{kind=link}
This project is a Convolutional Neural Network (CNN) model designed to classify my cat Leah out of other cats. The model is trained using TensorFlow/Keras and can be used to distinguish Leah from other cats in images.

- Project Overview
- Installation
- Dataset
- Model Architecture
- Training
- Evaluation
- Results
- Conclusion
- Future improvements
- Contributing
The Leah Cat Classifier uses deep learning techniques to identify images of my cat Leah. The primary goal is to create a model that can accurately classify Leah among various other cats.
To get started, clone the repository and install the required dependencies.
git clone https://github.com/yourusername/leah-cat-classifier.git
cd leah-cat-classifier
pip install -r requirements.txt
The dataset consists of images of Leah and other cats. The images are organized into two main folders: train and tes both of these two folders contain another two sub folders: LEA and OTHER (Lea is my own cat while other means any other cat).
image_data/
├── train/
│ ├── LEA
│ │ └── image_1.jpg
│ │ └── image_2.jpg
│ │ └── image_n.jpg
│ ├── OTHER
│ │ └── image_1.jpg
│ │ └── image_2.jpg
│ │ └── image_m.jpg
├── test/
│ ├── LEA
│ │ └── image_1.jpg
│ │ └── image_2.jpg
│ │ └── image_x.jpg
│ ├── OTHER
│ │ └── image_1.jpg
│ │ └── image_2.jpg
│ │ └── image_x.jpg
For the other cats I used Kaggle Cats and Dogs dataset (check: https://www.kaggle.com/datasets/erkamk/cat-and-dog-images-dataset) and for my cat i used images taken by me or my siblings of many angles, The first problem i encountered is the lack of data Cats dataset contains about 600 images while i only got about 60 images of my cat, its obviously a huge class imbalance.
The first thing I thought of is using the Under-sampling method. I had to remove some of the majority class and got it down to approximately 400 images, which is still too much.
Then I used the Transfer Learning technique for the reason that it eases the learning process by leveraging the patterns learned from a previously trained model. This approach not only saves computational resources but also helps in achieving better performance even with the reduced dataset, as the pre-trained model has already learned useful features from a larger dataset. Finally, I made sure the test set was equivalent for both classes to ensure a fair evaluation of the model's performance. This is crucial as an imbalanced test set could lead to misleading accuracy metrics, making the model appear more or less effective than it truly is. By maintaining an equal representation of classes in the test set, I could more accurately assess the model's ability to generalize to unseen data.
Of course, I tried other methods such as: Data augmentation, which involves creating new synthetic instances from the existing minority class. This technique, which can include transformations such as rotations, shifts, and flips, allows the model to learn from a more diverse, albeit synthetic, dataset. Although This can improve the model's ability to generalize and perform better on unseen data for some reasons I got somewhat bad results, but then again maybe the technique i used to achieve the desired augmenetation is wrong.
Another approach is using class_weight parameters available in many machine learning algorithms. This method assigns a higher penalty to misclassified instances of the minority class during the training process. By doing so, the model is incentivized to pay more attention to the minority class, even though it is underrepresented. But somehow, instead of improving the results, the use of class_weight led to an unexpected outcome: almost every cat in the test set was being classified as 'OTHER'.
Finally after preprocessing the dataset it was ready for the training!
The model is a Convolutional Neural Network (CNN) built using TensorFlow/Keras. It is based on the Xception architecture, which is a powerful pre-trained model. Here’s a simplified explanation of how the model is structured:
- Base Model: The Xception model pre-trained on the ImageNet dataset is used as the base model. This model has already learned to extract useful features from images.
- Freezing Layers: The layers of the base model are frozen, meaning their weights are not updated during training.
- Global Average Pooling: The output of the base model is passed through a Global Average Pooling layer to reduce the spatial dimensions.
- Fully Connected Layer: This is followed by a dense (fully connected) layer with 1,024 neurons and ReLU activation.
- Output Layer: Finally, there is an output layer with a single neuron and sigmoid activation to predict whether the image is of Leah or another cat.
To train the model, follow these steps:
-
Compile the Model: First, we prepare the model for training by specifying how it should optimize its weights and how it should measure its performance. We use the 'adam' optimizer, the 'binary_crossentropy' loss function (since it's a binary classification problem), and we track 'accuracy' and 'precision' metrics.
-
Initial Training: We train the model on the dataset for 25 epochs using the training and validation data generators. At this stage, the base model's layers are still frozen, so only the new layers we added are being trained.
-
Unfreeze the Base Model: After the initial training, we unfreeze the layers of the base model. This means the weights of these layers can now be updated.
-
Recompile the Model: We compile the model again with the same optimizer, loss function, and metrics. This step is necessary because we've changed which layers are trainable.
-
Final Training: We train the model again for another 25 epochs. This time, the entire model, including the previously frozen base model layers, is trained. This allows for fine-tuning of the entire network, potentially leading to better performance.
Train Result:
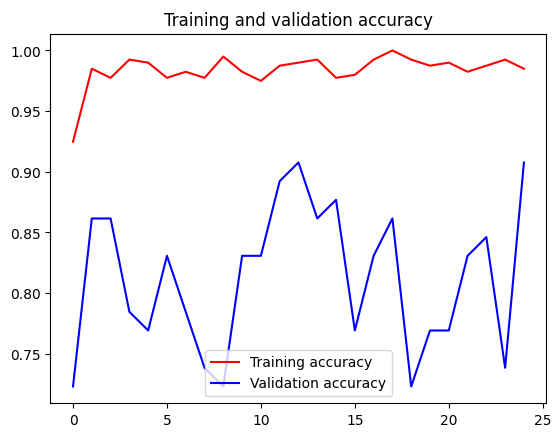
To evaluate the model's performance on a test set, we use several metrics, including a confusion matrix and a classification report. These metrics provide detailed insights into how well the model is performing.
-
Confusion Matrix: This is a table that allows us to see the number of true positives, true negatives, false positives, and false negatives. It helps in understanding the types of errors the model is making.
-
Classification Report: This report includes precision, recall, and F1-score for each class. Here's a brief explanation of these metrics:
- Precision: The ratio of true positive predictions to the total predicted positives. It indicates how many of the predicted positive cases were actually correct.
- Recall: The ratio of true positive predictions to the total actual positives. It indicates how many of the actual positive cases were correctly identified by the model.
- F1-Score: The harmonic mean of precision and recall. It provides a single metric that balances both precision and recall.
After training, the model achieved:
- Accuracy: 83%
- Precision: 73%
which is not too bad, because the miss classified pictures of LEA in the test set are a pictures of her being a kitty thus her face structure was a bit different or some images of something covering her face and lastly a blurred image. And for the other class the model got 100% precision (See Classification report).
In conclusion, the model demonstrates proficiency in identifying non-Lea images but struggles to accurately classify Lea under certain conditions, such as when the images are blurry, her face is covered, or when presented with pictures of her as a kitten. However, the model has been well-trained on the structure of Lea's face. As a result, it can predict with 100% certainty when presented with a clear image of her face.
For future improvements, there are several strategies i want to employ. First, i want to expand and diversify my training data to include more examples of Lea under various conditions, such as blurred images, images where her face is partially covered, and images with different lighting conditions. This would help the model to generalize better and improve its performance on real-world data.
Second, i want to explore different model architectures or fine-tune the hyperparameters of our current model. Advanced models like EfficientNet or different versions of ResNet could potentially yield better results. Additionally, techniques like cross-validation could be used to optimize the hyperparameters and prevent overfitting.
Lastly, the possibility to implement an ensemble of models. By leveraging the strengths of multiple models, this could potentially achieve higher accuracy and robustness than with a single model.
These improvements, while potentially requiring more computational resources and development time, could significantly enhance the model's performance and its applicability to real-world scenarios.
Contributions are welcome! Please fork the repository and create a pull request with your changes.
- Fork the Project
- Create your Feature Branch
- Commit your Changes
- Push to the Branch
- Open a Pull Request