
SQL Explorer aims to make the flow of data between people fast, simple, and confusion-free. It is a Django-based application that you can add to an existing Django site, or use as a standalone business intelligence tool.
Quickly write and share SQL queries in a simple, usable SQL editor, preview the results in the browser, share links, download CSV, JSON, or Excel files (and even expose queries as API endpoints, if desired), and keep the information flowing!
Comes with support for multiple connections, to many different SQL database types, a schema explorer, query history (e.g. lightweight version control), a basic security model, in-browser pivot tables, and more.
SQL Explorer values simplicity, intuitive use, unobtrusiveness, stability, and the principle of least surprise.
SQL Explorer is inspired by any number of great query and reporting tools out there.
The original idea came from Stack Exchange's Data Explorer, but also owes credit to similar projects like Redash and Blazer.
Sql Explorer is MIT licensed, and pull requests are welcome.
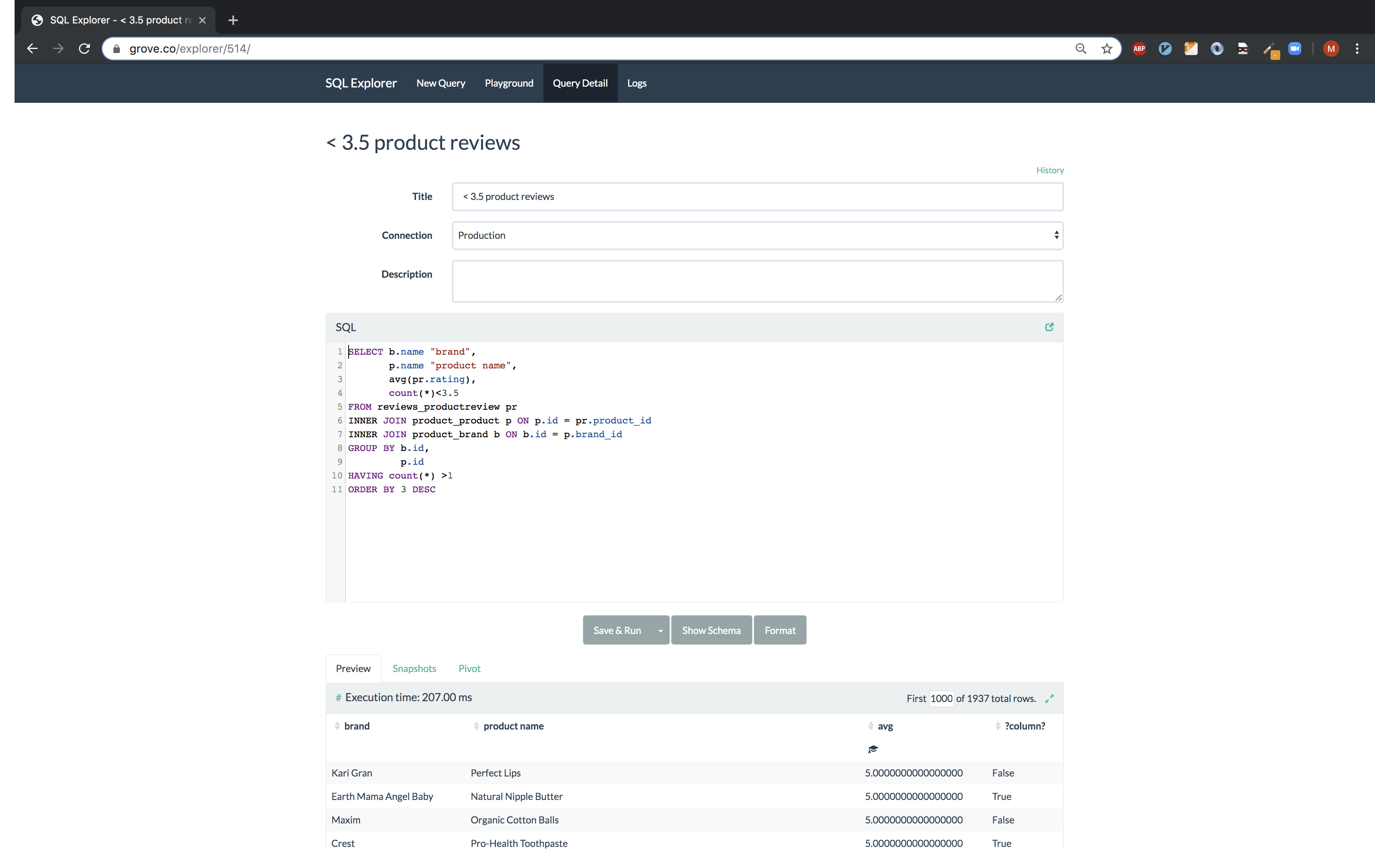
A view of a query
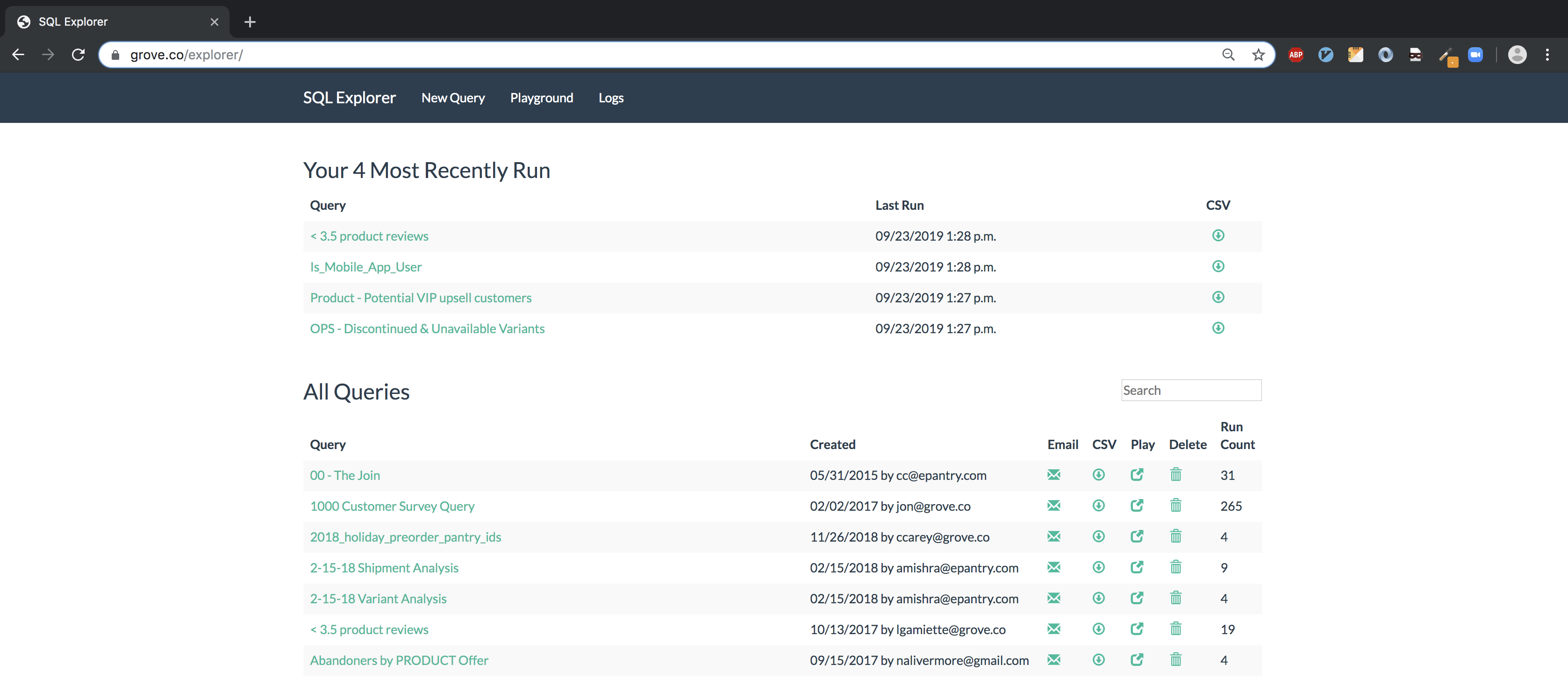
Viewing all queries
Quick access to DB schema info

Snapshot query results to S3 & download as csv

-
- Security
-
- Let's not kid ourselves - this tool is all about giving people access to running SQL in production. So if that makes you nervous (and it should) - you've been warned. Explorer makes an effort to not allow terrible things to happen, but be careful! It's recommended you use the EXPLORER_CONNECTION_NAME setting to connect SQL Explorer to a read-only database role.
- Explorer supports two different permission checks for users of the tool. Users passing the EXPLORER_PERMISSION_CHANGE test can create, edit, delete, and execute queries. Users who do not pass this test but pass the EXPLORER_PERMISSION_VIEW test can only execute queries. Other users cannot access any part of Explorer. Both permission groups are set to is_staff by default and can be overridden in your settings file.
- Enforces a SQL blacklist so destructive queries don't get executed (delete, drop, alter, update etc). This is not bulletproof and it's recommended that you instead configure a read-only database role, but when not possible the blacklist provides reasonable protection.
-
- Easy to get started
-
- Built on Django's ORM, so works with Postgresql, Mysql, and Sqlite. And, between you and me, it works fine on RedShift as well.
- Small number of dependencies.
- Just want to get in and write some ad-hoc queries? Go nuts with the Playground area.
-
- Snapshots
-
- Tick the 'snapshot' box on a query, and Explorer will upload a .csv snapshot of the query results to S3. Configure the snapshot frequency via a celery cron task, e.g. for daily at 1am:
'explorer.tasks.snapshot_queries': { 'task': 'explorer.tasks.snapshot_queries', 'schedule': crontab(hour=1, minute=0) }
- Requires celery, obviously. Also uses djcelery and tinys3. All of these deps are optional and can be installed with pip install -r optional-requirements.txt
- The checkbox for opting a query into a snapshot is ALL THE WAY on the bottom of the query view (underneath the results table).
- You must also have the setting EXPLORER_TASKS_ENABLED enabled.
-
- Email query results
-
- Click the email icon in the query listing view, enter an email address, and the query results (zipped .csv) will be sent to you asynchronously. Very handy for long-running queries.
-
- Parameterized Queries
-
- Use
$$foo$$ in your queries and Explorer will build a UI to fill out parameters. When viewing a query like 'SELECT * FROM table WHERE id=$$id$$', Explorer will generate UI for the 'id' parameter. - Parameters are stashed in the URL, so you can share links to parameterized queries with colleagues
- Use
$$paramName:defaultValue$$ to provide default values for the parameters.
- Use
-
- Schema Helper
-
- /explorer/schema/<connection-alias> renders a list of your table and column names + types that you can refer to while writing queries. Apps can be excluded from this list so users aren't bogged down with tons of irrelevant tables. See settings documentation below for details.
- This is available quickly as a sidebar helper while composing queries (see screenshot)
- Quick search for the tables you are looking for. Just start typing!
- Explorer uses Django DB introspection to generate the schema. This can sometimes be slow, as it issues a separate query for each table it introspects. Therefore, once generated, Explorer caches the schema information. There is also the option to generate the schema information asyncronously, via Celery. To enable this, make sure Celery is installed and configured, and set EXPLORER_ENABLE_TASKS and EXPLORER_ASYNC_SCHEMA to True.
-
- Template Columns
-
- Let's say you have a query like 'select id, email from user' and you'd like to quickly drill through to the profile page for each user in the result. You can create a "template" column to do just that.
- Just set up a template column in your settings file:
EXPLORER_TRANSFORMS = [('user', '<a href="https://yoursite.com/profile/{0}/">{0}</a>')]- And change your query to 'SELECT id AS "user", email FROM user'. Explorer will match the "user" column alias to the transform and merge each cell in that column into the template string. Cool!
- Note you must set EXPLORER_UNSAFE_RENDERING to True if you want to see rendered HTML (vs string literals) in the output. And be aware of the implications of enabling that setting.
-
- Pivot Table
-
- Go to the Pivot tab on query results to use the in-browser pivot functionality (provided by Pivottable JS).
- Hit the link icon on the top right to get a URL to recreate the exact pivot setup to share with colleagues.
-
- Query Logs
-
- Explorer will save a snapshot of every query you execute so you can recover lost ad-hoc queries, and see what you've been querying.
- This also serves as cheap-and-dirty versioning of Queries, and provides the 'run count' property and average duration in milliseconds, by aggregating the logs.
- You can also quickly share playground queries by copying the link to the playground's query log record -- look on the top right of the sql editor for the link icon.
- If Explorer gets a lot of use, the logs can get beefy. explorer.tasks contains the 'truncate_querylogs' task that will remove log entries older than <days> (30 days and older in the example below).
'explorer.tasks.truncate_querylogs': { 'task': 'explorer.tasks.truncate_querylogs', 'schedule': crontab(hour=1, minute=0), 'kwargs': {'days': 30} }
-
- Multiple Connections
-
- Have data in more than one database? No problemo. Just set up multiple Django database connections, register them with Explorer, and you can write, save, and view queries against all of your different data sources. Compatible with any database support by Django. Note that the target database does not have to contain any Django schema, or be related to Django in any way. See connections.py for more documentation on multi-connection setup.
-
- Power tips
-
-
On the query listing page, focus gets set to a search box so you can just navigate to /explorer and start typing the name of your query to find it.
-
Quick search also works after hitting "Show Schema" on a query view.
-
Command+Enter and Ctrl+Enter will execute a query when typing in the SQL editor area.
-
Hit the "Format" button to format and clean up your SQL (this is non-validating -- just formatting).
-
Use the Query Logs feature to share one-time queries that aren't worth creating a persistent query for. Just run your SQL in the playground, then navigate to /logs and share the link (e.g. /explorer/play/?querylog_id=2428)
-
Click the 'history' link towards the top-right of a saved query to filter the logs down to changes to just that query.
-
If you need to download a query as something other than csv but don't want to globally change delimiters via settings.EXPLORER_CSV_DELIMETER, you can use /query/download?delim=| to get a pipe (or whatever) delimited file. For a tab-delimited file, use delim=tab. Note that the file extension will remain .csv
-
If a query is taking a long time to run (perhaps timing out) and you want to get in there to optimize it, go to /query/123/?show=0. You'll see the normal query detail page, but the query won't execute.
-
Set env vars for EXPLORER_TOKEN_AUTH_ENABLED=TRUE and EXPLORER_TOKEN=<SOME TOKEN> and you have an instant data API. Just:
curl --header "X-API-TOKEN: <TOKEN>" https://www.your-site.com/explorer/<QUERY_ID>/stream?format=csvYou can also pass the token with a query parameter like this:
curl https://www.your-site.com/explorer/<QUERY_ID>/stream?format=csv&token=<TOKEN>
-
Requires Python 2.7, 3.4, or 3.5. Requires Django 1.7.1 or higher.
Set up a Django project with the following:
`bash
$ pip install django
$ django-admin startproject project
`
More information [here](https://docs.djangoproject.com/en/1.11/intro/tutorial01/).
Install with pip from github:
pip install django-sql-explorer
Add to your INSTALLED_APPS, located in the settings.py file in your project folder:
INSTALLED_APPS = (
...,
'explorer',
...
)
Add the following to your urls.py (all Explorer URLs are restricted via the EXPLORER_PERMISSION_VIEW and EXPLORER_PERMISSION_CHANGE settings. See Settings section below for further documentation.):
url(r'^explorer/', include('explorer.urls')),
Run migrate to create the tables:
python manage.py migrate
Lastly, configure your settings to something like:
EXPLORER_CONNECTIONS = { 'Default': 'readonly' }
EXPLORER_DEFAULT_CONNECTION = 'readonly'
The first setting lists the connections you want to allow Explorer to use. The keys of the connections dictionary are friendly names to show Explorer users, and the values are the actual database aliases used in settings.DATABASES. It is highly recommended to set
You can now browse to https://yoursite/explorer/ and get exploring! It is highly recommended that you also configure Explorer to use a read-only database connection via the EXPLORER_CONNECTION_NAME setting.
There are a handful of features (snapshots, emailing queries) that rely on Celery and the dependencies in optional-requirements.txt. If you have Celery installed, set EXPLORER_TASKS_ENABLED=True in your settings.py to enable these features.
An effort has been made to keep the number of dependencies to a minimum.
Python
| Name | Version | License |
|---|---|---|
| six | 1.12.0 | MIT |
| sqlparse | 0.3.0 | BSD |
| unicodecsv | 0.14.1 | BSD |
- six is used for py2-3 compatibility
- sqlparse is used for SQL formatting
Python - Optional Dependencies
| Name | Version | License |
|---|---|---|
| celery | 3.1 | BSD |
| django-celery | 3.1 | BSD |
| Factory Boy | 2.12.0 | MIT |
| xlsxwriter | 1.2.1 | BSD |
| boto | 2.46 | MIT |
- Factory Boy is required for tests
- celery is required for the 'email' feature, and for snapshots
- boto is required for snapshots
- xlsxwriter is required for Excel export (csv still works fine without it)
JavaScript
| Name | Version | License |
|---|---|---|
| Twitter Boostrap | 3.3.6 | MIT |
| jQuery | 2.1.4 | MIT |
| jQuery Cookie | 1.4.1 | MIT |
| jQuery UI | 1.11.4 | MIT |
| Underscore | 1.7.0 | MIT |
| Codemirror | 5.15.2 | MIT |
| floatThead | 1.4.0 | MIT |
| list.js | 1.2.0 | MIT |
| pivottable.js | 2.0.2 | MIT |
- All all served from CDNJS except for jQuery UI, which uses a custom build, served locally.
pivottable.js relies on jQuery UI but only for the Sortable method.
Factory Boy is needed if you'd like to run the tests, which can you do easily:
python manage.py test
and with coverage:
coverage run --source='.' manage.py test
then:
coverage report
...99%! Huzzah!
There is also a test_project that you can use to kick the tires. Just create a new virtualenv, cd into test_project and run start.sh (or walk through the steps yourself) to get a test instance of the app up and running.
| Setting | Description | Default |
|---|---|---|
| EXPLORER_SQL_BLACKLIST | Disallowed words in SQL queries to prevent destructive actions. | ('ALTER', 'RENAME ', 'DROP', 'TRUNCATE', 'INSERT INTO', 'UPDATE', 'REPLACE', 'DELETE', 'ALTER', 'CREATE TABLE', 'SCHEMA', 'GRANT', 'OWNER TO') |
| EXPLORER_SQL_WHITELIST | These phrases are allowed, even though part of the phrase appears in the blacklist. | ('CREATED', 'UPDATED', 'DELETED','REGEXP_REPLACE') |
| EXPLORER_DEFAULT_ROWS | The number of rows to show by default in the preview pane. | 1000 |
| EXPLORER_SCHEMA_INCLUDE_TABLE_PREFIXES | If not None, show schema only for tables starting with these prefixes. "Wins" if in conflict with EXCLUDE | None # shows all tables |
| EXPLORER_SCHEMA_EXCLUDE_TABLE_PREFIXES | Don't show schema for tables starting with these prefixes, in the schema helper. | ('django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.admin') |
| EXPLORER_SCHEMA_INCLUDE_VIEWS | Include database views | False |
| EXPLORER_ASYNC_SCHEMA | Generate DB schema asynchronously. Requires Celery and EXPLORER_TASKS_ENABLED | False |
| EXPLORER_CONNECTION_NAME | The name of the Django database connection to use. Ideally set this to a connection with read only permissions | None # Must be set for the app to work, as this is required |
| EXPLORER_CONNECTIONS | A dictionary of { 'Friendly Name': 'django_db_alias'}. All | {} # At a minimum, should be set to something like { 'Default': 'readonly' } or similar. See connections.py for more documentation. |
| EXPLORER_PERMISSION_VIEW | Callback to check if the user is allowed to view and execute stored queries | lambda u: u.is_staff |
| EXPLORER_PERMISSION_CHANGE | Callback to check if the user is allowed to add/change/delete queries | lambda u: u.is_staff |
| EXPLORER_TRANSFORMS | List of tuples like [('alias', 'Template for {0}')]. See features section of this doc for more info. | [] |
| EXPLORER_RECENT_QUERY_COUNT | The number of recent queries to show at the top of the query listing. | 10 |
| EXPLORER_GET_USER_QUERY_VIEWS | A dict granting view permissions on specific queries of the form {userId:[queryId, ...], ...} | {} |
| EXPLORER_TOKEN_AUTH_ENABLED | Bool indicating whether token-authenticated requests should be enabled. See "Power Tips", above. | False |
| EXPLORER_TOKEN | Access token for query results. | "CHANGEME" |
| EXPLORER_TASKS_ENABLED | Turn on if you want to use the snapshot_queries celery task, or email report functionality in tasks.py | False |
| EXPLORER_S3_ACCESS_KEY | S3 Access Key for snapshot upload | None |
| EXPLORER_S3_SECRET_KEY | S3 Secret Key for snapshot upload | None |
| EXPLORER_S3_BUCKET | S3 Bucket for snapshot upload | None |
| EXPLORER_FROM_EMAIL | The default 'from' address when using async report email functionality | "[email protected]" |
| EXPLORER_DATA_EXPORTERS | The export buttons to use. Default includes Excel, so xlsxwriter from optional-requirements.txt is needed | [('csv', 'explorer.exporters.CSVExporter'), ('excel', 'explorer.exporters.ExcelExporter'), ('json', 'explorer.exporters.JSONExporter')] |
| EXPLORER_UNSAFE_RENDERING | Disable autoescaping for rendering values from the database. Be wary of XSS attacks if querying unkown data... | False |
Release process is documented here. If there are problems with the release, please help me improve the process so it doesn't happen again!