Pipeline
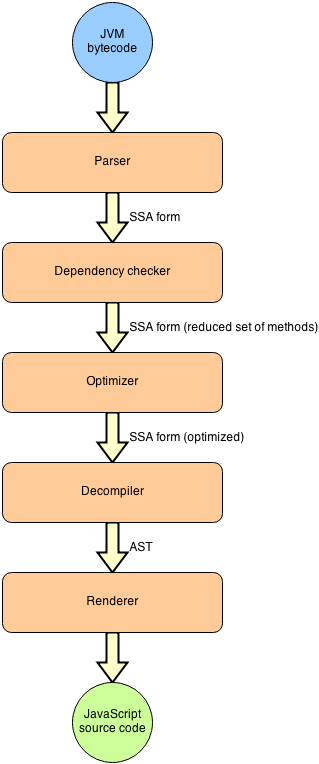
Parser gets .class files and produces intermediate representation, so called model.
TeaVM uses SSA form to represent code.
It uses standard algorithm to build SSA, based on
dominators and dominator frontiers.
The algorithm description is available in the
paper by R. Cytron et al.
The TeaVM implementation does not try to reduce the number of phi functions,
relying on further stages of pipeline.
TeaVM has a very smart dependency checker to cut off a large amount of unnecessary methods. Instead of checking class-to-class dependency, TeaVM tries to figure dependencies on method level. It is a little tricky thing to deal with virtual methods, as for each call site you have to know which implementations are available. So TeaVM uses idea, described in the paper by Vijay Sundaresan et al.
For each achievable method we build a data flow graph. When we meet an INVOKESTATIC or an INVOKEDYNAMIC, we mark callee as achievable and build its data flow graph the same way. After callee DFG is built, we connect caller and callee graphs the following way: for each parameter of the callee we add an edge, starting at the caller's variable which is passed to the callee's parameter. The edge must point at the callee's parameter itself. If the callee returns value, we also add an edge starting at the callee's return value and pointing to the caller's variable that receives the returning value.
For every NEW, LDC, ANEWARRAY we put class name to the instruction value receiver (i.e. variable which gets result of instruction execution). Then we propagate all the class names along DFG's edges. When we meet INVOKEVIRTUAL or INVOKEINTERFACE instructions, we search for the corresponding method implementation and build its DFG. We connect DFGs of methods according to variables passed by caller.
So we end up with a global data flow graph where each node represents a variable in some method. And for each variable we know a set of classes which achieve this variable. Of course, we always deal with false positive.
Optimizations are done in a standard way. TeaVM is planned to have all major optimizations such as inlining global value numbering, loop invariant motion and others. One of the most important optimization is de-virtualization, which requires dependency information and therefore is done at the previous stage.
Main article: Register allocation
JavaScript doesn't have physical registers as a CPU does. But we perform register allocation to reduce a number of variables, as SSA usually has a lot of them. We actually don't come out of SSA form. Instead we allocate registers in the way that for all of the phi's arguments and the phi result receiver the same registers are allocated. Of course, we sometimes have to introduce copies to make such allocation possible.
Main article: Decompilation
Decompiler takes SSA representation of a method and produces its AST that is ready to render into JavaScript code.