Sequence to Sequence – Deep Recurrent Neural Networks in CNTK – Part 1
by William Darling
In a previous post, I talked about the different paradigms of neural networks and how they can be nicely divided into 5 different categories. Andrej Karpathy's diagram is a great illustration of that paradigm:
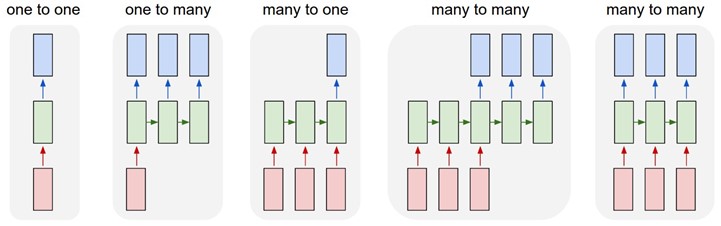
In that post, I talked in detail about sequence classification which fits the "many-to-one" paradigm. A sequence could be a query or a whole document or even a video, and the output is a single category. In that example I talked specifically about query classification and how knowing what type of question a user is asking can help us to know what to do with a query before trying to rank it.
In this post, I will talk about the next paradigm: "many-to-many". This category is represented by the now-well-known sequence-to-sequence model. The input is a sequence with a dynamic length, and the output is also a sequence with some dynamic length. It is the logical extension of the many-to-one paradigm in that previously we were predicting some category (which could easily be one of V words where V is an entire vocabulary) and now we want to predict a whole sequence of those categories.
The applications of sequence-to-sequence networks are nearly limitless. It is a natural fit for machine translation (e.g. English input sequences, French output sequences) [1]; automatic text summarization (e.g. full document input sequence, summary output sequence) [2]; word to pronunciation models (e.g. character [grapheme] input sequence, pronunciation [phoneme] output sequence) [3]; and even parse tree generation (e.g. regular text input, flat parse tree output) [4]. In this post, I will talk about the theory of sequence-to-sequence networks, their application in CNTK, some example models that we've built or helped to build, and finish off with some best practices. In future posts, I will talk about models and results in more detail, and share more code such as the sequence-to-sequence model application in Python running on CNTK 2.
Quick aside: before we talk about the basic theory behind a sequence-to-sequence network, it's worth noting how game-changing this architecture really is. In countless domains, researchers have been applying the basic "vanilla" sequence-to-sequence network to complex problems that have been studied for years and automatically getting state-of-the-art results. It's almost unfair! For example, machine translation has been worked on since at least the 1950's and extremely specific and complex approaches have been developed to squeeze out every last bit of quality improvement along the way. [1] shows that a basic s2s network goes beyond the state-of-the-art without any special MT adaptations. The same thing for parsing; [4] mentions that parsing is a "fundamental problem in NLP and has been the subject of intensive research and engineering for decades". Nevertheless, the basic s2s network achieves results beyond the state-of-the-art. Same thing for text summarization [2]. The only question is what domain will be turned on its head next.
A sequence-to-sequence model consists of two main pieces: (1) an encoder; and (2) a decoder. Both the encoder and the decoder are recurrent neural network (RNN) layers that can be implemented using a vanilla RNN, an LSTM, or GRU cells. The encoder processes the input sequence into a fixed representation that is fed into the decoder as a context. The decoder then uses some mechanism (discussed below) to decode the processed information into an output sequence. The decoder is a language model that is augmented with some "strong context" by the encoder, and so each symbol that it generates is fed back into the decoder for additional context (like a traditional LM). For an English to German translation task, the most basic setup might look something like this:

As you'll remember from a previous post, an RNN such as an LSTM has a state. It takes some input (such as a word), updates its hidden state, and then computes some output vector (in an LSTM or a GRU it computes a few other things but in the end it can be thought of as a black box: it still has a hidden state and an output). One of the amazing things about sequence-to-sequence networks (and RNNs in general) is how much information ends up being stored in the hidden state of an RNN after properly training it and passing through a sequence of data. The encoder passes on its final hidden state to the decoder and this hidden state is often referred to as a "thought vector". One of the original deep learning researchers, Geoffrey Hinton, is quite fond of the idea of thought vectors and how they are poised to revolutionize AI [etc, etc].
The basic sequence-to-sequence network passes the information from the thought vector to the decoder by initializing the decoder RNN with the thought vector as its hidden state. The input is then a "sequence start" tag ("<s>" in the diagram above) which primes the decoder to start generating an output sequence. Then, whatever word (or note or image, etc.) it generates at that step is fed in as the input for the next step. The decoder keeps generating outputs until it hits the special "end sequence" tag ("</s>" above). If you prefer symbols, a traditional language model only has some window of previous words as its context and therefore generates (or "predicts") the next word following a distribution like this:
p(wt | wt-1, … , w1)
which has to be simplified to some lower n-gram level due to training data sparsity and model complexity, etc to be something like this (tri-gram model):
p(wt | wt-1, … , w1) ≈ p(wt | wt-1, wt-2)
So there are two problems. The first is that the amount of context is limited, and the second is the type of context is limited. A traditional LM only knows about the words that came before, but nothing about the "idea" or the "topic" or "question" at hand. This makes them good for some things, but not good (especially on their own) for generating text. A sequence-to-sequence model, though, not only has more previous words as context, but it also has a thought vector. So, each word can be generated following this much richer distribution:
p(wt | wt-1, … , w1, h)
where h is our thought vector (it's a little bit simplified above because h is updated each time-step in the decoder but you get the idea).
While the above setup works well, it can start to break down when the input sequences get long. At each step, the hidden state h is getting updated with the most recent information, and therefore h might be getting "diluted" in information as it processes each token. Further, even with a relatively short sequence, the last token will always get the last say and therefore the thought vector will be somewhat biased/weighted towards that last word. To deal with this problem, we use an "attention" mechanism. The attention mechanism allows the decoder to put different amounts of attention on all of the hidden states produced by the encoder and use whatever information it most needs for the current element that it is predicting!
More specifically, an attention vector is computed at each output time t over the input words. We compute a vector ut with length T (where there are T elements in the input sequence) and the i-th entry contains a score telling how much attention should be put on the i-th hidden state of the encoder hi:
u(i, t) = vT tanh(W1 hi + W2 dt)
where v, W1, and W2 are learnable parameters of the network and dt is the (original) hidden state of the decoder at time t.
In addition to using attention, there are a number of other ways to extend and improve the performance of the basic sequence-to-sequence network. First, like any deep neural network, adding layers is always a great idea! For example, we might have a stack of 3 LSTM layers for the encoder and another 3 LSTM layers for the decoder. Another well-known NN trick that can help S2S networks is to use a word-embedding. Instead of passing one-hot vectors of words into the encoder, passing the vector representation of the word almost always helps. For this, one can use either a pre-trained embedding such as the GloVe vectors, or, an embedding can be learned for your specific task by setting it as a parameter of the model (look out for over-fitting though because you've just vastly increased the number of learnable parameters).
Finally, while it's not an "extension", we also need a way to intelligently make use of the information from the decoder to get the best possible output sequences. While we could simply take a greedy approach and output the most probable word at each step, this rarely leads to a globally optimal decoding. While the most probable word to start a sentence given some thought vector might be "the", and the second most probable given "the" might be "most", a more globally optimal solution might find out that two different words, "today in", are more probable than "the most", even though "the" was more probable alone than "today". The best decoding would be one that considers every single combination at each step. However, that is generally computationally intractable. Instead, we use a beam search decoder with a given depth. The depth parameter considers how many best candidate solutions to keep around at each step. This results in a heuristic for the global optimal that works quite well. Indeed, a beam search of 3 gives very good results in most situations.
To get started with sequence-to-sequence networks in CNTK, you can start with the built-in example "G2P". You can find it in <cntk>/Examples/SequenceToSequence/CMUDict/Config/G2P.cntk. This is an implementation of a general sequence-to-sequence model but it has its parameters setup, and the data is included, for the grapheme-to-phoneme problem described in [3]. There are a number of self-explanatory parameters that can be set before you start training. For example, hiddenDim is the dimension of the hidden states in your encoder and decoder. Some other important ones:
- maxLayer is the number (starting from 0, sorry) of the layers of encoders and decoders
- isBidirectional is a Boolean indicating if your encoder is unidirectional (runs backward by default) or bidirectional (runs forward and backward and combines the result)
- maxLength sets the maximum length of your input sequences and is required for the attention window
- inputVocabSize and labelVocabSize are obvious (often we use the same vocab but it can be useful to have separate vocabs for a task like translation)
For the most part, the rest can be kept as defaults (besides setting your training data, etc.) and then refine things like the learning rate and the mini-batch sizes through iterating…
Once you have a trained model, it's time to decode some input sequences! To do so, you again invoke cntk with the G2P.cntk config file but pass in the option "command=write" (which will replace the default "command=train"). You also need to set "decodeModel=N" where N is the saved model you're interested in using (corresponds to the epoch number in question) and "beamDepth=3" for more-or-less optimal decoding (you can also try beamDepth=1 for greedy decoding to see the difference). One important note is that the decoder is setup to be used for a network that does not include an embedding. Therefore, if you have used an embedding, you need to make one slight change to your CNTK.core.bs file to take the embedding into account. There is a line in the function BeamSearchSequenceDecoderFrom that sets up the feedback for the next time step in the network (remember that the decoder takes both the general "thought vector" context and as input the token that it just emitted). Instead of passing in a one-hot vector representation of that token, you need to turn that representation into its embedded form. To do so, simply change
decoderFeedback = /*EmbedLabels*/ (tokens.word) # [embeddingDim x Dnew]
to
decoderFeedback = TransposeTimes(Elabels, tokens.word)
While sequence-to-sequence networks can provide very impressive results across a number of domains, it is important to know some best practices to be able to use them well (in some cases if you just use all the defaults you might be disappointed with your results). Here are some hints and rules of thumb that we've come up with from working with these models over the past little while, especially if you're coming to CNTK from TensorFlow to see what all the fuss is about (in terms of great distributed training, for example):
- In TF the default seq2seq network automatically cuts sequences to a maximum of length=50; in the G2P.cntk example, there is just a network – all pre-processing needs (for now) to be done yourself
- Regarding attention: the TF model knows that the max length is 50 so the attention window is automatically set to be 50. In the G2P example maxLength needs to be set to whatever you made your max sequence length to be during pre-processing
- Minibatch sizes: in the TF seq2seq network a batch (default=64) is a tuple of sequences regardless of how long they are (though they seem to do padding so you can almost infer exactly how big each MB is on a per-sample basis except that they have a couple of different buckets of sizes to pad to). In CNTK the minibatch size is measured in samples (e.g. words). In fact, it is whatever the maximum number of samples is in your source or target sequence for seq2seq. So, to convert to CNTK you would multiply the TF batch number by the average sequence length (more or less)
- Learning rates: in TF the default learning rate is 0.5 but this is for the whole minibatch. Something like w <w – 0.5 * average_(gradients)… But in the G2P example and elsewhere in CNTK we're normally using learningRatesPerSample so for each sample (word in the output sequence in seq2seq) we'd apply that weight of change. So, the equivalent would be something like 64 / (minibatch_size * avg label length) = learningRatesPerSample… In general, if you're using "gradUpdateType = FSAdaGrad" (which you should be using), learning rates per sample on the order of 0.003 should work well.
- Use a lot of data! One very rough rule of thumb is that the "size" of parameters in your network should be on the order of the "size" of your training data. If your training data is much bigger than your network complexity then you might not be able to have a network that is expressive enough to capture the interesting connections. Conversely, if your network complexity is much greater than the size of your training data, you are liable to vastly over-fit; your network will be great at predicting exactly what is in your training data, but it won't be good at generalizing to unseen examples.
[1] Cho, et al. "Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation", arXiv:1406.1078 [cs.CL], 3 June 2015.
[2] Nallapati, "Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond", arXiv:1602.06023 [cs.CL], 19 February 2016.
[3] Yao and Zweig, "Sequence-to-Sequence Neural Net Models for Grapheme-to-Phoneme Conversion", arXiv:1506.00196 [cs.CL], 31 May 2015.
[4] Vinyals, et al. "Grammar as Foreign Language", arXiv:1412.7449 [cs.CL], 9 June 2015.