

一款基于Nonebot2的插件
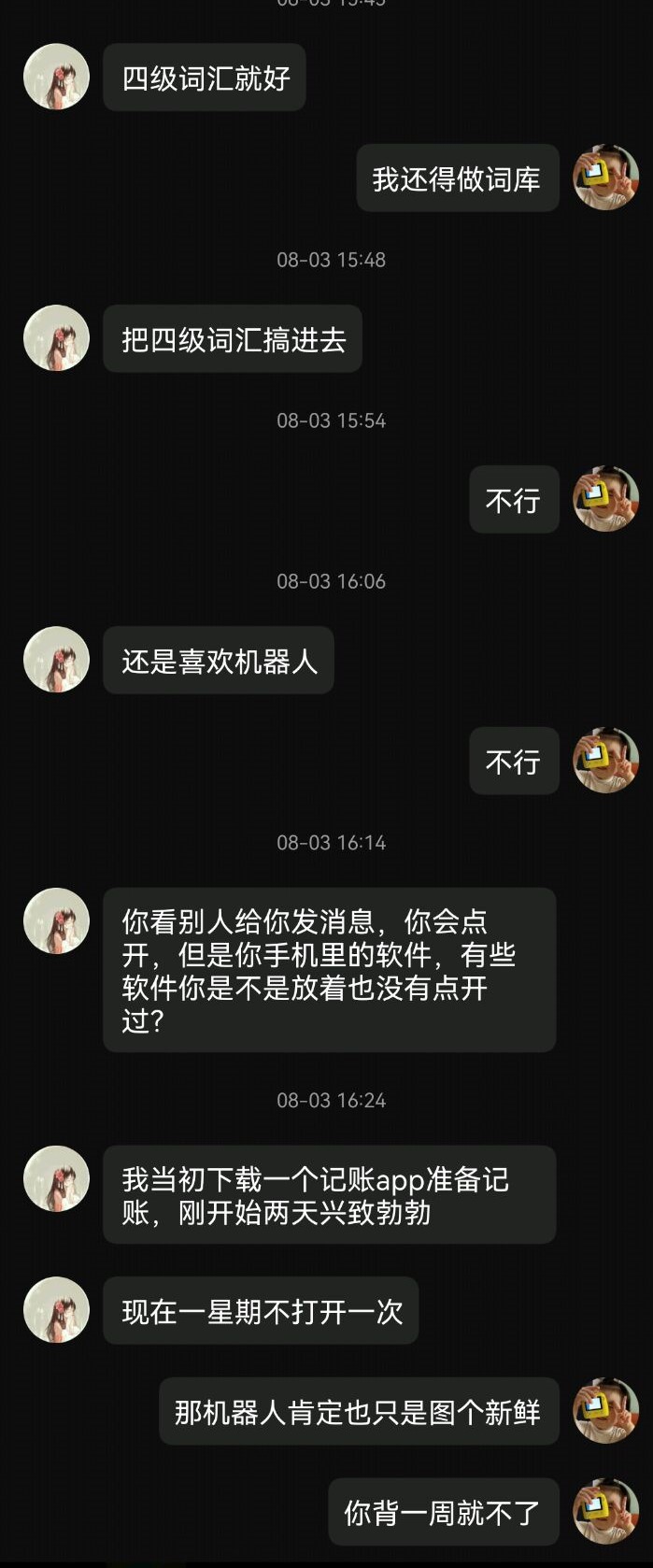
不是吧,真的有人拿QQ背单词么?!
功能是朋友提的,这个功能我感觉很鸡肋, 我一直习惯于APP背单词,推荐几款软件
- 电脑:Uahh/ToastFish: 一个利用摸鱼时间背单词的软件(少有且好用的电脑端单词软件!)
- 手机:扇贝单词、不背单词
- 平板:欧陆词典(功能强大!)
但她说别人发消息QQ高频点开,这个理由好像也挺有道理,所以简单做了一个机器人插件。但无论什么方式,重在坚持!
py小白,如果有任何问题、建议,欢迎issues
pip install nonebot_plugin_wordsnorote在bot.py中添加
nonebot.load_plugin("nonebot_plugin_wordsnorote")在.env(如:.env.dev)中配置参数说明
| config | type | default | example | usage |
|---|---|---|---|---|
| num_words | int | 20 | num_words = 50 | 每日推送单词数量,默认20 |
每一个QQ号相当于一个ID,数据保存在data/wordsnoreote/student.json,其中wordID即所背单词数量
因为我面向的是大学生,所以默认词库是考研英语,kajweb/dict仓库已将有道数据整理,包括小学到大学的课本、四六级、考研、雅思...,81本书,小张不可能做到本本都兼容,所以写了一些转格式代码,方便大家换书
- 从仓库中下载词库
- 运行仓库中
turn_json.py转格式(注意英标是否乱码,推荐在Mac或Linux环境下运行,微软编码默认GBK)并遍历一遍数据,查看是否有缺失 - 运行仓库中
fix_keys.py填补缺失数据(以考研词库缺失例句与发音为例,根据实际情况修改try...expect异常) - 将词库重命名并放在
data/wordsnorote/wordbook.json
如果转格式失败,你也可以通过issue留下词库的 名字\id (只要源文件缺的东西不多,可以修复,小张抽空可以帮忙弄一下)
已转格式的词库在本仓库Dict\已整理词库下
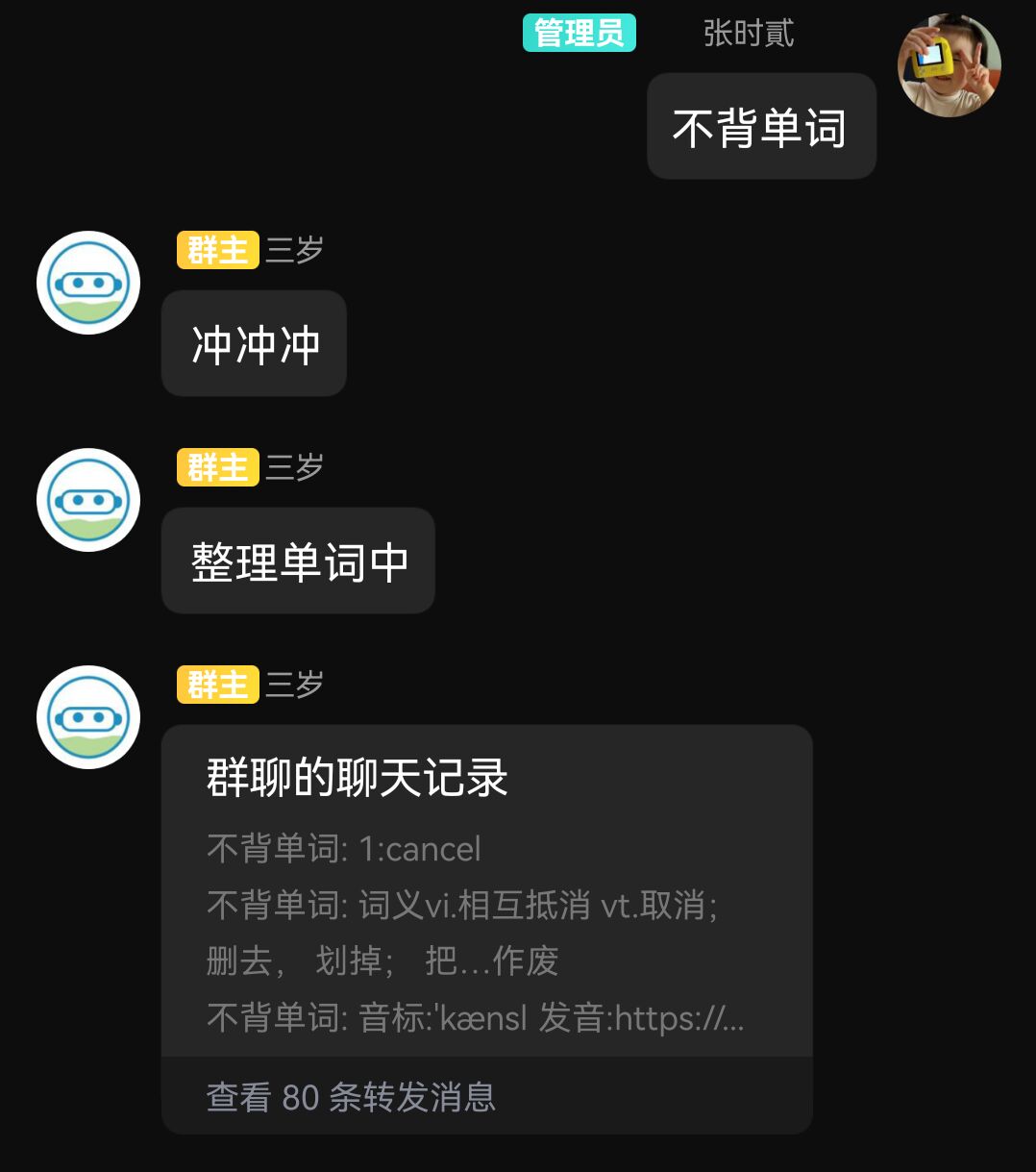
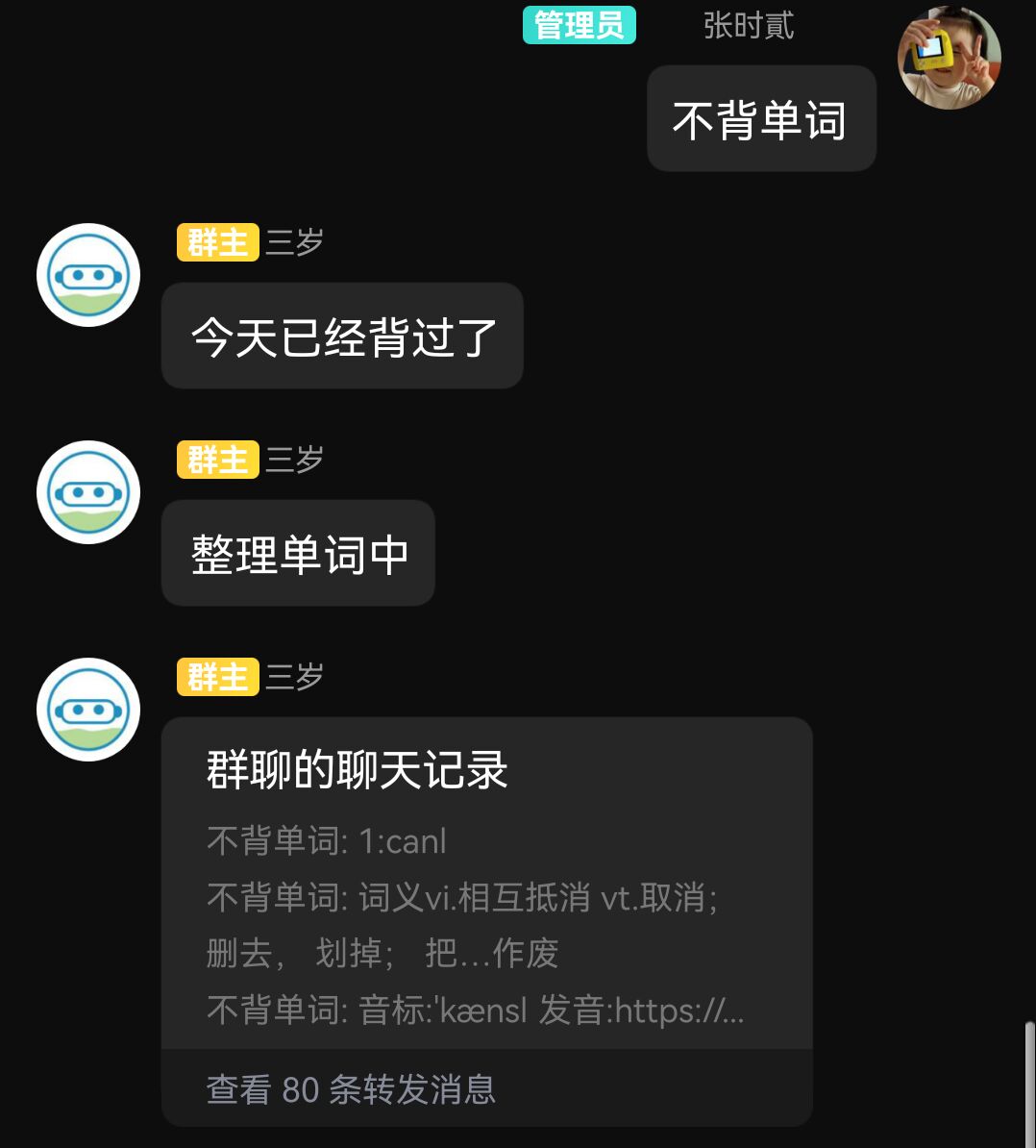
2022.8.29,开始本地构建(local_test文件夹)。编写词库转格式与修复。实现插件化:修改所有文件读写路径,增加自定义单词数量、自定义词库功能
2022.8.30,反复测试,QQ合并转发不能超过100条,重构逻辑,发布至商店
未来可能添加的功能
- 添加复习功能,暂且构思为:发送单词ID范围,例如
复习x~y,将x~y顺序重排打乱,先发送一条只包含单词的合并消息,再发送一条答案的合并消息。优势:自由指定复习范围,相对于只复习昨日的单词灵活一些