Билет 26
Вопрос № 1: Выполнили Коркмасов Д.Д. ИДМ-18-01, Крюков А.С. ИДМ-18-01, Троц Н.В. ИДМ-18-01
Вопрос № 2: Выполнили Батухтин М.С. ИДМ-18-01
Вопрос 1. Понятие распределенных вычислений. Технологии организации распределенных вычислений. Особенности параллельных алгоритмов.
Область распределенных вычислений представляет собой раздел теории вычислительных систем, изучающий теоретические вопросы организации распределенных систем. Распределенные вычисления иногда определяют в более узком смысле, как применение распределенных систем для решения трудоемких вычислительных задач. В таком контексте распределенные вычисления являются частным случаем параллельных вычислений, т.е. одновременного решения различных частей одной вычислительной задачи несколькими вычислительными устройствами. Отметим, что при изучении параллельных вычислений основной акцент обычно делается на методах разделения решаемой задачи на подзадачи, которые могут рассчитываться одновременно для максимального ускорения вычислений. Основная же особенность в организации параллельных вычислений с использованием распределенных систем будет заключаться в необходимости учитывать различие характеристик доступных вычислительных устройств и наличие существенной временной задержки при обмене данными между ними.
В дальнейшем будем рассматривать распределенные вычисления в широком смысле, как теоретическую основу для построения распределенных систем обработки данных. Существует множество определений распределенной системы, причем ни одно из них не является строгим или общепринятым.
Весьма оригинальное определение принадлежит американскому ученому в области теории вычислительных систем Лесли Лэмпорту. Согласно его утверждению, вы понимаете, что пользуетесь распределенной системой, когда поломка компьютера, о существовании которого вы даже не подозревали, приводит к останову всей системы, а для вас – к невозможности выполнить свою работу. Значительная часть распределенных систем, к сожалению, удовлетворяет такому определению, однако, строго говоря, оно относится только к системам с единой точкой отказа.
В свою очередь хорошо известный российской аудитории профессор вычислительной техники Эндрю С. Таненбаум определяет распределенную систему как набор независимых компьютеров, представляющийся их пользователям единой объединенной системой. Здесь необходимо обратить внимание на то, что сами по себе независимые компьютеры не могут представляться пользователю единой системой. Обеспечить это можно только с помощью дополнительного специального программного обеспечения, называемого программным обеспечением промежуточного уровня (англ. middleware). Именно с его помощью пользователи полагают, что имеют дело с единой системой, а все различия между компьютерами и способы связи между ними остаются скрытыми для пользователей.
Распределенная система – это такая система, в которой взаимодействие и синхронизация программных компонентов, выполняемых на независимых сетевых компьютерах, осуществляется посредством передачи сообщений.
Распределенная система – набор независимых компьютеров, не имеющих общей совместно используемой памяти и общего единого времени (таймера) и взаимодействующих через коммуникационную сеть посредством передачи сообщений, где каждый компьютер использует свою собственную оперативную память и на котором выполняется отдельный экземпляр своей операционной системы. Однако эти операционные системы функционируют совместно, предоставляя свои службы друг другу для решения общей задачи.
Термин «распределенная система» описывает широкий спектр систем от слабо связанных многомашинных комплексов, представляемых, например, набором персональных компьютеров, объединенных в сеть, до сильно связанных многопроцессорных систем.
Мы будем рассматривать распределенную систему с аппаратной точки зрения в виде совокупности взаимосвязанных автономных компьютеров или процессоров, с программной точки зрения – в виде совокупности независимых процессов (исполняемых программных компонентов распределенной системы), взаимодействующих посредством передачи сообщений для обмена данными и координации своих действий.
Компьютеры, процессоры или процессы будем называть узлами распределенной системы. Чтобы процессоры могли считаться автономными, они должны, по меньшей мере, обладать собственным независимым управлением. По этой причине параллельный компьютер, архитектура которого устроена по схеме «одна команда для многих данных» (англ. Single Instruction - Multiple Data, SIMD), не может считаться распределенной системой.
Под независимостью процессов подразумевается тот факт, что каждый процесс имеет свое собственное состояние, представляемое набором данных, включающим текущие значения счетчика команд, регистров и переменных, к которым процесс может обращаться и которые может изменять. Состояние каждого процесса является полностью закрытым для других процессов: другие процессы не имеют к нему прямого доступа и не могут изменять его.
Скорости выполнения операций разных процессов в распределенной системе различны и заранее неизвестны, а доставка отправленных сообщений может занимать непредсказуемое время. Поскольку в качестве узлов системы могут выступать процессы, под приведенное нами определение подпадают также и программные системы, представляющие собой совокупность взаимодействующих процессов, выполняемых на одном и том же вычислительном устройстве. В этой ситуации каналы взаимодействия, осуществляющие передачу сообщений между процессами, реализуются с помощью разделяемой памяти вместо сети связи.
Однако в большинстве случаев в распределенной системе все же содержится несколько процессоров, взаимосвязанных друг с другом при помощи средств коммуникации.
Построение масштабируемых систем подразумевает решение широкого круга задач и часто сталкивается с ограничениями реализованных в вычислительных системах централизованных служб, данных и алгоритмов. А именно, многие службы централизованы в том смысле, что они реализованы в виде единственного процесса и могут выполняться только на одном компьютере (сервере). Проблема такого подхода заключается в том, что при увеличении числа пользователей или приложений, использующих эту службу, сервер, на котором она выполняется, станет узким местом и будет ограничивать общую производительность. Если даже предположить возможность неограниченного увеличения мощности такого сервера (вертикальное масштабирование), то тогда ограничивающим фактором станет пропускная способность линий связи, соединяющих его с остальными компонентами распределенной системы. Аналогично, централизация данных требует централизованной обработки, приводя к тем же самым ограничениям.
В качестве примера преимуществ децентрализованного подхода можно привести службу доменных имен (англ. Domain Name Service, DNS), которая на сегодняшний день является одной из самых больших распределенных систем именования. Служба DNS используется в первую очередь для поиска IP-адресов по доменному имени и обрабатывает миллионы запросов с компьютеров по всему миру. При этом распределенная база данных DNS поддерживается с помощью иерархии DNS-серверов, взаимодействующих по определенному протоколу. Если бы все данные DNS централизовано хранились бы на единственном сервере, и каждый запрос на интерпретацию доменного имени передавался бы на этот сервер, воспользоваться такой системой в масштабах всего мира было бы невозможно.
Отдельно стоит отметить ограничения, создаваемые применением централизованных алгоритмов. Дело в том, что централизованные алгоритмы для своей работы требуют получения всех входных данных и толькость распределенных систем, к сожалению, удовлетворяет такому определению, однако, строго говоря, оно относится только к си после этого производят соответствующие операции над ними, а уже затем распространяют результаты всем заинтересованным сторонам. С этой точки зрения проблемы использования централизованных алгоритмов эквивалентны рассмотренным выше проблемам централизации служб и данных. Поэтому для достижения хорошей масштабируемости следует применять распределенные алгоритмы, предусматривающие параллельное выполнение частей одного и того же алгоритма независимыми процессами.
В отличие от централизованных алгоритмов, распределенные алгоритмы обладают следующими свойствами, которые на самом деле значительно усложняют их проектирование и реализацию:
-
отсутствие знания глобального состояния. Как уже было сказано, централизованные алгоритмы обладают полной информацией о состоянии всей системы и определяют следующие действия, исходя из ее текущего состояния. В свою очередь, каждый процесс, реализующий часть распределенного алгоритма, имеет непосредственный доступ только к своему состоянию, но не к глобальному состоянию всей системы. Соответственно, процессы принимают решения только на основе своей локальной информации. Следует отметить, что информацию о состоянии других процессов в распределенной системе каждый процесс может получить только из пришедших сообщений, и эта информация может оказаться устаревшей на момент получения. Аналогичная ситуация имеет место в астрономии: знания об изучаемом объекте (звезде/галактике) формируются на основании светового и прочего электромагнитного излучения, и это излучение дает представление о состоянии объекта в прошлом. Например, знания об объекте, находящемся на расстоянии пяти тысяч световых лет, являются устаревшими на пять тысяч лет;
-
отсутствие общего единого времени. События, составляющие ход выполнения централизованного алгоритма полностью упорядочены: для любой пары событий можно с уверенностью утверждать, что одно из них произошло раньше другого. При выполнении распределенного алгоритма вследствие отсутствия единого для всех процессов времени, события нельзя считать полностью упорядоченными: для некоторых пар событий мы можем утверждать, какое из них произошло раньше другого, для других – нет;
-
отсутствие детерминизма. Централизованный алгоритм чаще всего определяется как строго детерминированная последовательность действий, описывающая процесс преобразования объекта из начального состояния в конечное. Если запускать централизованный алгоритм на выполнение с одним и тем же набором входных данных, будем получать один и тот же результат и одинаковую последовательность переходов из состояния в состояние. В свою очередь выполнение распределенного алгоритма носит недетерминированный характер из-за независимого исполнения процессов с различной и неизвестной скоростью, а также из-за случайных задержек передачи сообщений между ними. Поэтому, несмотря на то, что для распределенных систем может быть определено понятие глобального состояния, выполнение распределенного алгоритма может лишь ограниченно рассматриваться как переход из одного глобального состояния в другое;
-
устойчивость к отказам. Сбой в любом из процессов или каналов связи не должен вызывать нарушения работы распределенного алгоритма;
-
для обеспечения географической масштабируемости требуются свои подходы. Одна из основных причин плохой географической масштабируемости многих распределенных систем, разработанных для локальных сетей, заключается в том, что в их основе лежит принцип синхронной связи (англ. synchronous communication). В этом виде связи клиент, вызывающий какую-либо службу сервера, блокируется до получения ответа. Это неплохо работает, когда взаимодействие между процессами происходит быстро и незаметно для пользователя. Однако при увеличении задержки на обращение к удаленной службе в глобальной системе подобный подход становится все менее привлекательным и, очень часто, абсолютно неприемлемым. Другая сложность обеспечения географической масштабируемости состоит в том, что связь в глобальных сетях по своей природе ненадежна и взаимодействие процессов практически всегда является двухточечным (англ. point-to-point). В свою очередь, связь в локальных сетях является высоконадежной и подразумевает использование широковещательных сообщений, что значительно упрощает разработку распределенных приложений. Например, если процессу требуется обнаружить адрес другого процесса, предоставляющего определенную службу, в локальных сетях ему достаточно разослать широковещательное сообщение с просьбой для искомого процесса откликнуться на него. Все процессы получают и обрабатывают это сообщение. Но только процесс, предоставляющий требуемую службу, отвечает на полученную просьбу, указывая свой адрес в ответном сообщении. Очевидно, подобное взаимодействие перегружает сеть, и использовать его в глобальных сетях нереально.
Все современные браузеры поддерживают для этого «инструменты разработчика». Исправление ошибок с их помощью намного проще и быстрее.
На текущий момент самые многофункциональные инструменты – в браузере Chrome. Также очень хорош Firebug (для Firefox).
В вашей версии Chrome панель может выглядеть несколько по-иному, но что где находится, должно быть понятно.
Зайдите на страницу с примером браузером Chrome.
Откройте инструменты разработчика: F12 или в меню Инструменты > Инструменты Разработчика.
Выберите сверху Sources.

Вы видите три зоны:
- Зона исходных файлов. В ней находятся все подключённые к странице файлы, включая JS/CSS. Выберите pow.js, если он не выбран.
- Зона текста. В ней находится текст файлов.
- Зона информации и контроля. Мы поговорим о ней позже.

**Формат ** Нажатие форматирует текст текущего файла, расставляет отступы. Нужна, если вы хотите разобраться в чужом коде, плохо отформатированном или сжатом. Консоль Очень полезная кнопка, открывает тут же консоль для запуска команд. Можно смотреть код и тут же запускать функции. Её нажатие можно заменить на клавишу Esc. **Окно ** Если код очень большой, то можно вынести инструменты разработки вбок или в отдельное окно, зажав эту кнопку и выбрав соответствующий вариант из списка.
Открыли файл pow.js во вкладке Sources? Кликните на 6-й строке файла pow.js, прямо на цифре 6.
Поздравляю! Вы поставили точку останова или, как чаще говорят, «брейкпойнт».
Выглядеть это должно примерно так:
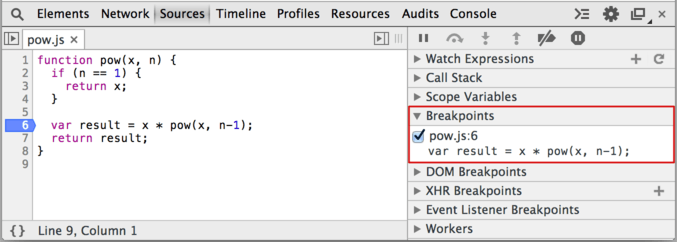
В остановленном коде можно посмотреть текущие значения переменных, выполнять команды и т.п., в общем – отлаживать его.
Вы можете видеть, что информация о точке останова появилась справа, в подвкладке Breakpoints.
Вкладка Breakpoints очень удобна, когда код большой, она позволяет:
- Быстро перейти на место кода, где стоит брейкпойнт кликом на текст.
- Временно выключить брейкпойнт кликом на чекбокс.
- Быстро удалить брейкпойнт правым кликом на текст и выбором Remove, и так далее.
- Дополнительные возможности Остановку можно инициировать и напрямую из кода скрипта, командой debugger:
function pow(x, n) {
...
debugger; // <-- отладчик остановится тут
...
}
Правый клик на номер строки pow.js позволит создать условную точку останова (conditional breakpoint), т.е. задать условие, при котором точка останова сработает.
Это удобно, если останов нужен только при определённом значении переменной или параметра функции.
Наша функция выполняется сразу при загрузке страницы, так что самый простой способ активировать отладчик JavaScript – перезагрузить её. Итак, нажимаем F5 (Windows, Linux) или Cmd+R (Mac).
Если вы сделали всё, как описано выше, то выполнение прервётся как раз на 6-й строке.
Обратите внимание на информационные вкладки справа (отмечены стрелками).
В них мы можем посмотреть текущее состояние:
-
Watch Expressions – показывает текущие значения любых выражений. Можно раскрыть эту вкладку, нажать мышью + на ней и ввести любое выражение. Отладчик будет отображать его значение на текущий момент, автоматически перевычисляя его при проходе по коду.
-
Call Stack – стек вызовов, все вложенные вызовы, которые привели к текущему месту кода. На текущий момент видно, отладчик находится в функции pow (pow.js, строка 6), вызванной из анонимного кода (index.html, строка 15).
-
Scope Variables – переменные.
На текущий момент строка 6 ещё не выполнилась, поэтому result равен undefined.
В Local показываются переменные функции: объявленные через var и параметры. Вы также можете там видеть ключевое слово this, если вы не знаете, что это такое – ничего страшного, мы это обсудим позже, в следующих главах учебника.
В Global – глобальные переменные и функции.
Пришло время, как говорят, «погонять» скрипт и «оттрейсить» (от англ. trace – отслеживать) его работу.
Обратим внимание на панель управления справа-сверху, в ней есть 6 кнопок:
– продолжить выполнение, горячая клавиша F8. Продолжает выполнения скрипта с текущего момента в обычном режиме. Если скрипт не встретит новых точек останова, то в отладчик управление больше не вернётся.
Нажмите на эту кнопку.
Скрипт продолжится, далее, в 6-й строке находится рекурсивный вызов функции pow, т.е. управление перейдёт в неё опять (с другими аргументами) и сработает точка останова, вновь включая отладчик.
При этом вы увидите, что выполнение стоит на той же строке, но в Call Stack появился новый вызов.
Походите по стеку вверх-вниз – вы увидите, что действительно аргументы разные.
– сделать шаг, не заходя внутрь функции, горячая клавиша F10. Выполняет одну команду скрипта. Если в ней есть вызов функции – то отладчик обходит его стороной, т.е. не переходит на код внутри.
Эта кнопка очень удобна, если в текущей строке вызывается функция JS-фреймворка или какая-то другая, которая нас ну совсем не интересует. Тогда выполнение продолжится дальше, без захода в эту функцию, что нам и нужно.
Обратим внимание, в данном случае эта кнопка при нажатии всё-таки перейдёт внутрь вложенного вызова pow, так как внутри pow находится брейкпойнт, а на включённых брейкпойнтах отладчик останавливается всегда.
– сделать шаг, горячая клавиша F11. Выполняет одну команду скрипта и переходит к следующей. Если есть вложенный вызов, то заходит внутрь функции.
Эта кнопка позволяет подробнейшим образом пройтись по очереди по командам скрипта.
– выполнять до выхода из текущей функции, горячая клавиша Shift+F11. Выполняет команды до завершения текущей функции.
Эта кнопка очень удобна в случае, если мы нечаянно вошли во вложенный вызов, который нам не интересен – чтобы быстро из него выйти.
– отключить/включить все точки останова. Эта кнопка никак не двигает нас по коду, она позволяет временно отключить все точки останова в файле.
– включить/отключить автоматическую остановку при ошибке. Эта кнопка – одна из самых важных.
Нажмите её несколько раз. В старых версиях Chrome у неё три режима – нужен фиолетовый, в новых – два, тогда достаточно синего.
Когда она включена, то при ошибке в коде он автоматически остановится и мы сможем посмотреть в отладчике текущие значения переменных, при желании выполнить команды и выяснить, как так получилось.
Процесс отладки заключается в том, что мы останавливаем скрипт, смотрим, что с переменными, переходим дальше и ищем, где поведение отклоняется от правильного.
Continue to here Правый клик на номер строки открывает контекстное меню, в котором можно запустить выполнение кода до неё (Continue to here). Это удобно, когда хочется сразу прыгнуть вперёд и breakpoint неохота ставить.
При отладке, кроме просмотра переменных и передвижения по скрипту, бывает полезно запускать команды JavaScript. Для этого нужна консоль.
В неё можно перейти, нажав кнопку «Console» вверху-справа, а можно и открыть в дополнение к отладчику, нажав на кнопку или клавишей ESC.
Самая любимая команда разработчиков: console.log(...).
Она пишет переданные ей аргументы в консоль, например:
// результат будет виден в консоли
for (var i = 0; i < 5; i++) {
console.log("значение", i);
}
Полную информацию по специальным командам консоли вы можете получить на странице Chrome Console API и Chrome CommandLine API. Почти все команды также действуют в Firebug (отладчик для браузера Firefox).
Консоль поддерживают все браузеры, и, хотя IE10- поддерживает далеко не все функции, но console.log работает везде. Используйте его для вывода отладочной информации по ходу работы скрипта.
Ошибки JavaScript выводятся в консоли.
Например, прервите отладку – для этого достаточно закрыть инструменты разработчика – и откройте страницу с ошибкой.
Перейдите во вкладку Console инструментов разработчика (Ctrl+Shift+J / Cmd+Shift+J).
В консоли вы увидите что-то подобное:
Красная строка – это сообщение об ошибке.
Если кликнуть на ссылке pow.js в консоли, справа в строке с ошибкой, то мы перейдём непосредственно к месту в скрипте, где возникла ошибка.
Однако почему она возникла?
Более подробно прояснить произошедшее нам поможет отладчик. Он может «заморозить» выполнение скрипта на момент ошибки и дать нам возможность посмотреть значения переменных и стека на тот момент.
Для этого:
- Перейдите на вкладку Sources.
- Включите останов при ошибке, кликнув на кнопку
- Перезагрузите страницу.
- После перезагрузки страницы JavaScript-код запустится снова и отладчик остановит выполнение на строке с ошибкой:
Можно посмотреть значения переменных. Открыть консоль и попробовать запустить что-то в ней. Поставить брейкпойнты раньше по коду и посмотреть, что привело к такой печальной картине, и так далее.
Отладчик позволяет:
- Останавливаться на отмеченном месте (breakpoint) или по команде debugger.
- Выполнять код – по одной строке или до определённого места.
- Смотреть переменные, выполнять команды в консоли и т.п.