This is org-incoming, a package to ingest PDF files into your org or org-roam files.
This package is intended to help you if you have a large number of "incoming" PDF files, e.g. scanned handwritten notes, and you want to somehow capture these PDFs in your org files. "Capturing" here can mean anything from completely transcribing them (or taking OCRed text in the PDF) to just creating an org file with a title, a date and maybe some tags, which links to the archived PDF.
Personally, I use this to ingest the PDFs resulting from my Rocketbook into my org files.
This package is available on MELPA. So, if you have MELPA you can do M-x package-install org-incoming RET. Alternativerly, to install it manually, clone the repository or get the
org-incoming.el file by some other means and put it in your Emacs' load-path. After that, all
you need to do is
(require 'org-incoming)
After configuring org-incoming you can start a new org-incoming session by
invoking org-incoming-start. An org-incoming session will process all files in your incoming
folders sequentially. Each file passes through two phases:
- The "query" phase
- The "annotation" phase
Each phase can be completed (going to the next phase or to the next incoming file) by pressing C-c C-c or invoking org-incoming-complete. When you complete the annotation phase for a file, the PDF
file will be moved to the correct location and the annotation file will be created.
You can quit your org-incoming session at any point by invoking org-incoming-quit (bound to
C-c C-k by default).
In the query phase, your emacs frame should look like this:
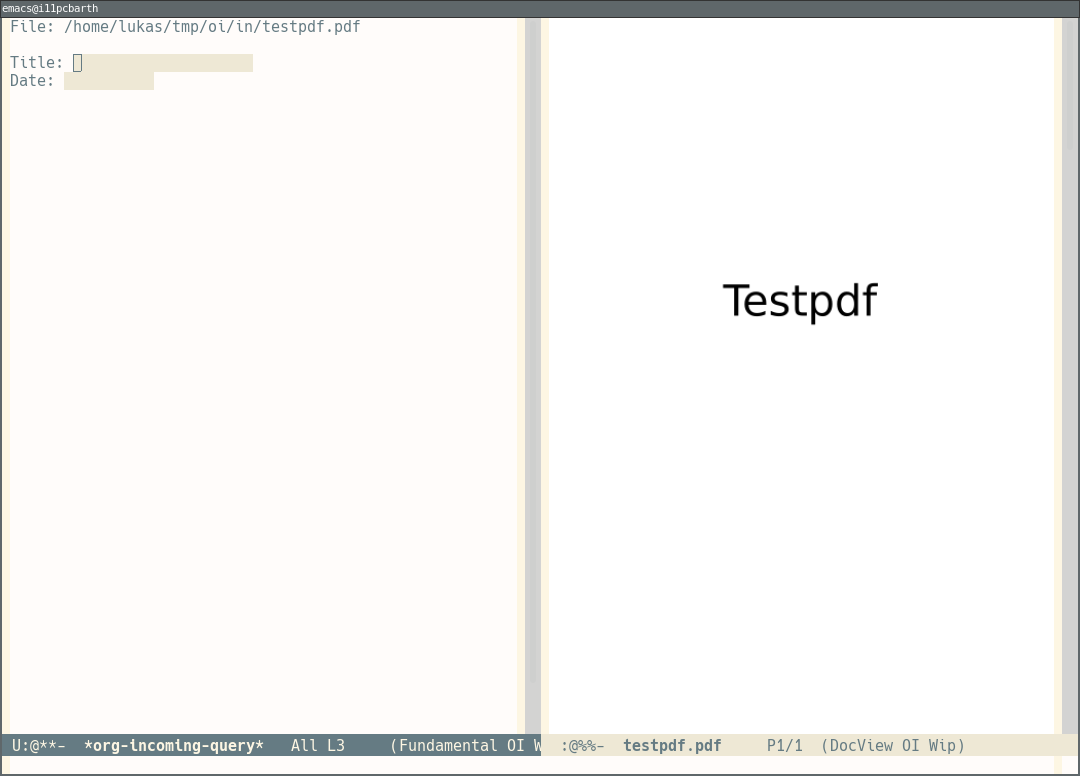
The PDF in displayed in one window, and the other window contains the query buffer. The query buffer
contains an form in which you should assign the PDF a title and a date. Note that you can have
the date parsed automatically from the filename of the incoming file. You can use Tab and S-Tab
to jump between the form fields, and pressing Return while the date field is focussed will bring
up a calendar for date selection.
Press C-c C-c (or M-x org-incoming-complete RET) to complete the query phase. If you want to
skip the file for now, press C-c C-s (M-x org-incoming-skip RET). If you want to quit your
org-incoming session, press C-c C-k (M-x org-incoming-quit RET).
In the annotation phase, your emacs frame should look like this:
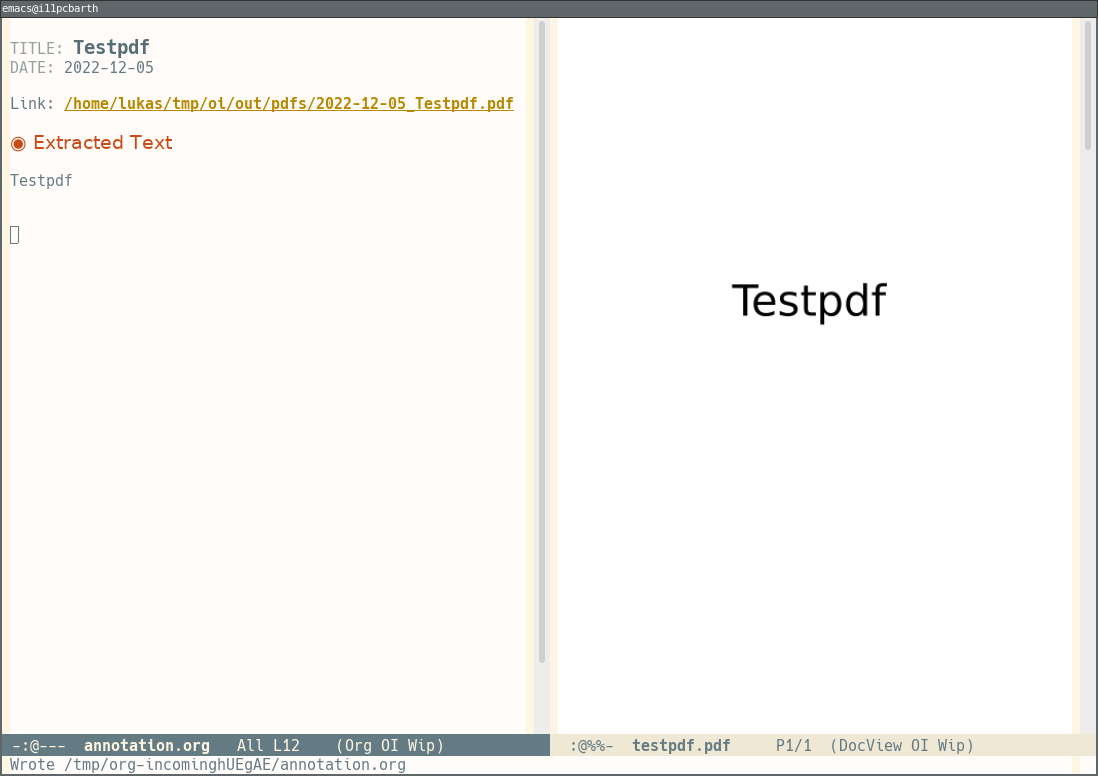
Here you still see the PDF on the one side, and the annotation file to be created on the other side. Note that the annotation file is pre-filled with the title and date you gave and contains a link to the PDF file, resp. where the PDF file will be moved.
Depending on your configuration, the annotation file will also contain any automatically extracted text, and may be a plain org file, or an org-roam node.
Press C-c C-c (M-x org-incoming-complete RET)to complete the annotation phase and complete
processing this file. org-incoming will then automatically proceed with the next file. If you want
to skip the file for now, press C-c C-s (M-x org-incoming-skip RET). If you want to quit your
org-incoming session, press C-c C-k (M-x org-incoming-quit RET).
Start a new org-incoming session.
Complete the current phase, advancing to the next. If the current phase is the annotation phase, the PDF file will be moved to its destination, the annotation file will be created at its destination, and the next PDF will be loaded (if any remain).
Quit the current org-incoming session. Any input from the current query or annotation phase will be discarded, and the file currently being processed will not be moved.
Skip the incoming file currently being processed. The file is skipped for the current org-incoming session. If you quit org-incoming and cal org-incoming-start again, the file will be processed again.
There is one mandatory configuration setting:
org-incoming-dirs: A list of plists describing the source/target pairs and any settings overrides for them.
Each plist must at least contain :source <from-directory> and :target <to-directory>. For each
such pair, from-directory is treated as a path to a directory that contains incoming PDF files, and
to-directory is the target directory. org-incoming will place its annotation files in the
to-directory, and move the PDF files into the org-incoming-pdf-subdir directory inside the
to-directory.
Additionally, the plist for each folder pair can contain overrides for almost all of org-incoming's
settings, in the form of :<setting-name> <value>. See the respective settings for details.
See this example:
(setq org-incoming-dirs '((:source "/home/user/incoming/folder1" :target "/home/user/org/archive")
(:source "/home/user/incoming/folder2" :target "/home/user/org/archive" :use-roam 't)
(:source "/home/user/incoming/folder3" :target "/home/user/org/todos" :pdf-subdir "originals")))With this configuration, all PDF files in ~/incoming/folder1 and ~/incoming/folder2 will have
their annotation files in ~/org/archive and (with a default org-incoming-pdf-subdir) their PDFs
in ~/org/archive/pdfs. However, PDFs from ~/incloming/folder2 will be annotated with org-roam
node files instead of "plain" org files. PDF files from ~/incoming/folder3 will have their
annotations in ~/org/todos and their PDFs in ~/org/todos/originals.
Optionally configurable variables are:
org-incoming-parse-date-pattern(or:parse-date-pattern)org-incoming-parse-date-re(or:parse-date-re)org-incoming-pdf-subdir(or:pdf-subdir)org-incoming-use-roam(or:use-roam)org-incoming-annotation-template(or:annotation-template)
Template configuration is explained below. For everything else, please see their respective variable
documentation (M-x describe-variable <variablename> RET) for documentation. Each of these
variables can be overridden for individual folder pairs by removing the org-incoming- prefix from
the variable name and using the remainder as a symbol in the folder pair's plist (see the example
above).
The variable org-incoming-annotation-template (resp. the :annotation-template property) expects
a strings that acts as a template for the annotation files. This template will be formatted using
s.el's s-format, so see the documentation for details. The available fields are:
${title}- The title assigned during query${date}- The date assigned during query${link}- The link to the PDF file (after moving)${extracted}- Any text extracted from the PDF file"
The default template looks like this:
#+TITLE: ${title}
#+DATE: ${date}
Link: [[${link}]]
* Extracted Text
${extracted}
This software is released under the MIT license, also knows as the "Expat License". See License.txt for details.