This repo contains implementation of Llama2 model architecture. We implement the Llama2 base variant with ~7B parameters. The weights are loaded in fp16 precision and therefore you would need roughly 14GB of memory for running inference. Figure below shows the high level model architecture for Llama2.
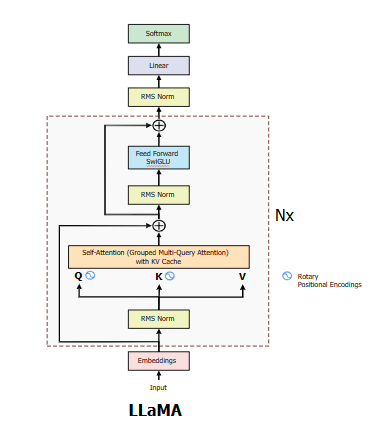
Llama family of models that includes Llama2, adopt a few key changes in comparison to the vanilla decoder only transformers and GPT based architectures. A few notable differences include:
-
Grouped Query Attention: Instead of a regular/linear self attention that requires query, key and value to have the same no. of heads, in a grouped query attention, the key and value can be shared among multiple query heads as shown in the fig. below.
-
Rotary Position Embeddings: Positional embeddings is what encodes ordering of tokens within the sequence, which is important for any sequential data. Initial transformer based models either used absolute positional encoding (such as original transformer, and GPT) or relative positional embedding (such as T5). Both the approaches have their unique strengths and also limitations. RoPE proposed a novel method to encode positional information to preserve both absolute and relative positions of tokens within the sequence. With RoPe, the position is encoded by rotating the token embeddings in the embedding space where the amount of rotation is determined by the absolute position of the token in the sequence. The figure below gives an illustration of the RoPE. Encoding the positional information this way also has other important characteristics such as decaying inter-token dependency for longer sequences. Paper - (Reformer) dives into all the technical details and highlights essential characteristics of this approach.

paper: ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING

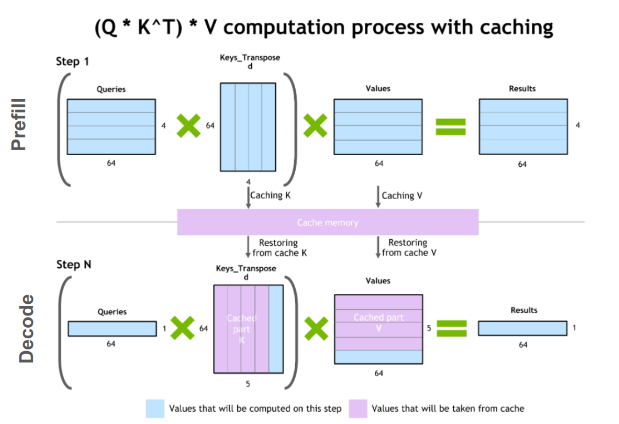
- KV Cache: One of the primary use cases of transformer models is for text generation. Transformers generate text in an auto regressive fashion i.e - one token at a time. To generate a token, the model runs all the previous tokens through the architecture. This process is repeated n times for n tokens generation. What this means is that, the self attention for the tokens that appear early in the sequence is repeated multiple times in the process resulting in redundant computation. With KV Cache, we cache the key and value tensors for all the tokens across iterations and thereby save up on redundant computation. For each iteration of next token generation, the key and value of the previously generated token is appended into the cache as shown in the figure below.
- SwiGLU activation: Llama2 uses an activation from the GLU family known as SwiGLU. GLU family of activations have been known to perform better than other activations. Here is what the authors of the paper say about what drives this performance:
We offer no explanation as to why these architectures seem to work;we attribute their success, as all else, to divine benevolence.
GLU Variants Improve Transformer
A point to note here is that transformers from huggingface uses SiLU activation in place of SwiGLU in their implementation.
reference: Transformers - Llama configuration
- A unique 3 layer MLP block: Unlike standard 2 layer MLP block with up projection and down projection, Llama2 uses a 3 layer MLP block with gate projection, up projection and down projection. Computationally, it looks as is shown below.
output = down_proj(activation(gate_proj(x)) * up_proj(x))
- Tensor Parallelism for pre-training: Llama2 uses tensor parallelism for pre-training to scale up the computation. This is used for pre-training and is not implemented in our code which is primarily focussed on inference.
- We have implemented the base variant of Llama2 with roughly 7B parameters.
- The implementation is focussed on inference and therefore no training loop is implemented.
- We load the pre-trained weights from huggingface in fp16 precision. This requires roughly 14GB of memory to be available.
- Most of the model architecture choices (such as no. of query heads, no. of key/value heads etc) are configurable. All configurations are defined in
config.py. - To compare the results of our implementation with huggingface's implementation, we have a
validate.pyscript. This script compares the logits of the last layer from both the implementations to validate the accuracy.