English | 简体中文
![]()
![]()
在这里,我们提供了一些可以运行的Jupyter* notebooks,用于学习和尝试使用OpenVINO™开发套件。这些notebooks旨在向各位开发者提供OpenVINO基础知识的介绍,并教会大家如何利用我们的API来优化深度学习推理。

查看最新notebooks代码示例,了解如何在英特尔CPU和GPU上优化和部署最近流行的深度学习模型。
| Notebook | 描述 | 预览 | 补充资料 |
|---|---|---|---|
| YOLOv8 - Optimization |
利用 NNCF PTQ API 优化 YOLOv8 |  |
博客 - 如何用OpenVINO™让YOLOv8获得1000+ FPS性能? |
| SAM - Segment Anything Model |
使用 Segment Anything以及OpenVINO™进行基于提示的对象分割掩码生成 |  |
博客 - AI分割一切——用OpenVINO™加速Meta SAM大模型 |
| ControlNet - Stable-Diffusion |
利用ControlNet条件和OpenVINO™进行文本到图像生成 |  |
Blog - Control your Stable Diffusion Model with ControlNet and OpenVINO |
| Stable Diffusion v2 |
利用Stable Diffusion v2 以及 OpenVINO™进行文本到图像生成和无限缩放 |  |
博客 - AI作画升级,OpenVINO™ 和英特尔独立显卡助你快速生成视频 |
| Whisper - Subtitles generation |
利用OpenAI Whisper以及OpenVINO™为视频生成字幕 | 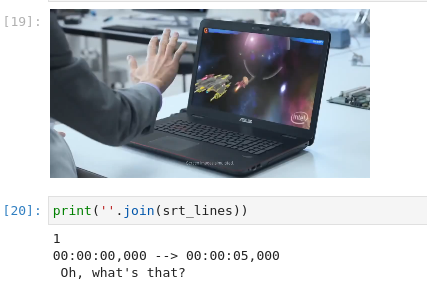 |
|
| CLIP - zero-shot-image-classification |
利用CLIP 以及 OpenVINO™执行零样本图像分类 | 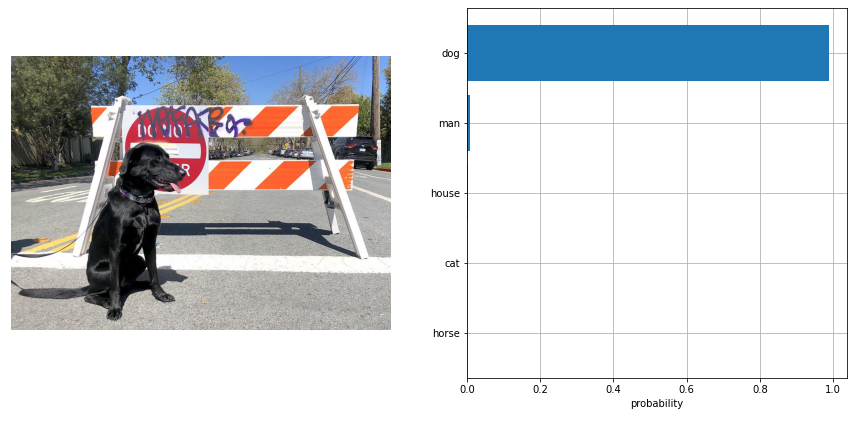 |
Blog - Generative AI and Explainable AI with OpenVINO |
| BLIP - Visual-language-processing |
利用BLIP以及OpenVINO™进行视觉问答和图像字幕 |  |
Blog - Multimodality with OpenVINO — BLIP |
| Instruct pix2pix - Image-editing |
利用InstructPix2Pix进行图像编辑 | < |
Blog - Generative AI and Explainable AI with OpenVINO |
| DeepFloyd IF - Text-to-Image generation |
利用DeepFloyd IF以及OpenVINO™进行文本到图像生成 |  |
|
| ImageBind |
使用ImageBind以及OpenVINO™结合多模态数据 |  |
|
| Dolly v2 |
使用Databricks Dolly 2.0以及OpenVINO™遵循指令进行文本生成 |  |
|
| Stable Diffusion XL |
使用Stable Diffusion XL以及OpenVINO™实现图像生成 |  |
|
| MusicGen |
使用MusicGen以及OpenVINO™实现可控音乐生成 |  |
|
| Tiny SD |
使用Tiny-SD以及OpenVINO™实现图像生成 |  |
|
| ZeroScope Text-to-video synthesis |
使用ZeroScope 和 OpenVINO™进行文字到视频生成 | A panda eating bamboo on a rock  |
|
| LLM chatbot |
基于OpenVINO™的大语言模型聊天机器人 |  |
|
| Bark Text-to-Speech |
使用Bark 和 OpenVINO™进行文本到语音转换 |  |
|
| LLaVA Multimodal Chatbot |
基于LLaVA和 OpenVINO™的视觉语言助手 | ||
| BLIP-Diffusion - Subject-Driven Generation |
使用BLIP Diffusion和 OpenVINO™实现基于主题驱动的图像生成和修改 |  |
|
| DeciDiffusion |
使用DeciDiffusion 和 OpenVINO™进行图像生成 |  |
|
| Fast Segment Anything |
使用FastSAM 和 OpenVINO™进行快速目标分割 |  |
|
| SoftVC VITS Singing Voice Conversion |
基于OpenVINO™实现SoftVC VITS 演唱声音转换 | ||
| Latent Consistency Models: the next generation of Image Generation models |
使用潜在一致性模型以及 OpenVINO™实现高速图像生成 |  |
|
| QR Code Monster |
使用ControlNet QR Code Monster 和 OpenVINO™生成创意二维码 |  |
|
| Würstchen |
基于Würstchen 和 OpenVINO™实现文本到图像生成 |  |
|
| Distil-Whisper |
基于Distil-Whisper 和 OpenVINO™实现自动语音识别 | ||
| FILM |
使用FILM 和 OpenVINO™实现视频插帧 |  |
- 🚀 AI 趋势 - Notebooks
- 目录
- 📝 安装指南
- 🚀 开始
- ⚙️ 系统要求
- ⚙️ System Requirements
- 💻 运行Notebooks
- 🧹 清理
⚠️ 故障排除- 🧑💻 贡献者
- ❓ 常见问题解答
OpenVINO Notebooks需要预装Python和Git, 针对不同操作系统的安装参考以下英语指南:
| Windows | Ubuntu | macOS | Red Hat | CentOS | Azure ML | Docker | Amazon SageMaker |
|---|
Jupyter notebooks 分为四个大类,选择一个跟你需求相关的开始试试吧。祝你好运!
演示如何使用OpenVINO的Python API进行推理的简短教程。
| 001-hello-world |
002-openvino-api |
003-hello-segmentation |
004-hello-detection |
|---|---|---|---|
| 使用OpenVINO进行图像分类 | 学习使用OpenVINO Python API | 使用OpenVINO进行语义分割 | 使用OpenVINO进行文本检测 |
 |
 |
 |
 |
解释如何使用OpenVINO工具进行模型优化和量化的教程。
| Notebook | Description |
|---|---|
| 101-tensorflow-classification-to-openvino |
转换 TensorFlow模型为OpenVINO IR |
| 102-pytorch-to-openvino |
转换PyTorch模型为OpenVINO IR |
| 103-paddle-to-openvino |
转换PaddlePaddle模型为OpenVINO IR |
| 104-model-tools |
从Open Model Zoo进行模型下载,转换以及进行基线测试 |
| 105-language-quantize-bert | 优化及量化BERT预训练模型 |
| 106-auto-device |
演示如何使用AUTO设备 |
| 107-speech-recognition-quantization |
优化及量化预训练Wav2Vec2语音模型 |
| 108-gpu-device | 在GPU上使用OpenVINO™ |
| 109-performance-tricks | OpenVINO™ 的优化技巧 |
| 110-ct-segmentation-quantize |
量化肾脏分割模型并展示实时推理 |
| 111-yolov5-quantization-migration |
在神经网络压缩框架(NNCF)上迁移基于YOLOv5 POT API的量化管道 |
| 112-pytorch-post-training-quantization-nncf | 利用神经网络压缩框架(NNCF)在后训练模式下来量化PyTorch模型(无需模型微调) |
| 113-image-classification-quantization |
量化mobilenet图片分类模型 |
| 115-async-api |
使用异步执行改进数据流水线 |
| 116-sparsity-optimization |
提高稀疏Transformer模型的性能 |
| 117-model-server | OpenVINO模型服务(OVMS)介绍 |
| 118-optimize-preprocessing | 提升图片预处理性能 |
| 119-tflite-to-openvino |
TensorFlow Lite 模型转换为OpenVINO IR |
| 120-tensorflow-object-detection-to-openvino |
TensorFlow目标检测模型转换为OpenVINO IR |
| 121-convert-to-openvino |
学习OpenVINO模型转换API |
| 122-quantizing-model-with-accuracy-control | 使用NNCF工具实现精度感知量化 |
| 123-detectron2-to-openvino |
将Detectron2 转换到 OpenVINO IR |
| 124-hugging-face-hub |
使用OpenVINO™加载Hugging Face Model Hub模型 |
| 125-torchvision-zoo-to-openvino Classification Semantic Segmentation |
将torchvision 分类和语义分割模型转换为OpenVINO IR |
| 126-tensorflow-hub |
将TensorFlow Hub 模型转换到OpenVINO IR |
演示对特定模型的推理。
| Notebook | Description | Preview |
|---|---|---|
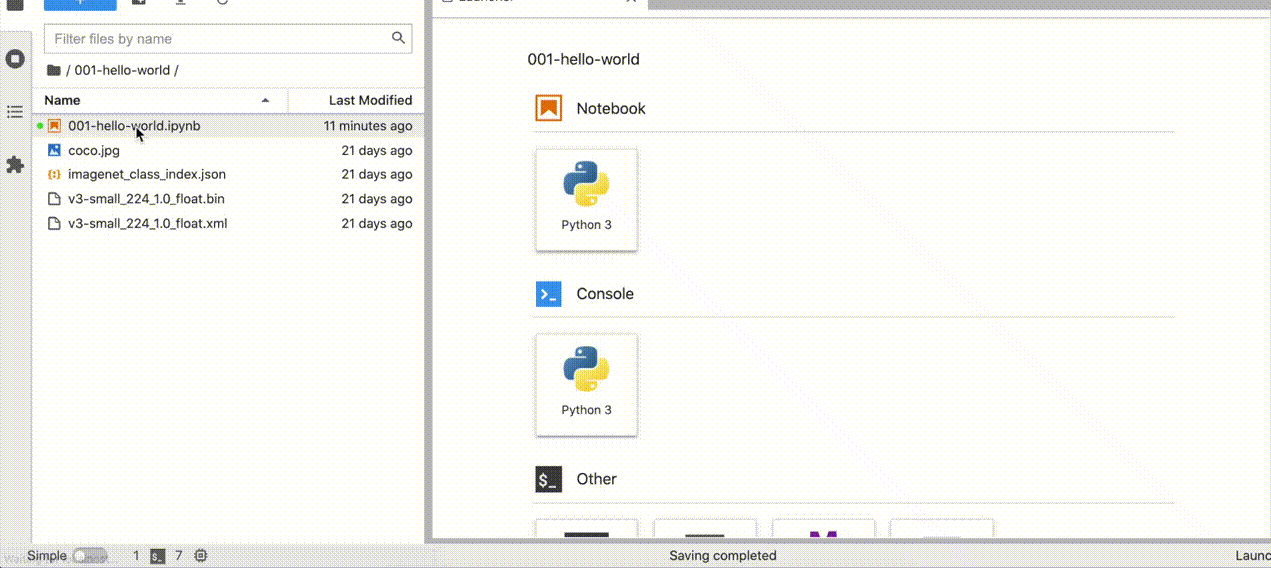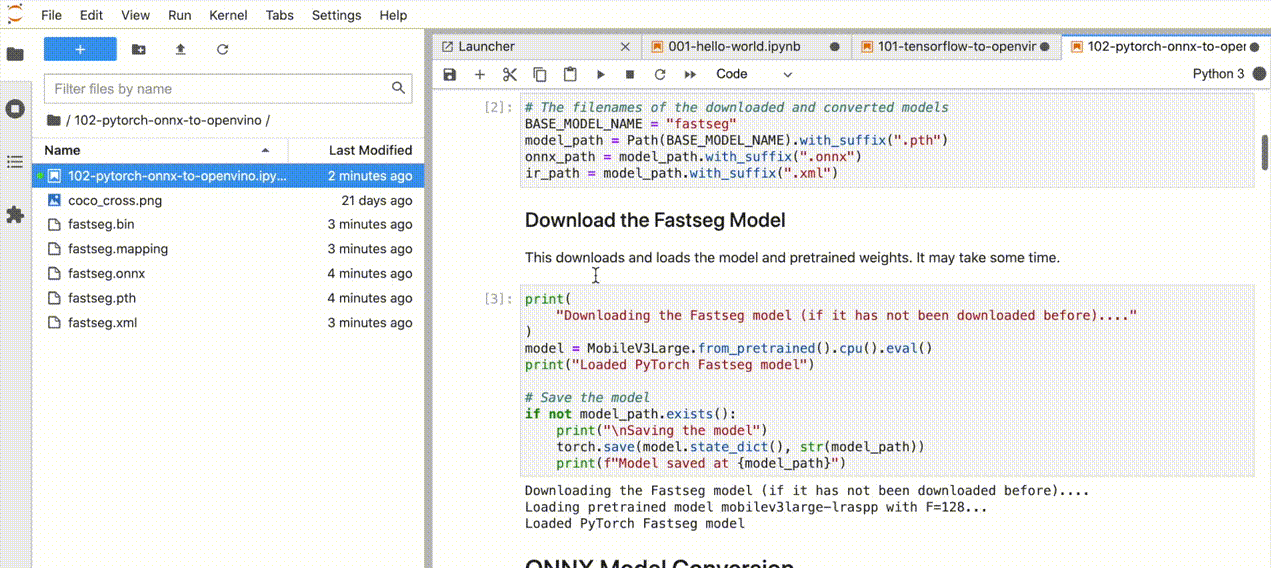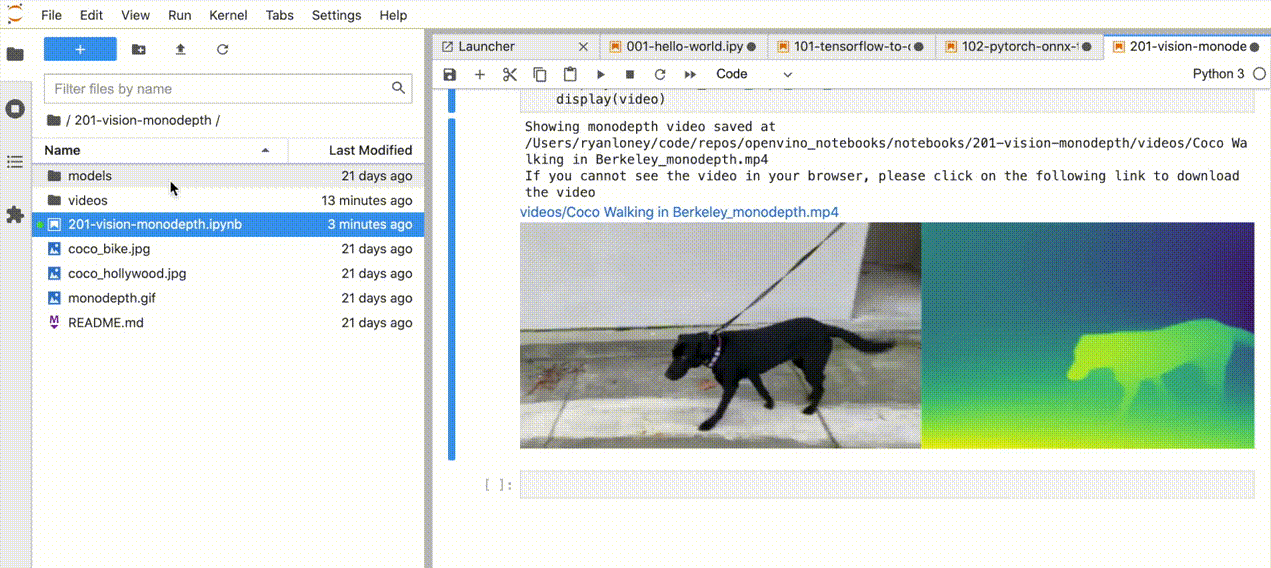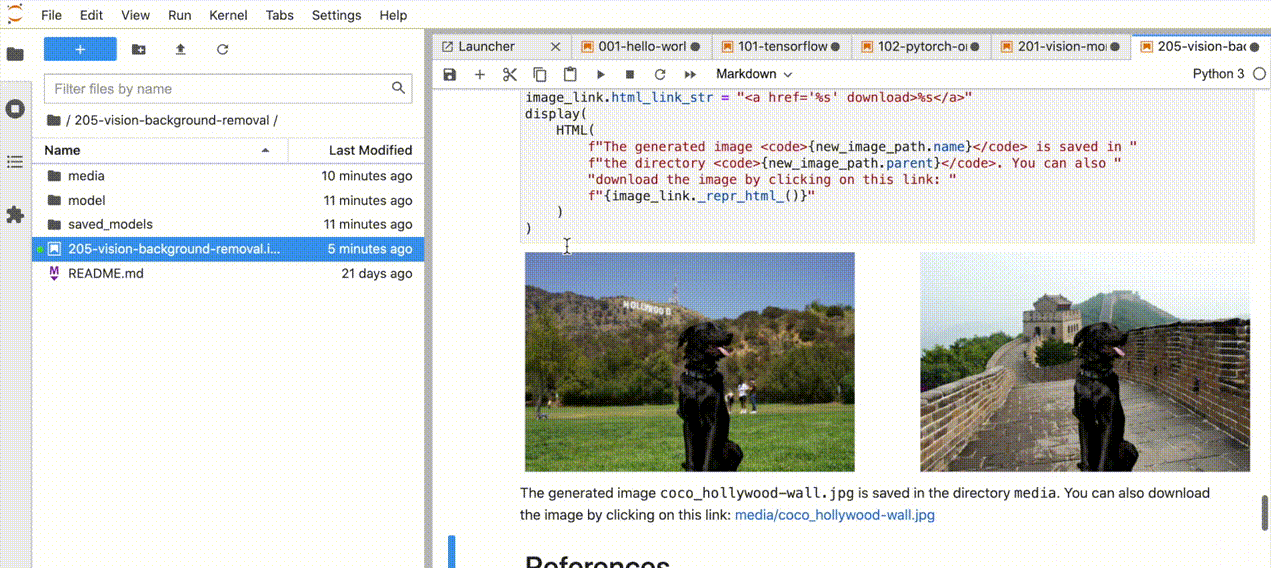
| 201-vision-monodepth |
利用图像和视频进行单目深度估计 |  |
| 202-vision-superresolution-image |
使用超分辨率模型放大原始图像 |  → → |
| 202-vision-superresolution-video |
使用超分辨率模型将360p视频转换为1080p视频 |  → → |
| 203-meter-reader |
PaddlePaddle预训练模型读取工业表计数据 |  |
| 204-segmenter-semantic-segmentation |
基于OpenVINO使用Segmenter的语义分割™ |  |
| 205-vision-background-removal |
使用显著目标检测移除并替换图像中的背景 |  |
| 206-vision-paddlegan-anime |
使用GAN把图片变为动画效果 |  → → |
| 207-vision-paddlegan-superresolution |
使用PaddleGAN模型以超分辨率放大小图像 | |
| 208-optical-character-recognition |
使用文本识别resnet对图像上的文本进行注释 |  |
| 209-handwritten-ocr |
手写体中文及日文OCR |  的人不一了是他有为在责新中任自之我们 |
| 210-slowfast-video-recognition |
使用SlowFast以及OpenVINO™进行视频识别 |  |
| 211-speech-to-text |
运行语音转文本模型的推理 |  |
| 212-pyannote-speaker-diarization |
在speaker diarization管道上运行推理 |  |
| 213-question-answering |
基于上下文回答问题 | 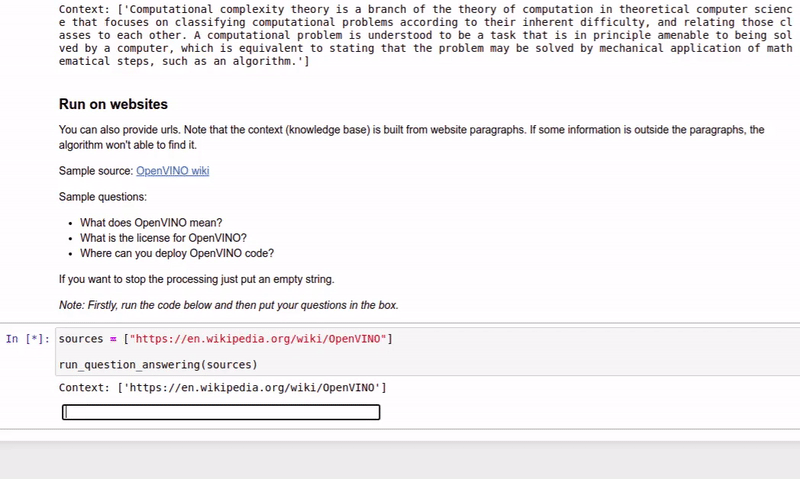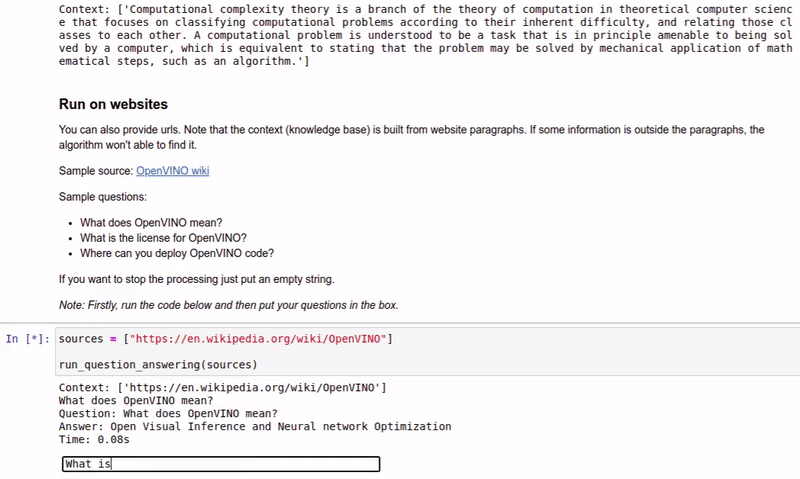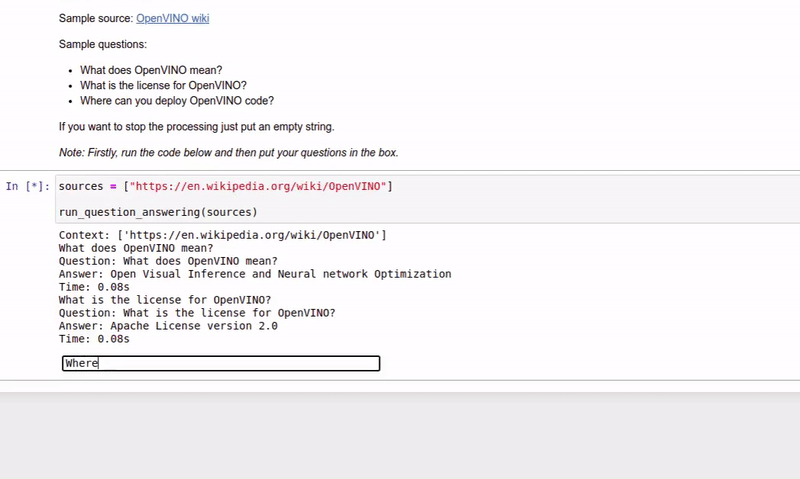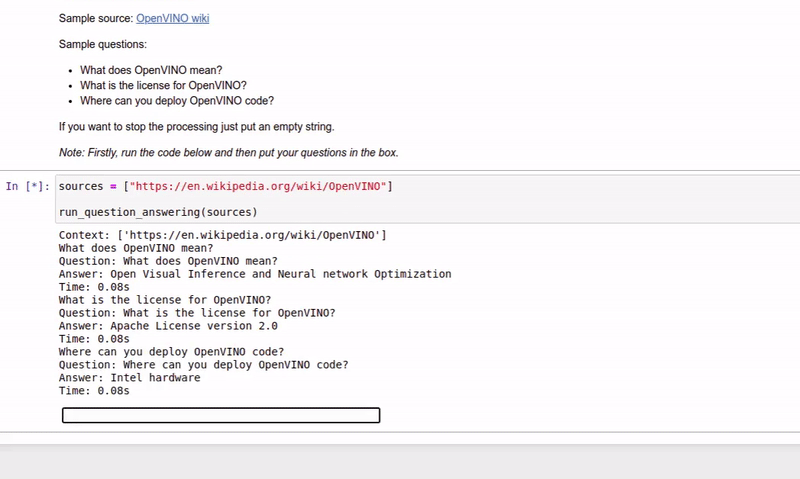 |
| 214-grammar-correction | 使用OpenVINO进行语法错误纠正 | input text: I'm working in campany for last 2 yeas Generated text: I'm working in a company for the last 2 years. |
| 215-image-inpainting |
用绘画中的图像填充缺失像素 |  |
| 216-attention-center |
在attention center模型上使用OpenVINO™ | |
| 217-vision-deblur |
使用DeblurGAN-v2去除图像模糊 |  |
| 218-vehicle-detection-and-recognition |
利用OpenVINO及预训练模型检测和识别车辆及其属性 |  |
| 219-knowledge-graphs-conve |
使用OpenVINO优化知识图谱嵌入模型(ConvE) | |
| 221-machine-translation |
从英语到德语的实时翻译 | |
| 222-vision-image-colorization |
使用OpenVINO及预训练模型对黑白图像染色 |  |
| 223-text-prediction |
使用预先训练的模型对输入序列执行文本预测 |  |
| 224-3D-segmentation-point-clouds |
使用OpenVINO处理点云数据并进行3D分割 |  |
| 225-stable-diffusion-text-to-image |
用Stable Diffusion由文本生成图像 |  |
| 226-yolov7-optimization |
使用NNCF PTQ API优化YOLOv7 |  |
| 227-whisper-subtitles-generation |
利用OpenAI Whisper及OpenVINO为视频生成字幕 | |
| 228-clip-zero-shot-image-classification |
利用CLIP及OpenVINO进行零样本图像分类 | |
| 229-distilbert-sequence-classification |
利用OpenVINO进行句子分类 |  |
| 230-yolov8-optimization |
使用NNCF PTQ API优化YOLOv8 | |
| 231-instruct-pix2pix-image-editing |
利用InstructPix2Pix进行图像编辑 | |
| 232-clip-language-saliency-map |
基于CLIP和OpenVINO™的视觉语言显著性检测 |  |
| 233-blip-visual-language-processing |
基于BLIP和OpenVINO™的视觉问答与图片注释 | |
| 234-encodec-audio-compression |
基于EnCodec和OpenVINO™的音频压缩 |  |
| 235-controlnet-stable-diffusion |
使用ControlNet状态调节Stable Diffusion 实现文字生成图片 | |
| 236-stable-diffusion-v2 |
利用Stable Diffusion v2 以及 OpenVINO™进行文本到图像生成和无限缩放使用 | |
| 237-segment-anything |
使用 Segment Anything以及OpenVINO™进行基于提示的对象分割掩码生成 | |
| 238-deep-floyd-if |
利用DeepFloyd IF以及OpenVINO™进行文本到图像生成 | |
| 239-image-bind |
利用ImageBind以及OpenVINO™结合多模态数据 | |
| 240-dolly-2-instruction-following |
使用Databricks Dolly 2.0以及OpenVINO™遵循指令生成文本 | |
| 241-riffusion-text-to-music |
使用Riffusion以及OpenVINO™进行文本到音乐生成 |  |
| 242-freevc-voice-conversion |
利用FeeVC和OpenVINO™实现高质量的无文本一次性语音转换 | |
| 243-tflite-selfie-segmentation |
使用TFLite以及OpenVINO™实现Selfie分割方案 |  |
| 244-named-entity-recognition |
使用OpenVINO™进行命名实体识别 | |
| 245-typo-detector |
使用OpenVINO™进行英文文本纠错 |  |
| 246-depth-estimation-videpth |
使用OpenVINO™进行基于视觉的单目深度估测 |  |
| 247-code-language-id |
Identify the programming language used in an arbitrary code snippet | |
| 248-stable-diffusion-xl |
使用Stable Diffusion X以及OpenVINO™实现图像生成 | |
| 249-oneformer-segmentation |
使用OneFormer以及OpenVINO™实现通用分割任务 |  |
| 250-music-generation |
使用MusicGen以及OpenVINO™实现可控音乐生成 | |
| 251-tiny-sd-image-generation |
使用Tiny-SD以及OpenVINO™实现图像生成 | |
| 252-fastcomposer-image-generation |
使用ZeroScope 和 OpenVINO™进行文字到视频生成 | |
| 253-zeroscope-text2video |
Text-to-video synthesis with ZeroScope and OpenVINO™ | A panda eating bamboo on a rock |
| 254-llm-chatbot |
基于OpenVINO™的大语言模型聊天机器人 | |
| 255-mms-massively-multilingual-speech |
MMS: 使用OpenVINO™将演说技术扩展到1000种语言以上的支持 | |
| 256-bark-text-to-audio |
使用Bark 和 OpenVINO™进行文本到语音转换 | |
| 257-llava-multimodal-chatbot |
基于LLaVA和 OpenVINO™的视觉语言助手 | |
| 258-blip-diffusion-subject-generation |
使用BLIP Diffusion和 OpenVINO™实现基于主题驱动的图像生成和修改 | |
| 259-decidiffusion-image-generation |
使用DeciDiffusion 和 OpenVINO™进行图像生成 | |
| 260-pix2struct-docvqa |
使用Pix2Struct 和 OpenVINO™实现基于文档视觉的问答 |  |
| 261-fast-segment-anything |
使用FastSAM 和 OpenVINO™进行快速目标分割 | |
| 262-softvc-voice-conversion |
基于OpenVINO™实现SoftVC VITS 演唱声音转换 | |
| 263-latent-consistency-models-image-generation |
使用潜在一致性模型 and OpenVINO™实现高速图像生成 | |
| 264-qrcode-monster |
使用ControlNet QR Code Monster 和 OpenVINO™生成创意二维码 | |
| 265-wuerstchen-image-generation |
基于Würstchen 和 OpenVINO™实现文本到图像生成 | |
| 266-speculative-sampling |
基于推测性抽样, KV Caching, 和 OpenVINO™的文本生成任务 |  |
| 267-distil-whisper-asr |
基于Distil-Whisper 和 OpenVINO™实现自动语音识别 | |
| 268-table-question-answering |
使用TAPAS 和 OpenVINO™面向表格文件进行问答 | |
| 269-film-slowmo |
使用FILM 和 OpenVINO™实现视频插帧 | |
包含训练神经网络代码的教程。
| Notebook | Description | Preview |
|---|---|---|
| 301-tensorflow-training-openvino | 从TensorFlow训练花朵分类模型,然后转换为OpenVINO IR |  |
| 301-tensorflow-training-openvino-pot | 使用POT量化花朵模型 | |
| 302-pytorch-quantization-aware-training | 使用神经网络压缩框架(NNCF)量化PyTorch模型 | |
| 305-tensorflow-quantization-aware-training |
使用神经网络压缩框架(NNCF)量化TensorFlow模型 |
在网络摄像头或视频文件上运行的实时推理演示。
| Notebook | Description | Preview |
|---|---|---|
| 401-object-detection-webcam |
使用网络摄像头或视频文件进行目标检测 |  |
| 402-pose-estimation-webcam |
使用网络摄像头或视频文件进行人体姿态估计 |  |
| 403-action-recognition-webcam |
使用网络摄像头或视频文件进行动作识别 |  |
| 404-style-transfer-webcam |
使用网络摄像头或视频文件进行样式变换 |  |
| 405-paddle-ocr-webcam |
使用网络摄像头或视频文件进行OCR |  |
| 406-3D-pose-estimation-webcam |
使用网络摄像头或视频文件进行3D人体姿态估计 |  |
| 407-person-tracking-webcam |
使用网络摄像头或视频文件进行人体跟踪 |  |
如果你遇到了问题,请查看故障排除, 常见问题解答 或者创建一个GitHub discussion。
带有 按键的Notebooks可以在无需安装的情况下运行。Binder 是一项资源有限的免费在线服务。 如果享有获得最佳性能体验,请遵循安装指南在本地运行Notebooks。
这些notebooks可以运行在任何地方,包括你的笔记本电脑,云VM,或者一个Docker容器。下表列出了所支持的操作系统和Python版本。
| 支持的操作系统 | Python Version (64-bit) |
|---|---|
| Ubuntu 20.04 LTS, 64-bit | 3.8 - 3.10 |
| Ubuntu 22.04 LTS, 64-bit | 3.8 - 3.10 |
| Red Hat Enterprise Linux 8, 64-bit | 3.8 - 3.10 |
| CentOS 7, 64-bit | 3.8 - 3.10 |
| macOS 10.15.x versions or higher | 3.8 - 3.10 |
| Windows 10, 64-bit Pro, Enterprise or Education editions | 3.8 - 3.10 |
| Windows Server 2016 or higher | 3.8 - 3.10 |
如果你希望启动单个的notebook(如:Monodepth notebook),运行以下命令:
jupyter 201-vision-monodepth.ipynbjupyter lab notebooks在浏览器中,从Jupyter Lab侧边栏的文件浏览器中选择一个notebook文件,每个notebook文件都位于notebooks目录中的子目录中。
-
停止Jupyter Kernel
按 Ctrl-c 结束 Jupyter session,会弹出一个提示框 Shutdown this Jupyter server (y/[n])? 输入 y 并按 回车。
-
注销虚拟环境
注销虚拟环境:只需在激活了 openvino_env 的终端窗口中运行 deactivate 即可。
重新激活环境:在Linux上运行 source openvino_env/bin/activate 或者在Windows上运行 openvino_env\Scripts\activate 即可,然后输入 jupyter lab 或 jupyter notebook 即可重新运行notebooks。
-
删除虚拟环境 (可选)
直接删除 openvino_env 目录即可删除虚拟环境:
-
On Linux and macOS:
rm -rf openvino_env
-
On Windows:
rmdir /s openvino_env
-
从Jupyter中删除
openvino_envKerneljupyter kernelspec remove openvino_env
如果以下方法无法解决您的问题,欢迎创建一个discussion topic 或issue!
- 运行 python check_install.py 可以帮助检查一些常见的安装问题,该脚本位于openvino_notebooks 目录中。 记得运行该脚本之前先激活 openvino_env 虚拟环境。
- 如果出现 ImportError ,请检查是否安装了 Jupyter Kernel。如需手动设置kernel,从 Jupyter Lab 或 Jupyter Notebook 的_Kernel->Change Kernel_菜单中选择openvino_env内核。
- 如果OpenVINO是全局安装的,不要在执行了setupvars.bat或setupvars.sh的终端中运行安装命令。
- 对于Windows系统,我们建议使用_Command Prompt (cmd.exe),而不是_PowerShell。