technologyMahout
Mahout will be used to do the heavy-lifting regarding to recommendation.
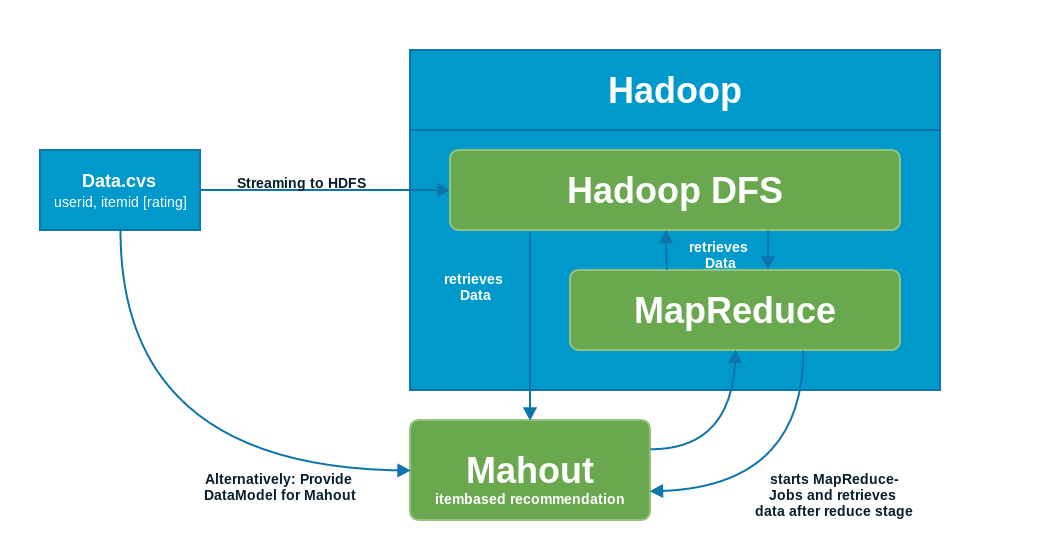
One possible task for mahout is the computation of item-based recommendation. To do this, mahout needs data including userid, itemid and an optional rating for the designated item. Each line of a dataset describes the preference between each user and a entity.
Mahout can read plain cvs files and will run on top of a hadoop cluster and uses the MapReduce-Paradigm provided by Hadoop.
- How will the data (preferences) be stored inside HDFS?
- HBase (schema has to be defined, data provider neccessary)
- "plain" HDFS files (data provider neccessary)
- How will be data be streamed to Mahout, if it's stored within HDFS (see here) .
- How to ensure, that Mahout runs on top of a preconfigured Hadoop installation.
- What metrics will be used to calculate the recommendations