An r/wallstreetbets web scraper. Blog post located here.
Start by cloning the repository then updating python with dependencies found in requirements.txt
git clone https://github.com/rmcsqrd/yolo-scrape.git
python3 -m venv [venv name]
source [venv name]/bin/activate
pip install -r requirements.txt
To use the agent, you'll need to setup a Reddit app/script. This link has pretty good instructions on how to do this in Reddit. Once you have app/script created, rename config/dummy_config.ini to config/config.ini and update the credentials with the reddit scraper client_id, client_secret, and user_agent values.
Modify the dates you want to scrape between in config/config.ini. The input parameters are in Unix epoch time form. This is a helpful converter. Run the script from the root directory by typing:
python3 src/yolo_scrape.py
You'll have an option to restart or resume the script as prompted by the user input. If you don't have an existing .csv file of previously scraped data, the resume option will not work. This saves into a .csv file.
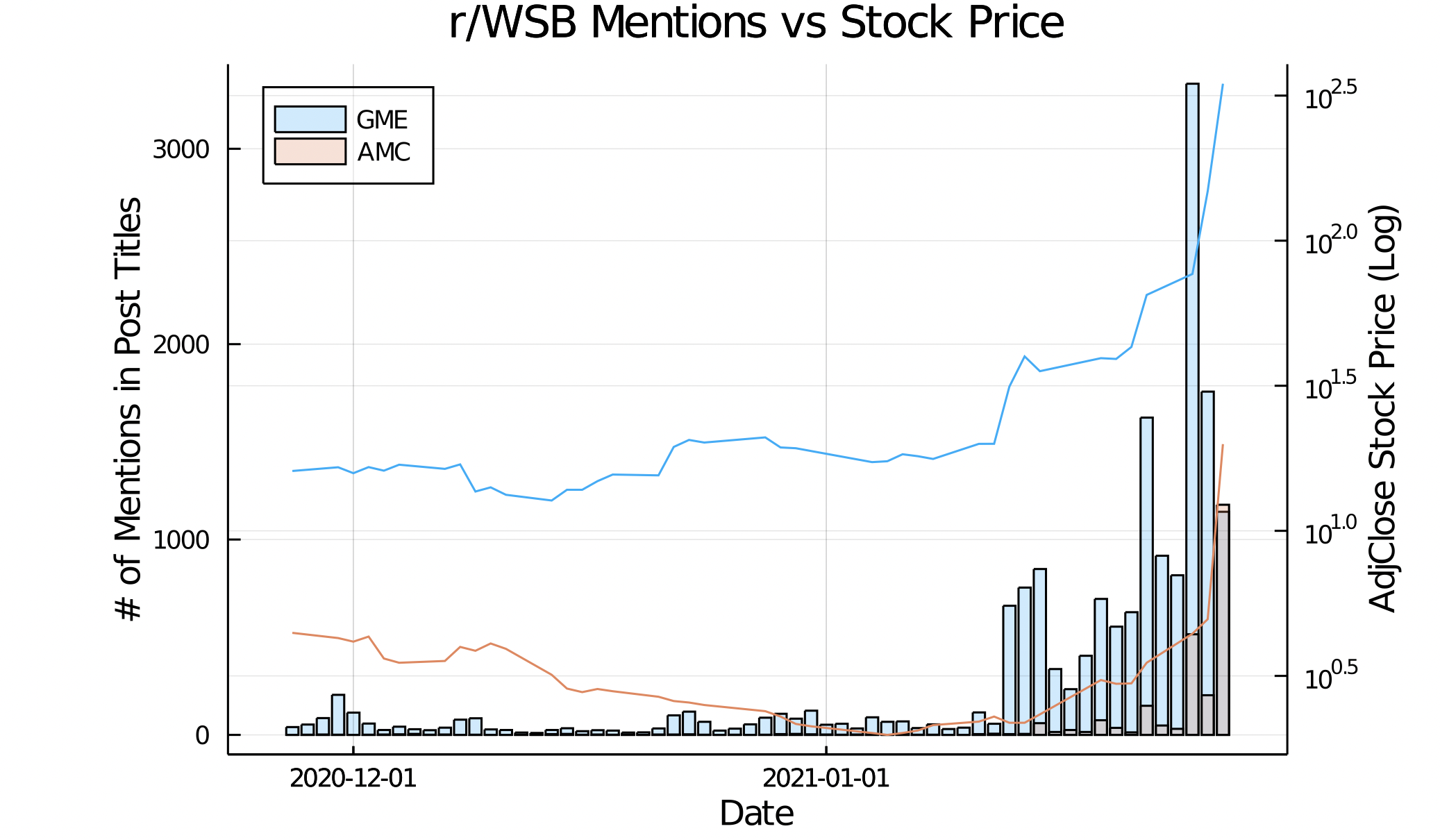
Above is some example output that was created in conjunction with ryssdal.jl.