1 | `<`F2 | `=`F3 | `!`F4 | <конец строки>S | <другой символ>D
- N → <цифра> N | ε
- I → <буква>I | <цифра>I | ε
- T → <любой символ> T | `"` T2
- T2 → ε
- O → `'` O2 | <любой другой символ>
- Q → <любой символ> Q | `'` Q2
- Q2 → ε
- O2 → `'` M | <любой другой символ> Q2
- M → `'` EM1 | <любой другой символ> M
- EM1 → `'` EM2 | <любой другой символ> M
- EM2 → `'` EM3 | <любой другой символ> M
- EM3 → ε
- C → <любой символ> C | <конец строки> S
- F1 → `=`G1 | <любой другой символ> D
- F2 → `=`G2 | <любой другой символ> D
- F3 → `=`G3 | <любой другой символ> D
- F4 → `=`G4 | <любой другой символ> D
- G1 → ε
- G2 → ε
- G3 → ε
- G4 → ε
- D → ε
- S → ε
Таким образом, лексический анализатор разбивает текст на следующие лексемы:
- идентификаторы
- целые числа
- строки в 'одинарных' и "двойных" кавычках
- многострочные строки/комментарии в '''трех одинарных кавычках'''
- двулитерные разделители «>=» «<=» «==» и «!=»
- однолитерные разделители
- конец строки, который должен быть распознан как разделитель команд (в соответствии с синтаксисом языка)
Анализатор также корректно обрабатывает однострочные комментарии, начинающиеся с #решетки и игнорирует их.
Роль многострочных комментариев в языке Python выполняют многострочные строковые выражения, заключаемые в '''тройные одинарные кавычки''' и не присваиваемые никакой переменной. Из обработки они исключаются на этапе синтаксического анализа.
Лексический анализатор был написан на интерпретируемом языке высокого уровня Python версии 2.6.
Анализатор также реализует возможность «подглядывать», возвращая следующий токен, но не считывая его и не перемещаясь по тексту. Делается это с помощью присваивания параметра pry=True во входных данных анализатора. Эта возможность необходима для реализации синтаксического анализатора.
Схема работы лексического анализатора:
Синтаксический анализатор — часть транслятора, проверяющая соответствие исходного текста грамматике языка программирования. Вход синтаксического анализатора — последовательность лексем. Выход — дерево разбора.
Большинство методов синтаксического анализа принадлежит к одному из двух классов: нисходящие анализаторы, которым соответствуют LL-грамматики, и восходящие, которым соответствуют LR-грамматики.
Одним из наиболее простых и потому одним из наиболее популярных способов нисходящего синтаксического анализа является метод рекурсивного спуска. Он реализуется путем взаимного вызова анализирующих процедур, кажая из которых соответствует одному из правил грамматики.
Для реализации синтаксического анализа была создана своя грамматика. Пример исходного кода, соответствующий этой грамматике:
print('hello world')
int a = 10
int b = 5
array of int f[3] = [1, 2+2, a*2]
array of char g[f[0]]
for int c = 1 to 100 step b+c
{
a = a*c
print('hello' + to_str(a))
if (b/2) != 0 {
b += 1
}else { b -= 2 }
}
do {a += 1}
dowhile a < 1000 #это комментарий
'''
это
многострочный
комментарий
'''
while a >= 20 {
a -= f[0]
print(to_str(a * f[f[1]]))
}
Правила для этой грамматики следующие (полужирным выделены терминальные символы):
- text -> codestring {EOSTRING codestring}
- codestring -> (expression | array_declaration | codewhile | codefor | codeif | dowhile | procedure | `{` text `}` | empty)
- empty -> (`}` | | ε)
- expression -> (type | ε) assignment expression2
- array_declaration -> `array` `of` type `[` `]` (`=` array_const | `filled` `with` expression2)
- type -> (`int` | `char` | `string` | `boolean`)
- assignment -> (`=` | `+=` | `-=` | `*=` | `/=` | `=`)
- expression2 -> expression3 {operator expression3}
- operator -> (`+` | `-` | `*` | `/` | `\` | `>` | `<` | `>=` | `<=` | `==` | `!=` | `and` | `or` | `xor` )
- expression3 -> (`not`| ε) ( `(` expression2 `)` | | | | procedure)
- array_const -> `[` expression2 {`,` expression2} `]`
- codewhile -> `while` expression2 (EOSTRING|ε) codestring
- codefor -> `for` expression `to` expression2 (`step` expression2 | ε) (EOSTRING|ε) codestring
- codeif -> `if` expression2 (EOSTRING|ε) codestring
- dowhile -> `do` (EOSTRING|ε) codestring (EOSTRING|ε) `dowhile` expression2
- procedure -> procedure_id `(` expression2 `)`
- procedure_id -> (`print` | `write` `read` | `examine` | `to_int` | `to_str` | `to_char` | `to_bool` | `asm`)
где EOSTRING — токен конца строки.
Синтаксический анализатор использует лексический анализатор в виде модуля lexical.