2020_xtext
![]()
Homepage: https://eclipse.org/Xtext/
Xtext is already installed in the provided virtual machine environment. To manually install it into a fresh Eclipse instance, add Xtext 2.24 using the releases update site: http://download.eclipse.org/modeling/tmf/xtext/updates/composite/releases/
(You can find the link here for the latest Xtext release: https://eclipse.org/Xtext/download.html)
Click Help > Install New Software and complete with Next, Next and Finish.
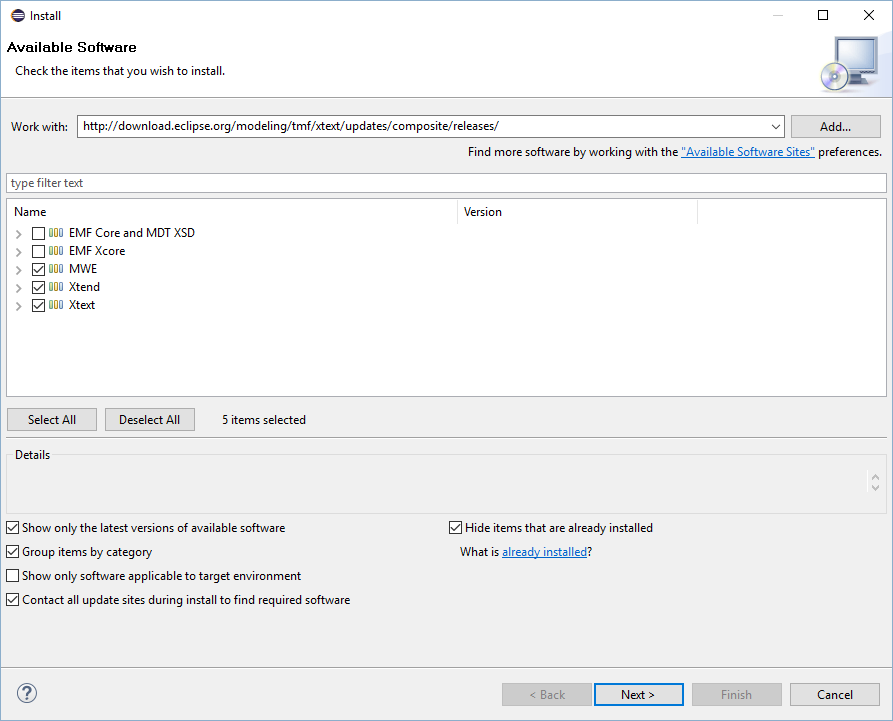
As you can see, we are going to need Xtend as well.
-
Creating a new Xtext project.
Use the following project name:
hu.bme.mit.mdsd.erdiagram.text. Name the languagehu.bme.mit.mdsd.erdiagram.text.ERDiagramDsl. It should conform to a fully qualified class name. The file extension should beer.
You can hit Finish, or on the next page, you can disable the "Testing support" as we are not going to need that. As a result, a simple
Hellolanguage is generated with greetings messages. As a first step, it is worth checking out this generated example language. -
Declaring our own entity-relationship language.
grammar hu.bme.mit.mdsd.erdiagram.text.ERDiagramDsl with org.eclipse.xtext.common.Terminals generate eRDiagramDSL "http://www.bme.hu/mit/mdsd/erdiagram/text/ERDiagramDsl"With the
grammarkeyword we can declare the name of our language. Thewithkeyword defines an inheritance from another language. In this case, our language inherits from the Terminals language, which enables us to use the predefined terminal rules, e.g.,ID,INTandSTRING(see later).The
generatekeyword is responsible for generating the AST metamodel (more precisely, DOM metamodel) from the language definition. The metamodel will be expressed in Ecore, where the EPackage name will be eRDiagramDsl and the package namespace uri will behttp://www.bme.hu/mit/mdsd/erdiagram/text/ERDiagramDsl. By default, the generated EClasses within the package will be named after the name of the grammar rule that generated them. -
Defining the entry rule.
Each Xtext language is built up from context-free grammar rules. The entry (or main) rule, responsible for describing the structure of the entire text file, is the first defined rule. In our case, the
ERDiagramrule will serve as the main rule:ERDiagram: entities+=Entity+ relations+=Relation* ;As can be seen, a rule can be defined with the following syntax: rule name ':' ... ';'
This rule states that each file in our syntax consists of one or more
Entityobjects and zero or moreRelationobjects (rules). The entire model described by such a file will be stored in an EObject of typeERDiagram, and the individual entities and relations will be stored in two containment EReferences of this root object, named entities and relations in this case.Containment references in a rule can be defined in the following ways (attributes and cross-references work analogously, as we will see):
-
referenceName
=ruleName -> one contained object (described by the called rule) is put into the single-valued containment EReference; -
referenceName
+=ruleName -> one contained object (described by the called rule) is put into a many-valued containment EReference (can hold a list of zero, one or more contained objects); -
referenceName
+=ruleName*-> zero, one or more contained objects (each described by the called rule) are put into a many-valued containment EReference.
Note that single-valued EReferences can be defined with the
=operator, whereas many-valued EReferences are defined with the+=operator.The usage of
*in the last example indicated the multiplicity of the contained objects. Multiplicities can be defined using the following operators:-
-
*-> zero, one or more; -
+-> one or more; -
?-> zero or one.
Note: by default,
ruleNamewill also be the type of the objects held by the containment reference, because the generated DOM uses rule names as type names (EClass names). This is possible to override if we want the parsed model to conform to an existing Ecore metamodel (see later). -
referenceName
-
Introducing enumeration rules.
Special enumeration rules can be defined using the
enumkeyword. In this example we defined anenumeration typefor representing ER attribute types:enum AttributeType: INT = 'int' | DOUBLE = 'double' | STRING = 'string' | BOOLEAN = 'boolean' | DATETIME = 'datetime' ;Such enumeration rules are mapped to EMF enumerations in the generated AST. The key-value pairs are separated by '|' characters; each pair consists of an enum literal to be generated, and a keyword to define its concrete syntax.
-
Introducing the
IDterminal rule and keywords.The
IDterminal rule comes from the Terminals language and defines a unique identifier. Additionally, we can define terminals (or keywords) for our language between apostrophe characters. Using the ID terminal rule and additional keywords, let us define the first version of the Entity rule:Entity: 'entity' name=ID ';'? ;An
Entityrule starts with theentitykeyword, followed by a string conforming to theIDterminal rule (which is stored in the name attribute) and finally, an optional;terminal character (keyword) concludes the rule (note the multiplicity indicator?after the;terminal character).Note that an attribute assignment in a rule uses the same syntax as a reference assignment. Attributes can be defined in the following ways (note that they are indeed analogous to defining containment EReferences):
-
attributeName
=ruleName -> one data value (described by the called rule) is put into a single-valued EAttribute; -
attributeName
+=ruleName -> one data value (described by the called rule) is put into a many-valued EAttribute; -
attributeName
+=ruleName*-> zero, one or more data values (described by the called rule) are put into a many-valued EAttribute.
-
attributeName
-
Introducing grouped multiplicities and booleans.
We can group expressions with parentheses (
(,)) to add a joint cardinality indicator character (see*,?demonstrated above) to the complex grouped expression. Let us extend the Entity rule with attributes using grouped expressions:Entity: 'entity' name=ID ('{' (attributes+=Attribute) (',' attributes+=Attribute)* '}')? ; Attribute: name=ID ':' type=AttributeType (isTransient?='transient')? ;According to the defined rule, if an entity doesn't have any attributes, then the entire pair of curly braces can be omitted. Otherwise, there is one mandatory application of the
Attributerule with the resulting object being put into theattributescontainment reference. The first attribute is optionally followed by a number of additional attributes, each separated by a comma terminal character.A special case of the EAttribute assignment syntax for boolean attributes is demonstrated in the
'Attributerule. If thetransientkeyword is found, the grouped expression (with optionality indicator?) will match, setting the boolean fieldisTransientto true. The syntax is the following:-
attributeName
?=keyword -> the boolean attribute is set to true (but only if the keyword expression matches the text).
-
attributeName
-
Introducing cross-references.
Cross-references can be used to reference an instance of a rule applied elsewhere (i.e., an already existing object in the resulting DOM) with square brackets
[...]. Note that Xtext supports multiple types of cross-references. The best practice is to apply cross-references via the TypeRef rule using the name attribute of EClasses, that is, if we want to reference instances of an EClass, make sure that it contains an attribute called name populated by the terminal rule ID.Let us further refine the Entity rule with the
keyandisAreferences:Entity: 'entity' name=ID ('key' key=[Attribute])? ('isA' isA+=[Entity])* ('{' (attributes+=Attribute) (',' attributes+=Attribute)* '}')? ;If we omit the square brackets (
isA+=Entityinstead ofisA+=[Entity]), then we will have to apply the rule again starting with theentitykeyword, defining a new entity each time. With the square brackets, we declare that only a cross-reference is needed to a rule instance applied elsewhere:[EClass].Note: in this case, 'EClass' equals to a rule name, because the generated AST uses rule names as type names.
-
Introducing unordered expressions.
The
&character defines an unordered list of rules, that is, they can be applied in any order. Let us extend our language with the following rules:Relation: leftEnding=RelationEnding 'is related with' rightEnding=RelationEnding ; RelationEnding: (multiplicity=Multiplicity & (nullable?='nullable')?) target=[Entity] ; enum Multiplicity: One = "one" | Many = "many" ;In the case of the RelationEnding rule, due to the
&(unordered expression) and?(optionality) operator, the following combinations are all accepted before the entity reference:- one nullable;
- nullable one;
- many nullable;
- nullable many;
- one;
- many.
-
Putting everything together.
The full Xtext code:
grammar hu.bme.mit.mdsd.erdiagram.text.ERDiagramDsl with org.eclipse.xtext.common.Terminals generate eRDiagramDsl "http://www.bme.hu/mit/mdsd/erdiagram/text/ERDiagramDsl" //Entry rule ERDiagram: entities+=Entity* relation+=Relation* ; Entity: 'entity' name=ID ('key' key=[Attribute])? ('isA' isA+=[Entity])* ('{' attributes+=Attribute (',' attributes+=Attribute)* '}')? ; Attribute: name=ID ':' type=AttributeType (isTransient?='transient')? ; enum AttributeType: INT = 'int' | DOUBLE = 'double' | STRING = 'string' | BOOLEAN = 'boolean' | DATETIME = 'datetime' ; Relation: leftEnding=RelationEnding 'is related with' rightEnding=RelationEnding ; RelationEnding: (multiplicity=MultiplicityType & (nullable?='nullable')?) target=[Entity] ; enum MultiplicityType: One = 'one' | Many = 'many' ; -
Visualizing our Xtext language.
Open the Xtext Syntax Graph View: Window -> Show View -> Other... -> Xtext Syntax Graph

In this view, you can see the graph representation of your Xtext language. It is useful to check or understand the construction of a language.
When you modify your Xtext files, you have to build the infrastructure for your language. The following figure shows where to click to generate.

-
Start a runtime Eclipse.
-
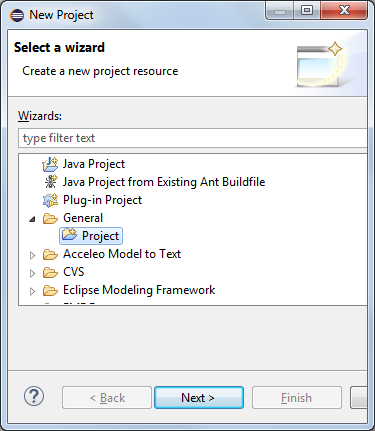
Create a general project:
New -> Project... -> General -> Project Name: hu.bme.mit.mdsd.erdiagram.text.example.
-
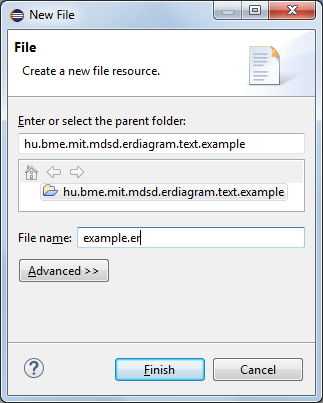
Create a file with 'er' extension:
New -> File Name: example.er.
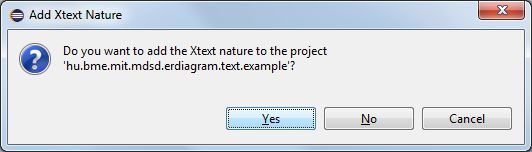
Add Xtext nature in the pop-up window.
-
(Optional, if you missed the pop-up window) Add Xtext nature:
Right click on project -> Configuration -> Add Xtext nature.
-
Now, you can try out the language. Notice that you can use auto-completion (Ctrl + Space) and quick fixes (Ctrl + 1) as well.
-
Create an example file with er extension and fill it with the following content:
entity person key id { name : string, id : int } entity driver isA person { licence : string } entity car key numberPlate { numberPlate : string, year : int transient } one person is related with nullable many car -
Open the file with the Simple Ecore Model Editor.
Right click on the file -> Open -> Open with... -> Simple Ecore Model Editor

This will show you the AST (more precisely, the DOM) parsed from the text.
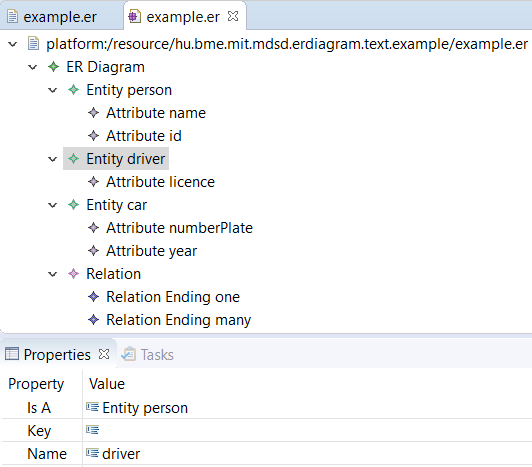
To illustrate the difference between containment and cross-references, let us modify the key reference of the Entity rule by removing the brackets around the referenced Attribute rule.
Entity:
'entity' name=ID (key=Attribute)? ('isA' isA+=[Entity])*
('{'
attributes+=Attribute
(',' attributes+=Attribute)*
'}')?
;
Let us regenerate the infrastructure and try how key references work now. Let us try to define the person entity the same way as in the previous example. What can we notice?
After this demonstration, let us restore the original state of the Entity rule and regenerate the infrastructure.
Scoping defines which elements are referable by a given cross-reference. In our language, we want to
-
specify the Entities from which a certain Entity can inherit from, that is, we do not want to allow self-inheritance (isA reference of Entity), and
-
specify the (non-transient) Attributes that can be set as key in the scope of an Entity, that is, we do not want to allow the key reference to be set to the Attribute of another Entity (key reference of Entity).
For this, we have to extend the scope provider.
-
Open the scope provider:
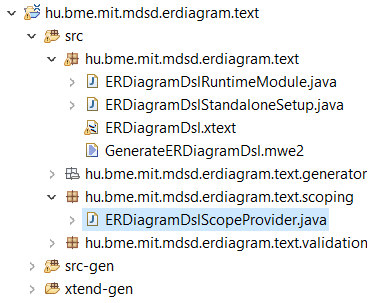
Note: This is a Java class (since the 2.19 Xtext release) created during the first generation of the infrastructure. Prior to the 2.19 Xtext release, (by default) an Xtend class was generated, and this option can still be manually set in the mwe2 workflow definition file. If you choose to work with Xtend classes, Java code will be generated from them under the xtend-gen source folder (further description of the language can be found here: http://eclipse.org/xtend/).
-
We have to override the
getScopemethod of the abstract superclass. Create the following method:
public class ERDiagramDslScopeProvider extends AbstractERDiagramDslScopeProvider {
public IScope getScope(EObject context, EReference reference) {
// Setting scope for the isA reference in Entity
if (context instanceof Entity && reference == ERDiagramDslPackage.Literals.ENTITY__IS_A) {
ERDiagram erDiagram = (ERDiagram) context.eContainer();
Collection<Entity> referrableEntities = new ArrayList<Entity>(erDiagram.getEntities());
referrableEntities.remove(context); // Removing itself
return Scopes.scopeFor(referrableEntities);
}
// Setting scope for the key reference in Entity
if (context instanceof Entity && reference == ERDiagramDslPackage.Literals.ENTITY__KEY) {
Entity entity = (Entity) context;
Collection<Attribute> referrableAttributes = new ArrayList<Attribute>(entity.getAttributes());
referrableAttributes.removeIf(it -> it.isIsTransient()); // Removing transient attributes
return Scopes.scopeFor(referrableAttributes);
}
return super.getScope(context, reference);
}
}This way the scope provider restricts the objects available as endpoints for the key and isA reference of the Entity EClass. Note that this way we ensure (although not too spectacularly) that isA relations can be specified only between Entities defined in the same ERDiagram model element - without such a restriction, Xtext also allows references across files (which can prove useful in other cases, but not here). The Scopes class contains static methods to create scope descriptions from a list of EObjects.
Check out the new scoping in our example (Runtime Eclipse, example.er file).
Static analysis is always required for any language. In this example, we raise an error if a cycle occurs in the inheritance graph of Entities.
-
Open the validator Java file (ERDiagramDslValidator.java).
-
A validation method for the given type requires the following things:
@Checkannotation, one parameter with the type that we want to validate and using theerror,warningorinfomethods to create markers on the editor.
public class ERDiagramDslValidator extends AbstractERDiagramDslValidator {
@Check
public void checkCyclicInheritance(Entity entity) {
checkCyclicInheritance2(entity, new HashSet<Entity>());
}
private void checkCyclicInheritance2(Entity entity, Set<Entity> entitiesAlreadyChecked) {
entitiesAlreadyChecked.add(entity);
for (Entity parent : entity.getIsA()) {
if (entitiesAlreadyChecked.contains(parent)) {
error("Cyclic inheritance is not allowed.", ERDiagramDslPackage.Literals.ENTITY__IS_A);
return;
}
checkCyclicInheritance2(parent, entitiesAlreadyChecked);
}
}
}Note: in a real project much more validation would be needed.
Check out in our example (Runtime Eclipse, example.er file).
Xtext supports automatic code generation when editing instance models. For this, we have to implement the doGenerate method in the ERDiagramDslGenerator.xtend Xtend class. Xtend provides template expressions, which support readable string concatenation and are very useful for writing code generators. In this example, we are going to generate SQL queries from the defined entity-relationship model that create a database schema according to (a restricted set of) object-relational mapping rules.
-
Open the ERDiagramDslGenerator.xtend file.
-
Create the following class:
class ERDiagramDslGenerator extends AbstractGenerator {
override void doGenerate(Resource resource, IFileSystemAccess2 fsa, IGeneratorContext context) {
val diagram = resource.contents.get(0) as ERDiagram
fsa.generateFile('er.sql', '''
«FOR entity : diagram.entities»
CREATE TABLE «entity.name» (
««« Only non-transient attributes are serialized
«FOR attribute : entity.allAttributes.reject[it.isTransient] SEPARATOR ', '»
«attribute.name» «attribute.type.transformType» «IF attribute === entity.key»PRIMARY KEY«ENDIF»
«ENDFOR»
);
«ENDFOR»
«FOR relation : diagram.relations»
CREATE TABLE «relation.name» (
«relation.leftEndingKey.name» «relation.leftEndingKey.type.transformType»,
CONSTRAINT fk_«relation.leftEndingKey.name» FOREIGN KEY («relation.leftEndingKey.name»)
REFERENCES «relation.leftEndingEntity.name»(«relation.leftEndingKey.name»),
«relation.rightEndingKey.name» «relation.rightEndingKey.type.transformType»,
CONSTRAINT fk_«relation.rightEndingKey.name» FOREIGN KEY («relation.rightEndingKey.name»)
REFERENCES «relation.rightEndingEntity.name»(«relation.rightEndingKey.name»)
);
«ENDFOR»
'''
)
}
// Note that in Xtend, methods can be called using the extension syntax:
// entity.getAllAttributes() or entity.allAttributes instead of getAllAttributes(entity)
private def Set<Attribute> getAllAttributes(Entity entity) {
val attributes = newHashSet
attributes += entity.attributes
for (parent : entity.isA) {
attributes += parent.allAttributes
}
return attributes
}
// Note that the return type specification of methods can be omitted if it can be automatically inferred from the method body
private def transformType(AttributeType type) {
switch (type) {
case AttributeType.BOOLEAN: {
return 'bit'
}
case AttributeType.DATETIME: {
return 'datetime'
}
case AttributeType.DOUBLE: {
return 'real'
}
case AttributeType.INT: {
return 'int'
}
case AttributeType.STRING: {
return 'varchar(255)'
}
}
}
// Note how property accessors can be used in Xtend: relation.name instead of relation.getName()
private def getName(Relation relation) '''«relation.leftEndingEntity.name»To«relation.rightEndingEntity.name»'''
private def getLeftEndingEntity(Relation relation) {
return relation.leftEnding.target
}
private def getLeftEndingKey(Relation relation) {
return relation.leftEndingEntity.key
}
private def getRightEndingEntity(Relation relation) {
return relation.rightEnding.target
}
private def getRightEndingKey(Relation relation) {
return relation.rightEndingEntity.key
}
}The terminals (« ») for interpolated expression are guillemets. They can be inserted within a template using content assist (Ctrl + Space). Note that Xtend supports extension syntax in the case of method calls, e.g., we can write relation.getName() instead of getName(relation). Additionally, property accessors can be called in an abbreviated form, e.g., relation.name can be written instead of relation.getName().
In the Runtime Eclipse, the modification of the example ERDiagram model automatically calls the doGenerate method, which generates the er.sql file.
Check out the result.

You may have noticed the model folder in the Xtext project, which contains an ecore and genmodel file generated from the grammar file. Xtext uses EMF under the hood. Xtext can also work with existing ecore models.
To make it work, we have to generate a new Xtext project along with a new grammar from the existing ecore model or change our grammar at the following two points: (1) instead of generate we have to import the ecore model and (2) rules must be accompanied with a returns <existing EClass>.
In this tutorial, we will generate a new language based on the erdiagram created in the previous laboratory practices and will highlight the differences.
-
Clone and check out any branch from this repository, then import the project with the erdiagram ecore model in it.
-
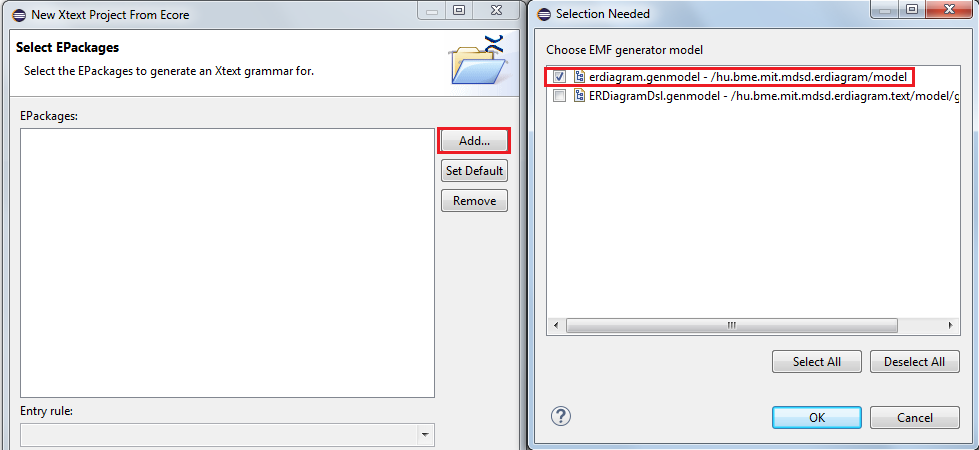
Create a new Xtext Project From Existing Ecore Models

-
Choose the existing ecore model and select the root element as the entry rule.
-
On the next page, we can give the project name, extension, etc. As for this tutorial, we can leave everything on default.
-
We may have to add Xtext nature to the
*.erdiagramproject. -
Examine the generated grammar (MyDsl.xtext). Header and entry rule:
// automatically generated by Xtext grammar org.xtext.example.mydsl.MyDsl with org.eclipse.xtext.common.Terminals import "hu.bme.mit.mdsd.erdiagram" import "http://www.eclipse.org/emf/2002/Ecore" as ecore EntityRelationDiagram returns EntityRelationDiagram: {EntityRelationDiagram} 'EntityRelationDiagram' name=EString '{' ('entities' '{' entities+=Entity ( "," entities+=Entity)* '}' )? ('relations' '{' relations+=Relation ( "," relations+=Relation)* '}' )?'}' )? ('temporalAttributes' '{' temporalAttributes+=Attribute ( "," temporalAttributes+=Attribute)* '}' )? '}' ;As can be seen, Xtext automatically generates a grammar based on the existing EClasses, their references and their attributes. However, the definition of models according to this generated syntax is cumbersome, therefore it is highly advised to customize it.
Let us examine the new constructions in a rule definition:
RuleName returns EClass: {RuleName} ... ;-
The name of the rule does not automatically represent the EClass that is generated during the parsing of the input file. The type of the instantiated object when applying this rule can be specified using the
returnskeyword. -
Sometimes Xtext can consume rules without object instantiation (this is always denoted by a warning). In order to ensure object creation, the following action has to be added: {RuleName}.
-
▶ Watch the video ▶ ▶ Watch the video ▶
- Detailed documentation: https://eclipse.org/Xtext/documentation/
- Debugging Xtext grammars: https://blogs.itemis.com/en/debugging-xtext-grammars-what-to-do-when-your-language-is-ambiguous