
VIVO Scholars Discovery is a middleware project that pulls VIVO content into its own search index (Solr) and then exposes that content via a RESTful service endpoint.
Various frontend applications are available (or can be built) to display the content as read-only websites. Existing frontend applications include:
Scholars Discovery project was initiated by Scholars@TAMU project team at Texas A&M University (TAMU) Libraries. In support of the Libraries’ goal of enabling and contextualizing the discovery of scholars and their expertise across disciplines, the Scholars’ team at TAMU Office of Scholarly Communications (OSC) proposed the Scholars version 2 project, which focuses on deploying (1) new public facing layer (Read-only), (2) faceted search engine, (3) Data reuse options, and (4) search engine optimization. Digital Initiative (DI) at TAMU Libraries collaborated with the OSC to design and implement the current system architecture including Scholars Discovery and VIVO Scholars Angular. In a later stage, Scholars Discovery project was adopted by VIVO Community’s VIVO Scholar Task Force.
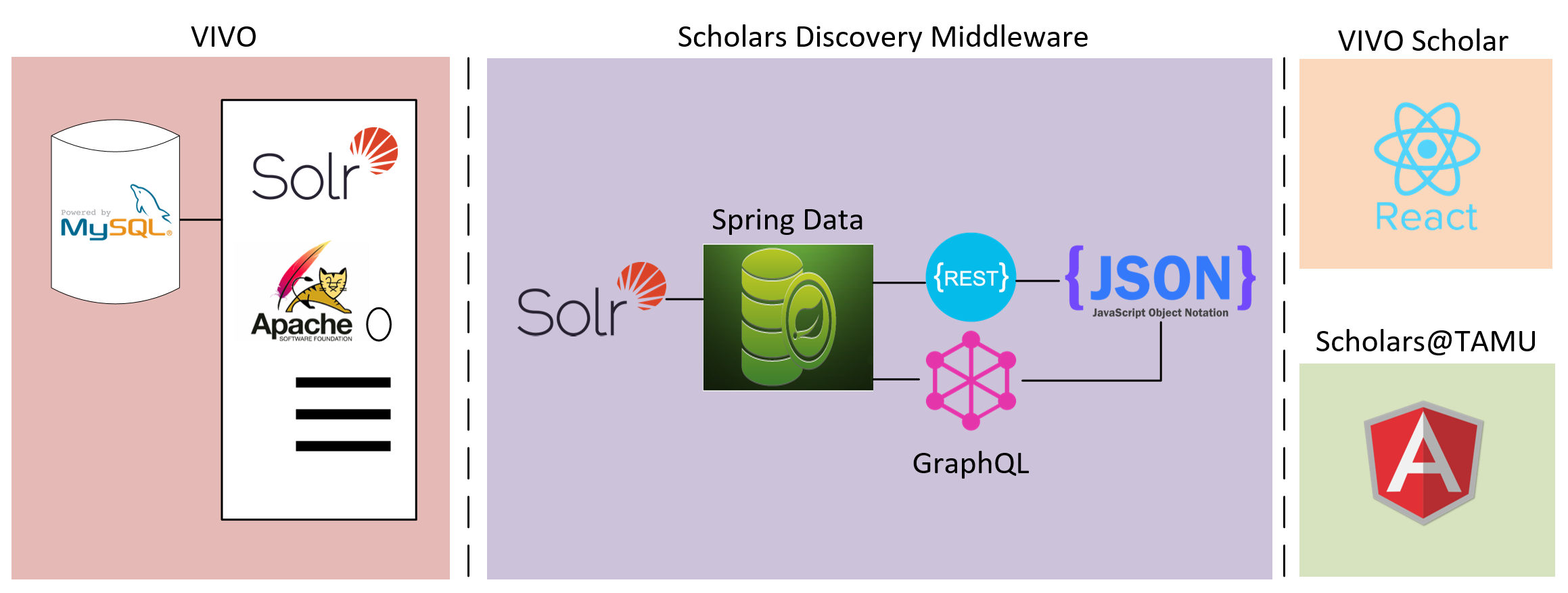
Scholars discovery system is first and foremost an ETL system in which extracts data from VIVO's triplestore, transforms triples into flattened documents, and loads the documents into Solr. The Solr index is then exposed via REST API and GraphQL API as a nested JSON. A secondary feature is that of providing a persistent, configurable discovery layout for rendering a UI.
Extraction from VIVO is done view configurable harvesters in which make SPARQL requests to the triplestore for a collection of objects and subsequent SPARQL requests for each property value of the target document. The SPARQL requests can be found in src/main/resources/templates/sparql. The transformation is done granularly converting resulting triples of a SPARQL request into a property of a flattened document. This document is then saved into a heterogeneous Solr collection. The configuration of the Solr collection can be found in solr/config. In order to represent a flatten document as a nested JSON response, the field values are indexed with a relationship identifier convention. [value]::[id], [value]::[id]::[id], etc. During serialization the document model is traversed parsing the Solr field value and constructing a nested JSON.
Here is a list of some dependencies used:
The basic Spring Boot application configuration can be found at src/main/resources/application.yml. Here you be able to configure basic server and spring configuration as well as custom configuration for Scholars Discovery. There are several configuration POJOs to represent configurations. They can be found in src/main/java/edu/tamu/scholars/middleware/config/model, src/main/java/edu/tamu/scholars/middleware/auth/config, and src/main/java/edu/tamu/scholars/middleware/graphql/config/model.
Harvesting can be configured via middleware.harvesters and represented with HarvesterConfig. For each harvester, a bean will be created in which specifies the type of harvester and which document types it maps to. The reference implementation is the local triplestore harvester.
Indexing can be configured via middleware.indexers and represented with IndexerConfig. For each indexer, a bean will be created in which specifies the type of indexer and which document types it indexes. The reference implementation is the solr indexer.
The application can be configured to harvest and index on startup, middleware.index.onStartup, and via a cron schedule via middleware.index.cron. The indexing is done in batch for performance. It can be tuned via middleware.index.batchSize.
Solr is configured via spring.data.solr.
GraphQL SPQR configuration can be done via graphql.spqr. Explicit Java models in which are turned into a GraphQL schema are generated. The generated models are a nested representation of the flattened index documents. An important configuration for GraphQL schema generation is for generating explicit composite models representing relationships between complete index documents. The configuration is done via src/main/resources/graphql/composites.yml and represented with Composite.java.
cd scholars-discovery/solr
docker build --tag=scholars/solr .
docker run -d -p 8983:8983 scholars/solr- Build and Run the application
mvn clean install
mvn spring-boot:run- Note: Custom application configuration can be achieved by providing a location and an optional profile, such as:
mvn spring-boot:run -Dspring-boot.run.profiles=dev -Dspring-boot.run.config.location=/some/directory/- ..where an
application-dev.ymlexists in the/some/location/directory
docker build -t scholars/discovery .docker run -d -p 9000:9000 -e SPRING_APPLICATION_JSON="{\"spring\":{\"data\":{\"solr\":{\"host\":\"http://localhost:8983/solr\"}}},\"ui\":{\"url\":\"http://localhost:3000\"},\"vivo\":{\"base-url\":\"http://localhost:8080/vivo\"},\"graphql\":{\"spqr\":{\"gui\":{\"enabled\":true}}},\"middleware\":{\"allowed-origins\":[\"http://localhost:3000\"],\"index\":{\"onStartup\":false},\"export\":{\"individualBaseUri\":\"http://localhost:3000/display\"}}}" scholars/discoveryThe environment variable
SPRING_APPLICATION_JSONwill override properties in application.yml.
With the above installation instructions, the following service endpoints can be verified:
- HAL Explorer (9000/explorer)
- REST API (9000/individual)
- REST API Docs (9000/api)
- GraphQL UI (9000/gui)
The HAL(Hypertext Application Language) explorer can be used to browse scholars-discovery resources.
-
spring-data-solrdependency from TAMU Maven repository.- Added
tamu-releasesrepository in pom.xml - Added dependency
4.1.6.TAMU.RELEASEversion ofspring-data-solrin pom.xml - Excluded
spring-data-solrfromspring-boot-starter-data-solrdependency
Waiting on https://jira.spring.io/browse/DATASOLR-572
- Added
-
Using custom query and query parser to add edismax/dismax query parameters.
- Added package
edu.tamu.scholars.middleware.discovery.query - Registered parsers on
@PostConstructofIndividualRepoImpl
Waiting on https://jira.spring.io/browse/DATASOLR-153
- Added package