Reconfiguration
A special feature of Vermont is its support for dynamic reconfiguration of the module structure. Linked modules in Vermont correspond to a directed acyclic graph and operate independently from each other.
The idea is to support updates of the configuration file and to reconfigure Vermont accordingly at runtime. For this reconfiguration, Vermont computes the differences between the old and new configuration. Unique IDs are used to identify the modules. Vermont always tries to reuse existing modules in order to allow keeping state information and to speed up the reconfiguration process. If the configuration of an existing module has been changed, Vermont tries to reuse it and applies updates on-the-fly. If it is not possible to reuse a module, a new one is created. Examples are aggregator modules: for aggregation configurations, no on-the-fly reconfiguration is allowed because the used hash tables need to be rebuilt. Thus, all stored flows need to be exported and sent to the subsequent module in the module graph. This ensures as little flow data loss as possible. This process is repeated for each module until instances for all new modules are created. Modules are reconnected according to the new configuration and started in reverse topological order as depicted by the numbers in the following figure.
If modules do not have any asynchronous tasks to perform, they may be executed synchronously using a single thread. If, on the other hand, Vermont runs on a multicore machine, the software can be configured to use multiple threads, at most one per module. Asynchronous execution of modules causes lags in the processing time, so Vermont may use queues between modules to compensate this problem. The queues can be fully customized, but usually FIFO scheduling with a configurable size is used. The queues block if the maximum size is reached.
The following figure shows a configuration consisting of three modules that are connected by queues:
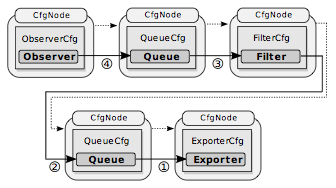
Shown are the configuration paths (dashed lines) that link all the modules in the module graph and the data paths (thick lines) that depict the data flow between the modules.
The development of the reconfiguration process focused on minimizing the time during which data processing is stopped. It is technically not feasible to provide completely uninterrupted processing because the dependencies between the modules need to be considered. Especially, it is not possible to reconfigure the module graph without stopping the modules that need to be re-ordered in the graph. We minimized the module's outage by preparing new modules before the processing is stopped.
Additionally, the shutdown of old modules is performed after the new configuration is completed and started. We achieved downtimes smaller than using this method. On a link transferring 1 GBit/s, this timeout could result in a data loss of about 650 KByte. Vermont is able to buffer this data during the reconfiguration process using the memory-mapped PCAP library. For our tests, this buffer was set to 64 MByte.
Dynamic adaptation to current traffic data rates and corresponding load on flow meters does not only depend on seamless reconfiguration, but also on the ability to identify and, in the best case, anticipate bottlenecks in the monitoring hierarchy. We implemented sensors inside Vermont to retrieve information about the current load of the system. Each module offers standard measurement values like CPU utilization and memory requirements. Additionally, module-specific data is monitored, e.g. the current packet rate or the queue size. This information is an essential requirement for algorithms that try to balance load among multiple flow aggregation nodes. Based on the data coming from the sensors, it is possible to move a task to a different system that still has unused capacities.
The following figure shows example statistics from the aggregator's hash table that were collected over one day:

The black line shows the total number of entries inside the hash table, the blue line shows the number of entries that shared a single bucket with other entries inside the hash table. Multi-entry buckets considerably slow down the lookup of entries in a hash table, as they are implemented as linked lists. In our example, the hash table offered a total of 256 Kbuckets, but at the time of 800 min a DDoS attack occurred on the monitored link and the number of entries exceeded the hash table's capacity by far. This is a typical case for a DoS attack against the flow meter and should be evaded by monitoring the module load and adequate reconfiguration.