U-Crawler即Url-Crawler
并发的爬取baidu,yahoo,bing和360so搜索结果的url。暂不支持google,google的反爬虫机制太严了,爬取不到一百个结果,就要验证,故取消。
- Python 2.7
- pip
- gevent
- requests
- BeautifulSoup
- lxml
Usage: U-Crawler.py [-q] query [--limit] number [-o] filename
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-q QUERY, --query=QUERY
The query of search engine.
-l LIMIT, --limit=LIMIT
The limit of each search engine.
-o NAME, --output=NAME
If not use -o,the filename of output is time string.
-b, --baseurl The url of writing in file,if it is set,the url will
remove path and param.
python U-Crawler.py -q inurl:login.php -l 100
q参数即搜索语法,l参数是每个搜索引擎结果的数。
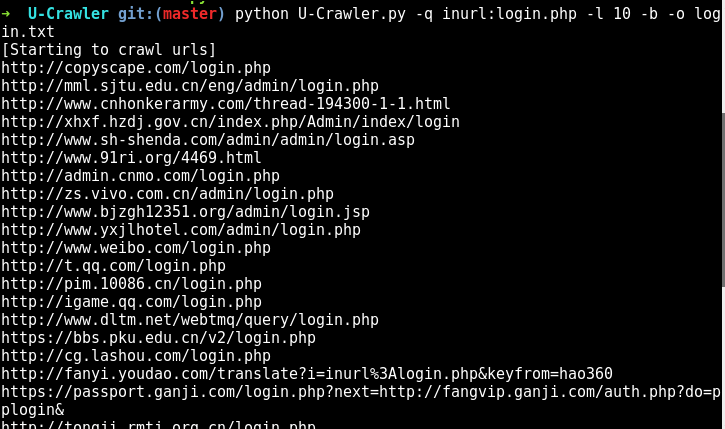
python U-Crawler.py -q inurl:login.php -l 10 -b -o login.txt
b参数是写入的url去掉后面的路径,默认不去除。o参数是保存结果文件名,默认以开始运行的时间为文件名。